
5Gが普及すると、ますます、IoTなどにより発生するビッグデータを、AIを活用してビジネスに活かすことが当たり前になってきます。
データは21世紀の石油と言われています。
「稼ぐ力を持つ資産としてのデータをどうマネジメントしていくか」ということが、会社を発展させるための重要な課題になってきました。
今回は、
- DMBOKとは何か知りたいという方
- データを体系的にマネジメントするとはどういうことか知りたいという方
- DXを推進する一環としてデータマネジメントを学びたいという方
を対象に、データを体系的にマネジメントするために必要な知識体系DMBOKについて以下の観点で解説します。
- DMBOKとは何か
- データ及びデータベースの分類
- データの設計
- データの統合と相互運用
- データの利活用
- データ品質の管理とメタデータ
- データのリスク管理とデータセキュリティ
- データガバナンス
- 関連動画
DMBOKとは何か
DMBOK(ディンボック)とはData Management Body Of Knowledge(データマネジメント知識体系)の略で、データマネジメントに関する知識を体系立ててまとめた書籍のことです。
データマネジメントとは、
データ資産の価値を提供、維持向上させるためにデータライフサイクルを通して計画、実施、監督すること
です。
※データライフサイクル
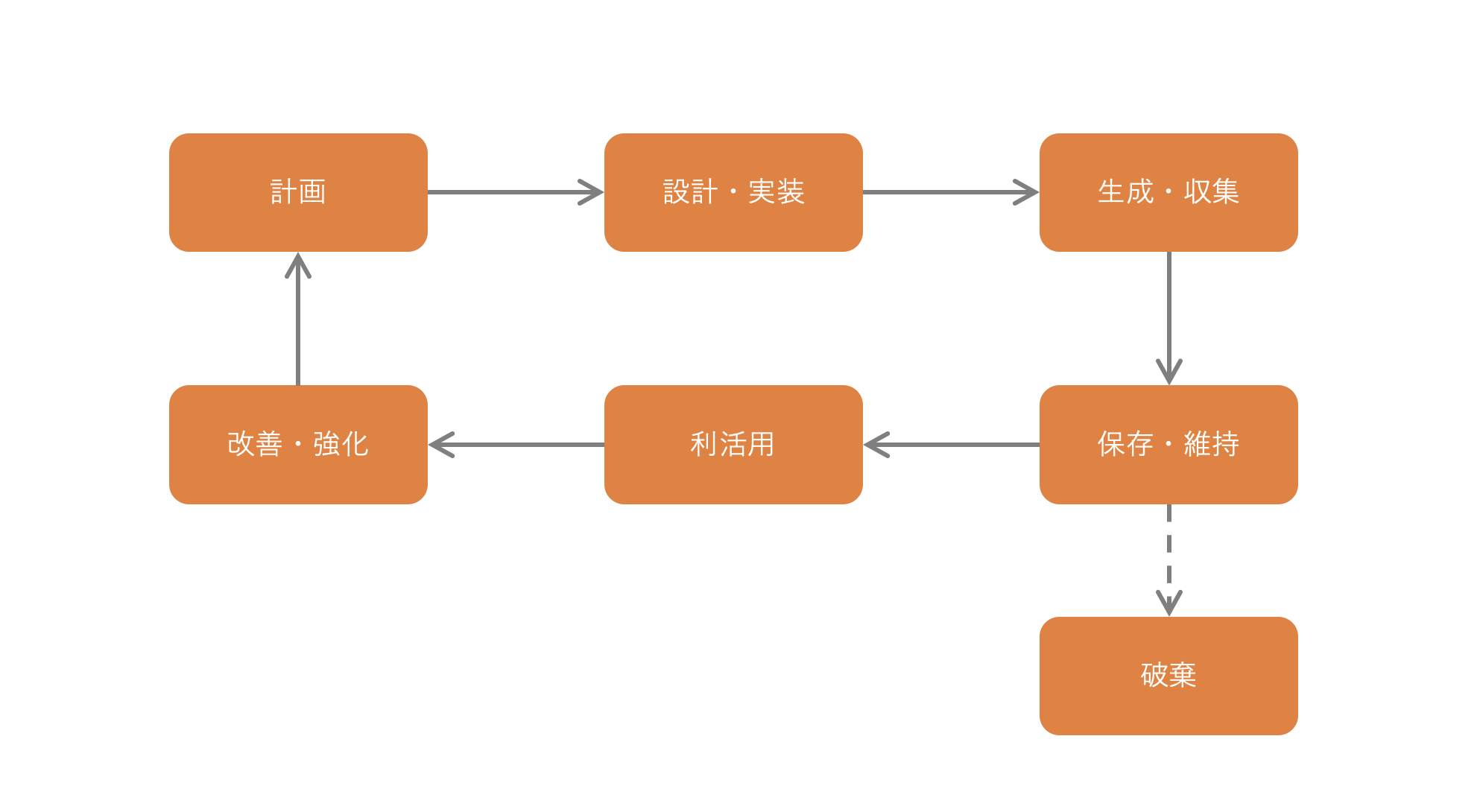
なお、データ資産の価値ですが、QCD(品質・コスト・納期)という観点で考えると、
