
ビジネスインテリジェンスやデータサイエンスでデータを利活用しようとしても、元となるデータの品質が悪いと、データ解析の信頼性が担保できません。
データ品質とは、データがどれだけ信頼できるかを表すもので、DMBOKには、主に次のような指標で評価することができると説明されています。
関連記事
データマネジメントの導入方法
- 正確性
データが現実の実体を正しく表している程度を表す。 - 完全性
必要なデータが全て存在しているかどうか、その程度を表す。 - 一貫性
データが、特定のデータベースなどデータセット内で一貫して(正しいルールに貫かれて)表現されているか、あるいは、データセット間で一貫して関連付けられ、一貫して表現されているか、その程度を表す。
一貫性は、1レコード内にある属性値と別の属性値との間(レコードレベルの一貫性)、あるレコードの属性値と別のレコードの属性値の間(クロスレコードの一貫性)、あるレコードの属性値と異なる時点における同じレコードの属性値との間(経時的一貫性)において定義される。
参照キーを介したデータセット間の一貫性(例えば参照先のデータだけがないという欠落がない)を参照整合性という。 - 一意性
同じ実体を表すデータが同じデータセット内に複数存在していないか、その程度を表す。 - 適時性
データが適切な時点のものであるか、その程度を表す。
データが発生して利用可能になるまで遅延する場合、遅延の程度によってデータの可用性を定義することによって、データの適時性を判断することができる。 - 有効性
データが定義域に準拠しているか、その程度表す。
データの定義域とはデータドメインといい、データの型、形式、範囲、ルールなどで定義された、データがとり得る全体を表す。
ここでは、データマネジメントプロセスの一環として、データ品質を管理するプロセスを次の順で解説します。
データ品質の設計
データ品質は、データマネジメントプロセスの「データアーキテクチャ設計プロセス」の流れの中で設計されます。
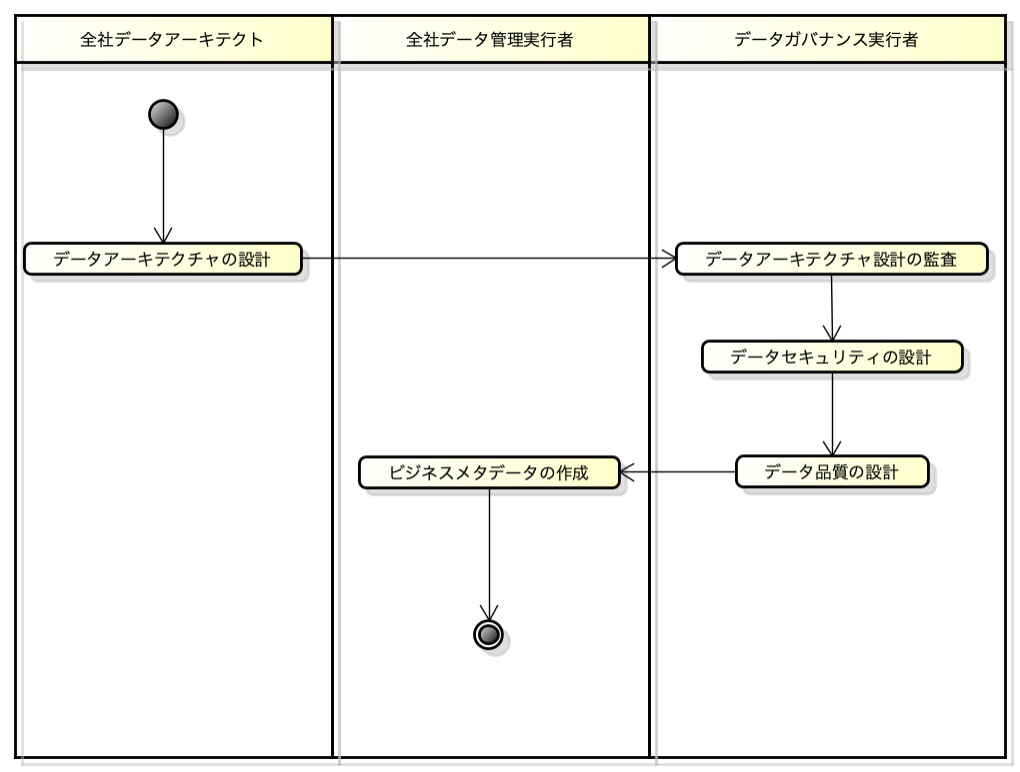
データ品質の設計手順は次のようになります。
データ品質ポリシーの定義
データ品質ポリシーは、データマネジメントポリシーの一環として定義されるもので、「基本方針」、「対策基準」、「実施手順」の3つの階層で構成されます。
基本方針には、組織や企業の代表者による「なぜデータ品質の維持・向上が必要であるのか」や「どのような方針でデータ品質を考えるのか」といった宣言が含まれます。
対策基準には、実際にデータ品質の維持・向上対策の指針を記述します。多くの場合、対策基準にはどのような対策を行うのかという一般的な規定のみを記述します。