- データの品質を上げる
- データ利活用のコストを下げる
- データ利活用のスピードを上げる
ことで資産としての価値を上げることができます。
さて、プロジェクトマネジメント知識体系、PMBOK(Project Management Body Of Knowledge)は有名ですが、そのデータマネジメント版と考えていただいても結構です。
DMBOKは、米国DAMA(Data Management Association)インターナショナルに所属する120名を超えるデータマネジメントの専門家によって書かれました。
初版は2009年に出版されましたが、2018年にデータマネジメント知識体系 第二版(DMBOK2)が出版されました。
データマネジメント知識体系ガイド 第二版
※
データに関する世界標準の知識がすべて網羅されているので1冊持っておくとカタログとして使えます。

DMBOK2の章立ては以下のようになっています。
第1章 データマネジメント
第2章 データ取扱倫理
第3章 データガバナンス
第4章 データアーキテクチャ
第5章 データモデリングとデザイン
第6章 データストレージとオペレーション
第7章 データセキュリティ
第8章 データ統合と相互運用性
第9章 ドキュメントとコンテンツ管理
第10章 参照データとマスターデータ
第11章 データウェアハウジングとビジネスインテリジェンス
第12章 メタデータ管理
第13章 データ品質
第14章 ビッグデータとデータサイエンス
第15章 データマネジメント成熟度アセスメント
第16章 データマネジメント組織と役割期待
第17章 データマネジメントと組織の変革
これは、DMBOKを構成する以下の11の知識領域をベースに組み立てられています。
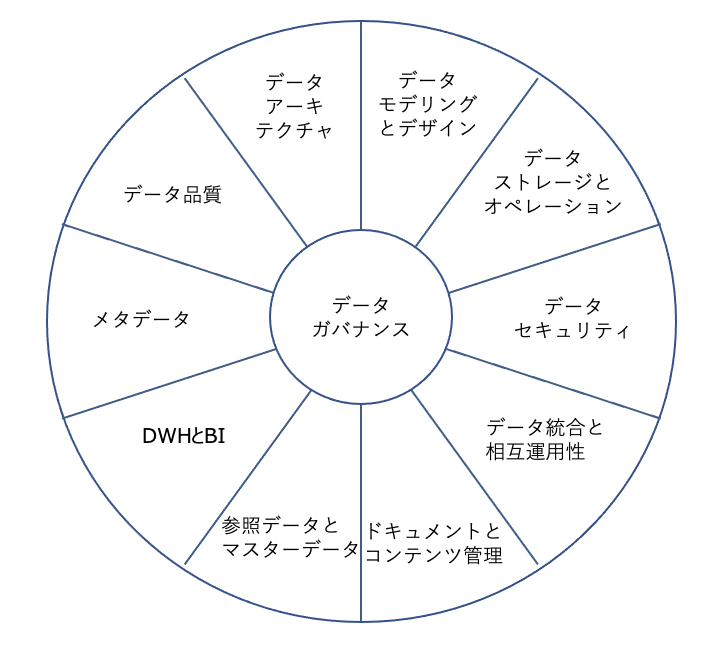
- データガバナンス
企業のニーズを考慮し、データにまつわる意思決定権の体系を確立し、それによってデータマネジメントの方向性を決め、監督する。 - データアーキテクチャ
データ資産管理のブループリントを定義すること。
データアーキテクチャは、戦略的データ要件と、その設計を確立する。 - データモデリングとデザイン
データモデルという明確な形式でデータの要件を洗い出し、分析し、表現し、伝達するプロセス。 - データストレージとオペレーション
データの価値を最大化するため、保存データを設計、実装、サポートすること。 - データセキュリティ
データのプライバシーと機密性を保ち、データを侵略から守り、適切なアクセスを確保する。 - データ統合と相互運用
データストア、アプリケーション、組織などの内部またはその間を移動し、統合されるデータに関するプロセス。 - ドキュメントとコンテンツ管理
非構造メディア、特に法律や規制に準拠するための文書など、そこに含まれるデータや情報のライフサイクル管理のための計画、実装、統制活動。 - 参照データとマスターデータ
最も正確で、鮮度が高く、関連が深い事実が重要なビジネスエンティティに対してシステム間で一貫し取り扱われるように、重要な共有データを継続的に照合・保守する方法。 - データウェアハウジングとビジネスインテリジェンス