実施手順には、それぞれの対策基準ごとに、実施すべきデータ品質の維持・向上対策の内容を具体的に手順として記載します。
データ品質基準の定義
データの品質評価指標、ビジネスルール、品質測定方法、品質評価基準を定義します。
データのビジネスルールとは、組織内でデータが有用で利用できるためにはどうあるべきかを表すもので、データの品質評価指標と整合させて定義します。
データのビジネスルールのタイプ
- 定義の適合性
データの定義に対する理解と実装が統一されるべきだというルール。
例えば、計算フィールドのアルゴリズムや親子ステータスの相互依存性のルールなど。 - 値の存在とレコードの完全性
欠損値が許容される許容されないかの条件を定義するルール。 - 書式遵守
データに指定される書式に関するルール。
電話番号書式の標準など。 - 値ドメインに含まれる項目
データに指定される列挙された値(列挙型)のルール。 - 範囲の適合性
データの指定される範囲のルール。
0より大きく100より小さいなど。 - マッピングの適合性
データが異なるデータドメインで表現できる場合、そのマッピングが適切であるためのルール。 - 一貫性ルール
データがデータセット内で一貫して(正しいルールに貫かれて)表現される、、あるいは、データセット間で一貫して関連付けられるためのルール。 - 正確性の検証
データが正式記録システム(SoR)や他の検証済みソースデータに一致することを検証するルール。 - 一意性の検証
どのエンティティが一意性を満たさなければならないか指定し検証するルール。 - 適時性の検証
データが適時アクセス可能であることを検証するルール。
データ利用者がデータのレイテンシをどの程度許容できるのかデータニーズとして把握し、それを品質評価基準(許容値)として設定する。
データのレイテンシ
ソースシステムでデータが生成されてからターゲットシステムでデータが利用可能になるまでの時間差。

データ品質管理実施手順の定義
データ品質管理実施手順の例は次のようになります。
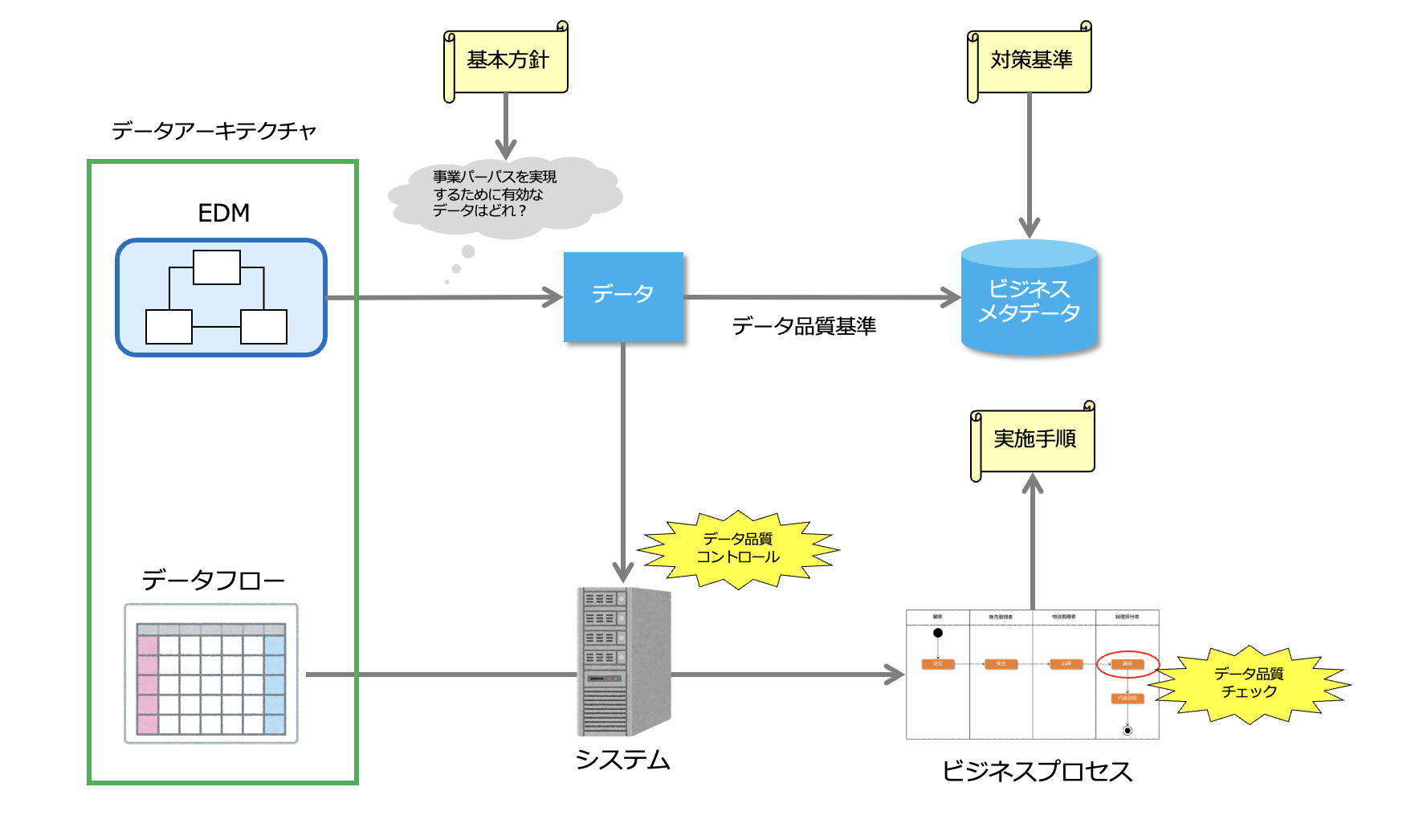
- データアーキテクチャのEDM(エンタープライズデータモデル)をベースに事業パーパスを実現するために有効なデータを選定する
マスターデータは全て事業パーパスを実現するために有効なデータですが以下のようなケースもあります。
例えば、顧客からの問い合わせやクレームのデータは、商品の改善や新商品の開発に有効なデータです。
それが「問い合わせ対応」アクティビティで取得されるのであれば、「問い合わせ対応」のときデータ正確に、かつ、完全に記録されているか検証する必要があります(データ品質指標が正確性や完全性の場合)。