意思決定を支えるデータを管理し、ナレッジワーカーがデータ分析やレポートを通してデータから価値を得られるようにすること。 - メタデータ
高品質で統合されたメタデータをアクセス可能にするための計画、実装、統制の活動。 - データ品質
組織内で利用されるデータの適性を測定し、評価し、改善するための品質管理技術の計画と遂行。
さて、DMBOKではデータマネジメントのフレームワークを以下のように表しています。
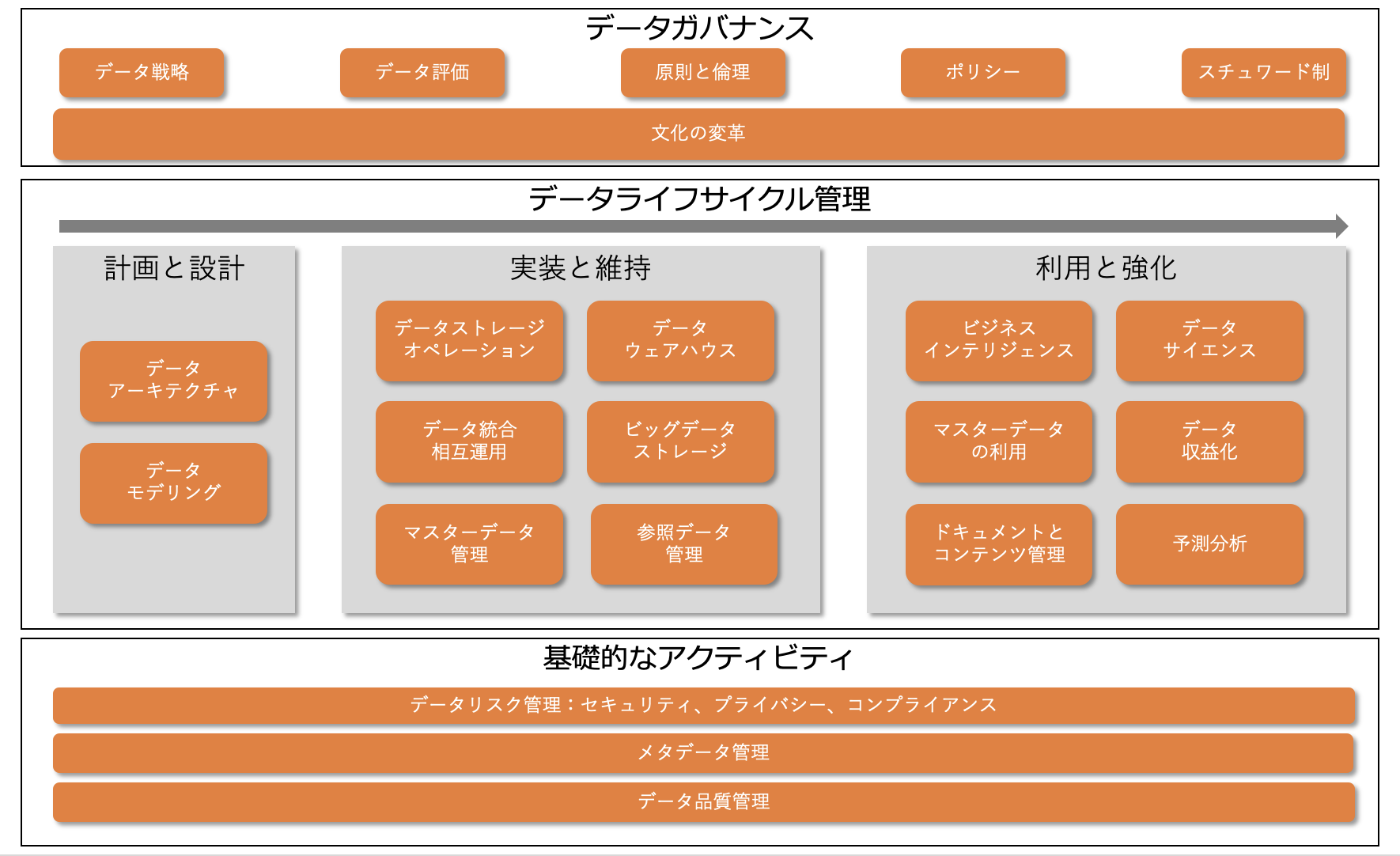
図:データマネジメント機能フレームワーク 出典:データマネジメント知識体系 第二版
このフレームワークを構成する考え方を一つ一つ見ていきましょう。
データ及びデータベースの分類
ここでは、データと、それを管理するIT基盤の部分であるデータベースを分けて考えます。
データの分類
まず、データは構造化データと非構造化データに分けることができます。
構造化データはさらに以下のように分類することができます。
データベースの分類
DMBOKでは、データベースを、よりハードウェアに近い部分の仕組と、アプリケーションに近い部分の仕組に分け、それぞれ
データベースアーキテクチャ
データベース構成
と表しています。
それぞれ見ていきましょう。
データベースアーキテクチャ
データベースアーキテクチャは大きく以下のように分けることができます。
- 集中型データベース
単一システム内で使うすべてのデータを一箇所にまとめて管理しているデータベース。