また、事業のKPIがLTV(顧客生涯価値)だったとします。
LTVは事業パーパスの実現度合いを確認するために重要な指標です。
LTV=(顧客単価×粗利率×購買頻度×取引期間)-(顧客の獲得・維持コスト)で算定します。
顧客単価=顧客別売上高/顧客別購買回数で算定します。
なので、顧客別売上高や顧客別購買回数は重要なデータ項目です。
それらが「受注」アクティビティでカウントされるのであれば、「受注」のときデータが正確に、かつ、完全に記録されているか検証する必要があります(データ品質指標が正確性や完全性の場合)。 - そのデータに対して、データマネジメントポリシーの対策基準で定義されたデータ品質基準を設定し、ビジネスメタデータとしてデータカタログに登録する
- データアーキテクチャのデータフローから上記データのライフサイクルに関係するビジネスプロセスと、データを管理するシステムを明確にする
- データを管理するシステムの機能要件として、データ品質を確保するためのUIバリデーションやデータ制約を定義する(下記データ設計の検証でチェックされる)
- データのライフサイクルに関係するビジネスプロセスで、実際にデータのライフサイクルに関わるアクティビティ(データの生成・取得、変換・蓄積、利用、破棄)に対するデータ品質検証手順(データのプロファイリング方法)を、データマネジメントポリシーの実施手順(Procedure)として定義する(下記データ生成・取得の検証などでチェックされる)
データ品質計画の策定
データマネジメントプロセスの「データマネジメント計画の策定」の一環として設計されます。
データ設計の検証
データ設計の内容は、データマネジメントプロセスの「データ設計の検証」の流れの「データモデルの検証」および「アプリケーション処理の検証」で確認します。
以下、データ品質における問題と原因の例を示します。
データ設計が原因で発生する問題
データ設計が原因で発生する問題の例を示します。
- 参照整合性制約の不備
参照整合性制約に不備がある場合、存在しないデータの参照など、データ品質上の問題が発生する可能性があります。 - 一意性制約の不備
一意性制約に不備がある場合、データが一意であることを想定しているテーブルに同じデータが複数存在するなど、データ品質上の問題が発生する可能性があります。 - 不正確なプログラミングが生む間違い
不正確なプログラミングがあると、計算方法が間違っていたり、データが不適切なフィールド、キーに割り当てられたり、間違った参照先にリンクされたりし、データ品質上の問題が発生する可能性があります。 - データモデルの誤り