データが一箇所に集中しているため管理しやすいが、集中管理されたシステムが利用できなくなると、データにアクセスできなくなる。 - 分散型データベース
データを複数のノードに分散させて管理しているデータベース。
データを分散さるため高度な管理技術を要するが、システム全体が故障する可能性は低い。
分散型データベースには以下のような種類のデータベースがあります。
- 連邦型データベース
自律した複数のデータベースを単一の連邦型データベースに割り当てたデータベース。 -
ブロックチェーンデータベース
時系列に従って、グループ化されたトランザクション(ブロック)のチェーンを生成し、各ブロックには同じチェーンに属する直前のブロック情報も含まれて管理される分散型台帳データベース。
データベース構成
次にデータベース構成ですが、構造化データを扱うデータベースと、非構造化データを扱うデータベースに分けて考えます。
構造化データを扱うデータベースの場合、データを書き込むには事前に構造(スキーマ)を知っておく必要があり、これをスキーマオンライトといいます。
一方、非構造化データを扱うデータベースの場合、保存されたファイルが持つデータを必要に応じて様々な形式で読み取ることができる必要があり、これをスキーマオンリードといいます。
構造化データを扱うデータベースには以下のような種類があります。
- リレーショナルデータベース
行と列によって構成された表形式のテーブルと呼ばれるデータの集合を、互いに関連付けて関係モデルを使ったデータベース。
主に、業務活動で発生するデータ(事実)を正確に記録するシステム(基幹システム)のデータベースとして用いられる。
業務で発生する事実を正確に記録するということで、データを客観的に扱うことを重視している(オブジェクト指向)。 - 多次元(マルチディメンショナル)データベース
データエレメントに対する複数のフィルターを同時に適用して検索が行えるような構造を持つデータベース。
主に、経営上の意思決定を支援することを目的としたデータウェアハウスとして用いられる。
経営者の意思決定を支援するということで、データを主観的に扱うことを重視している(サブジェクト指向)。
ここで、データウェアハウス(データ倉庫)とは、意志決定のため、目的別(Subject-oriented)に編成され、統合された時系列で、削除や更新しないデータの集合体のことです。
次に、非構造化データを扱うデータベースですが、これをNoSQLデータベースといい、ツリー、グラフ、ネットワーク、キー・バリューなど様々なタイプのものがあります。
データの設計
データマネジメントのためには、まず、企業全体のデータの基本構造となるデータアーキテクチャを設計する必要があります。
データアーキテクチャ
データアーキテクチャは、企業のデータ要件を満たすデータの基本構造のことです。
データアーキテクチャを設計することで以下のような効果があります。
- データ統合を手引きすることができる
- データ資産を効率的に管理することができる
- 事業戦略に合わせてデータへの投資を行うことができる(データ戦略)
データアーキテクチャは、エンタープライズアーキテクチャの一部で、ザックマンフレームワークの「資産」の列に該当します。