データモデル内に設けられた前提と、実際のデータが異なる場合、実際のデータがフィールド長を超えたため一部失われたり、データが不適切なIDやキーに割り当てられたりするなど、データ品質上の問題が発生する可能性があります。 - フィールドの多目的利用
様々な目的でフィールドを利用すると、紛らわしい値、不明瞭な意味、誤ってキーを割り当てるなど、データ品質上の問題が発生する可能性があります。 - 時系列データの不一致
複数のシステムで異なる日付形式や時間形式が実装されると、システム間でデータの同期が行われるととデータの不一致やデータの損失が発生するなど、データ品質上の問題が発生する可能性があります。 - 脆弱なマスターデータ管理
マスターデータに問題があると、信頼できないデータソースが採用されデータ品質上の問題が発生する可能性があります。 - データの重複
データの統合などデータマネジメントに不備があると次のような問題が発生します。
例えば、同じデータベース内の複数テーブルに同じ顧客を表すデータがある場合、どちらのデータが正確であることを知るのが困難になります。
また、複数のシステムから連携される単一の顧客データを処理する場合、重複が発生する可能性があります。
データ入力で発生する問題
データ入力で発生する問題の例を示します。
- データ入力インターフェースの問題
データ入力インターフェースに不正なデータがシステムに書き込まれることを防ぐための編集機能や制御が有効でない場合、データ品質上の問題が発生する可能性があります。 - リストエントリーの順序
ドロップダウンリスト内に表示される値の順序などがデータ入力エラーの原因となる可能性があります。 - フィールドの多重使用
時間の経過とともに異なる業務目的で同じフィールドを利用する可能性があります。 - トレーニングの問題
入力プロセスの知識が不足していると、プログラムで入力の制御や編集が行われていても、誤ったデータが入力されてしまう可能性があります。 - 業務プロセスの変更
新しいビジネスルールが導入された場合、それがシステムに反映されず、データ品質上の問題が発生する可能性があります。 - 一貫性のない業務プロセスの実行
一貫性のない業務プロセスが一貫性のないデータを生成する原因になる可能性があります。
データ処理機能の稼働中に発生する問題
データソースに関する誤った知識、陳腐化したビジネスルール、変更されたデータ構造が原因で、データ処理機能の稼働中に、データ品質上の問題が発生する可能性があります。
問題の修正により発生する問題
データ構造やプログラムの修正によってデータ品質上の問題が発生する可能性があります。
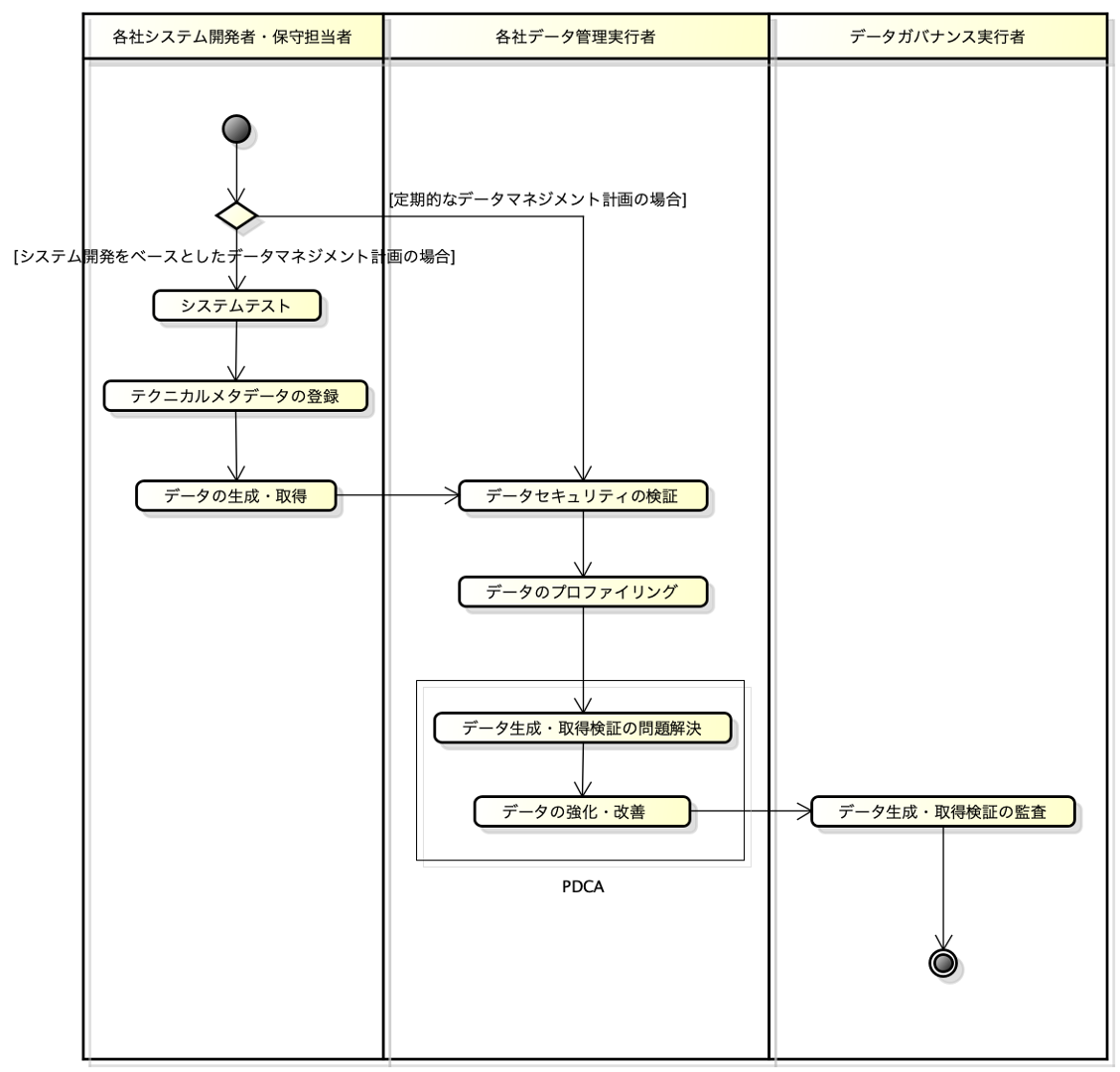
データ品質の検証
データマネジメントプロセスの「データマネジメントの実施」プロセスの一環として実行される、データ品質のプロファイリングです。
※例えば、データマネジメントプロセスの「データ生成・取得の検証」を参照してください。
データプロファイリング
データプロファイリングは、データを検査し、品質を評価するために行われるデータ分析の一形式です。
データプロファイリングは、統計的手法を活用して、収集したデータの真の構造、コンテンツ、品質を洗い出します。
以下に例を示します。
- NULL数
NULLが存在することを検出し、許容可能かどうかを検査できるようにする。 - 最大値・最小値
マイナス値などの異常値を検出する。 - 最大長・最小長
特定の桁数要件を持つフィールドの外れ値や異常値を検出する。 - 個々のカラムに存在する値の度数分布
トランザクション内の国コード分布、値の発生頻度検査、初期値が設定されているレコードの割合など値の妥当性を評価する。 - データタイプとフォーマット
小数点以下の桁数、スペースの混入などフォーマット要件への不適合レベル。
データ品質の改善方法
ここでは、データ品質管理のPDCAのAct(改善)で行う方法について説明します。
データクレンジング
データクレンジング(データの洗浄)やスクラブ(データエラーを取り除くこと)は、データをデータ標準や対象のビジネスルールに準拠させるためにデータを変換します。
データクレンジングは、コストがかかる上、修正による問題の発生などリスクも伴います。
なので、次のような対策を行い、できるだけデータクレンジングの必要性を減らす必要があります。
- データ入力エラーを防止する制御の実装
- ソースシステムのデータ修正
- データを生成するビジネスプロセスの改善
データの強化
次の例のようにデータを強化することで品質を上げることができます。
データの強化はビジネスメタデータとして設定することができます。
- 時間・日付スタンプ
データ品質に問題が発生した場合、問題が発生した時間帯を分離できるため、データの生成、更新、破棄された日時を履歴として記録するようにします。 - データ監査
監査により履歴の追跡と検証のために重要なデータリネージュを記録することができます。 - 参照用語
業界固有の用語も含めた用語集を整備することにより、データに対する理解と統制が強化されます。 - コンテキスト情報
データに対するレビューと分析をするために、場所、環境、アクセス方法、データのタグなどコンテキスト情報をデータに付加します。 - 地理情報
住所の標準化と位置座標化によって地理情報を強化することができます。 - 人口統計情報
顧客データは、年齢など人口統計情報によって強化することができます。 - 心理学的情報
商品やブランドの嗜好など心理学的情報で顧客データを強化することで市場をセグメント化することができます。 - 評価情報
資産評価、在庫管理、販売促進には、この種の属性を拡張することで強化することができます。
データの構文解析と書式設定
データ構文解析とは事前定義されたルールを利用して、データの内容や価値を定義するためのプロセスです。
これにより、データアナリストは、一連のパターンを定義でき、有効値と無効値を区別するために利用可能なルールエンジン(特定のパターンに一致すると処理が自動的に起動される)にそれを設定することができます。
データ変換と標準化
データ品質計画の検証
データマネジメントプロセスの「データマネジメント計画の検証」の一環として検証されます。
データ品質計画の改善
データマネジメントプロセスの「データマネジメント計画の改善」の一環として改善されます。

[…] データ品質の設計 データ品質の設計を参照してください。 […]
[…] システム品質の一部としてデータの信頼性やセキュリティに関する要件も定義します。 […]
[…] 情報は、組織の全てのレベルでリスクを識別、評価、対応し、さらには事業体を運営し、その目的達成のために必要です。 なので、的確な情報を収集、捕捉、加工、分析し、報告するにいたるデータライフサイクル全体を渡ってデータ価値、品質、セキュリティを管理するデータマネジメントの導入は重要です。 特に、適切な情報が、適切な形式かつ適切な詳細度で、適切な人に適時に行き渡らせるようにすることを確実にするデータ品質や、データセキュリティの管理は重要です。 […]
[…] 450;期的に実施します。 データのプロファイリングも参照してくださいz […]
[…] データドリブン経営によって利活用されるデータは、データプロファイリングによって評価され、データクレンジングやデータ強化などの方法で改善、強化されます。 […]
[…] 2540;タ管理基盤上のデータをプロファイリングしてデータ品質を検証し| […]
[…] 件 データマネジメントのデータ品質評価項目で管理されるデータ品質& […]
[…] データ品質保証条件 データマネジメントのデータ品質評価項目で管理されるデータ品質を保証するための条件です。 例えば、集約(エンティティ)が関連するエンティティの一意性や […]
[…] ットシステムでデータが利用可能になるまでの時間差のことをレイテンシといいます。 データの品質を測る指標の一つのデータの適時性があり、レイテンシをどの程度許容できるか、つ […]
[…] 展開します。 その際、業務概念データモデルのビジネスメタデータとして定義されたデータ品質要件やビジネス上のデータ要件を満たす業務論理データモデルを設計します。 次の図は、 […]