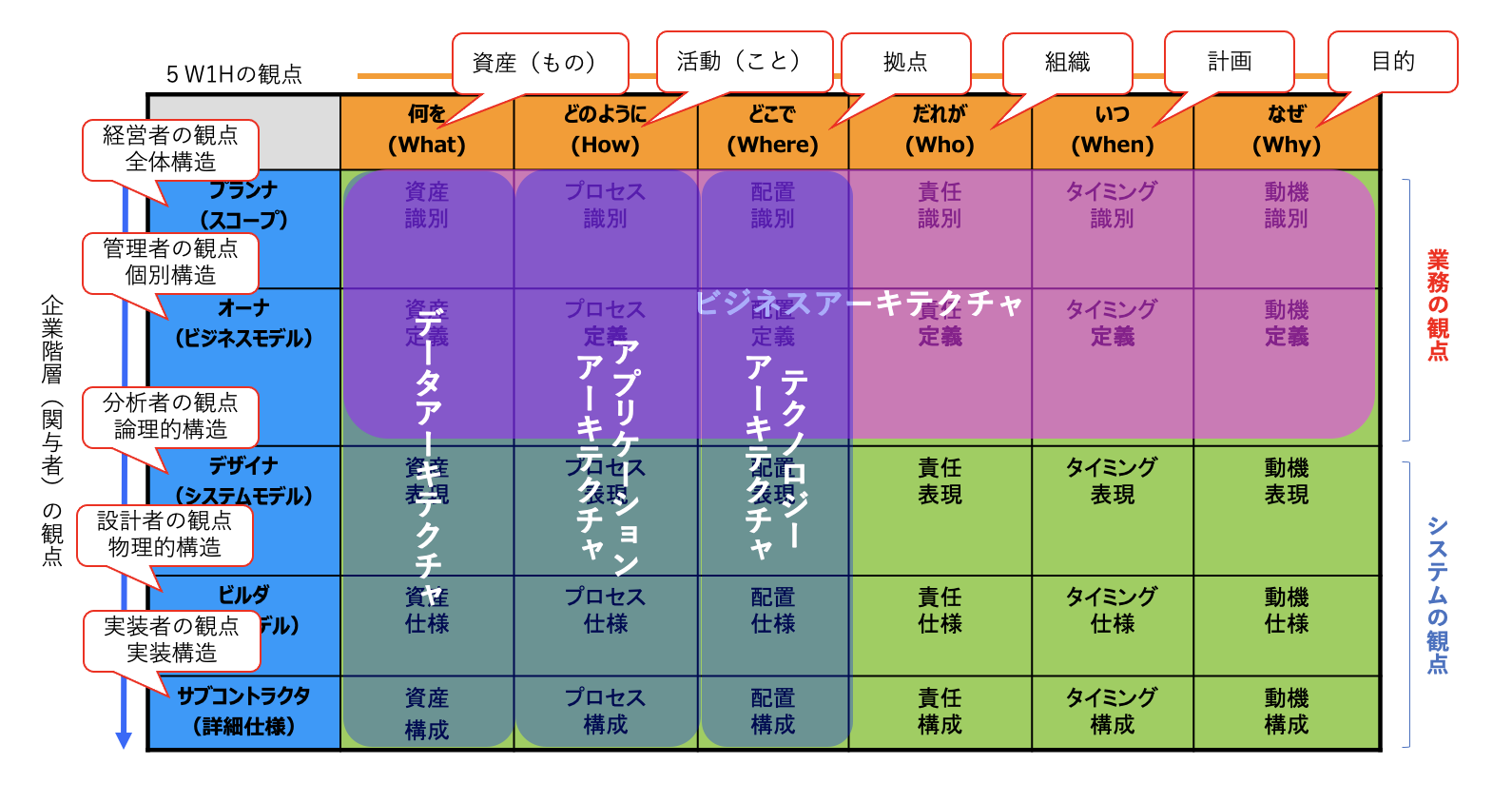
図:ザックマンフレームワーク
DMBOKでは、データアーキテクチャは、基本構造だけでなく、データがどの業務で生成され、どの業務で利用され、破棄されるのか、データのライフサイクルも示す必要があるとし、以下の2つのモデルを作成すべきとしています。
-
エンタープライズデータモデル
企業全体のデータの基本構造を示すモデル。 -
データフロー
データがビジネスプロセスやシステムをどのように移動するかを示すモデル。
エンタープライズデータモデル
エンタープライズデータモデルは、下図のように、
- 全社単位の全体概念データモデル
- 業務領域単位の概念データモデルおよび論理データモデル
- アプリケーション単位の論理データモデルおよび物理データモデル
から構成されています。
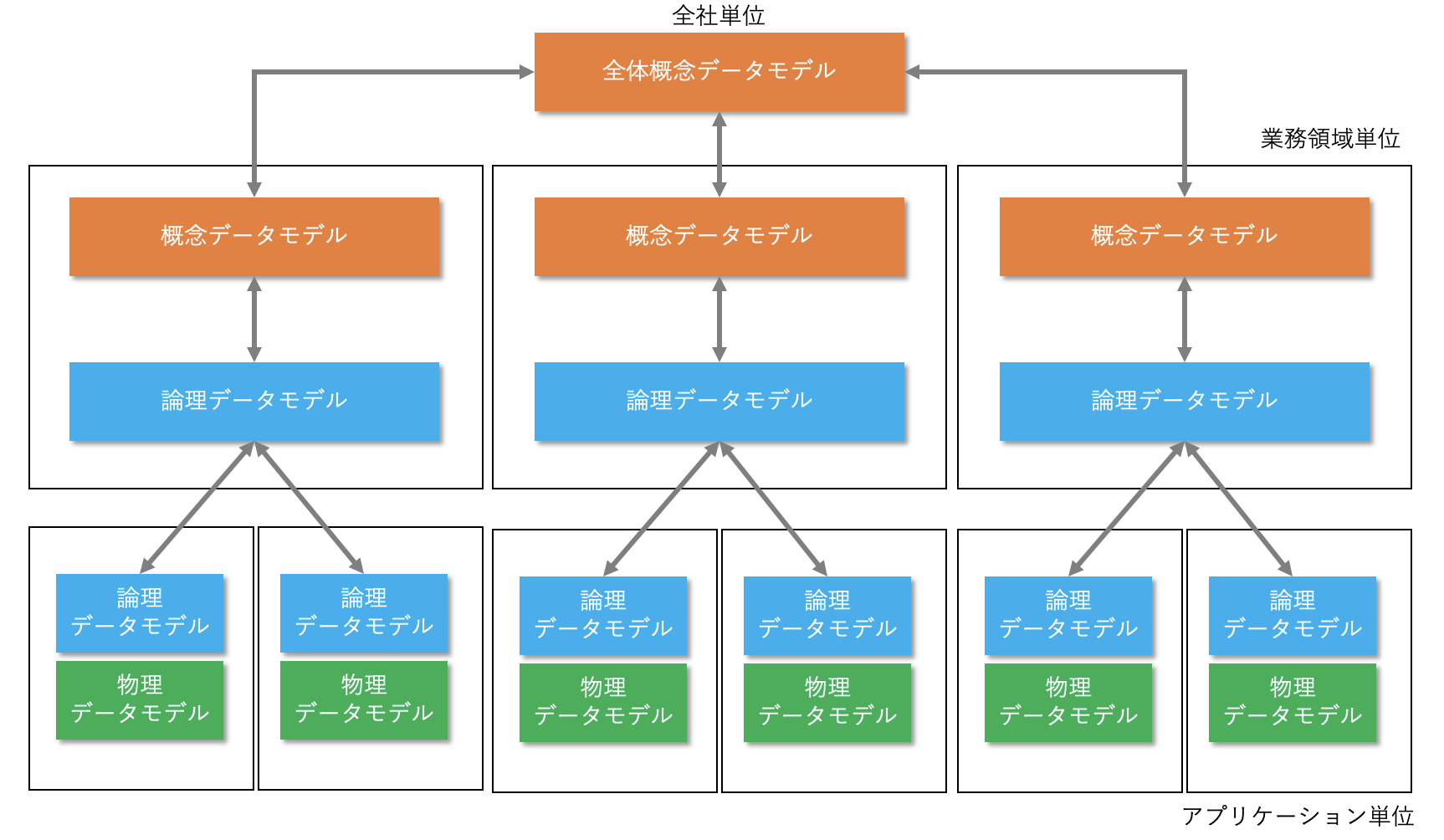
図:エンタープライズデータモデル 出典:データマネジメント知識体系 第二版
全社単位の全体概念データモデルは、上記ザックマンフレームワークでいうと経営者の観点のデータアーキテクチャを示し、企業の業務領域と、それらの関連で表されます。

図:全体概念データモデルの例
業務領域単位の概念データモデルおよび論理データモデルは、上記ザックマンフレームワークでいうと管理者の観点のデータアーキテクチャを示し、各業務領域を構成するエンティティと、それらの関連で表されます。
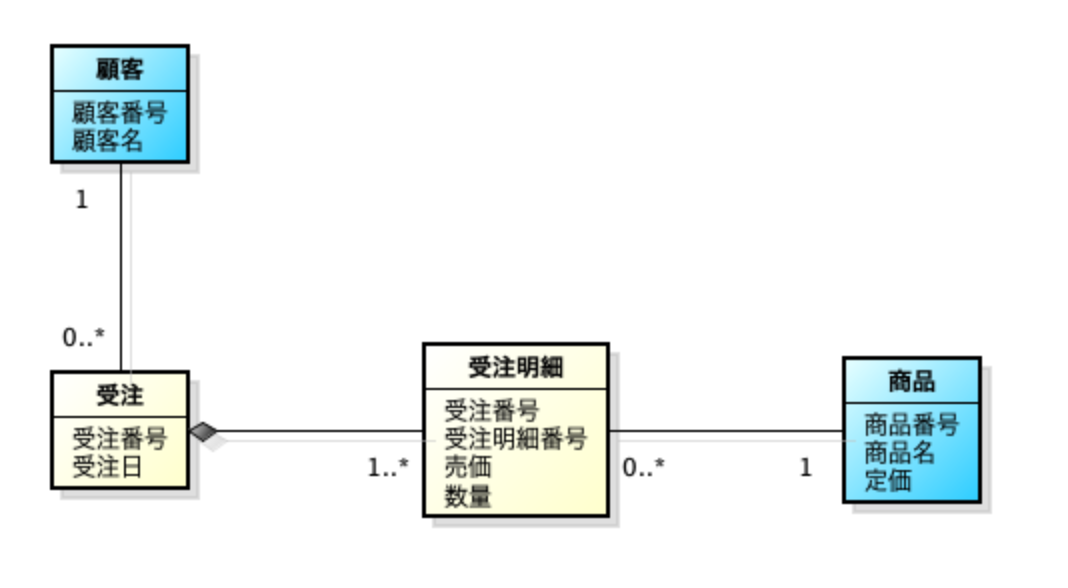
図:販売業務領域の論理データモデルの例
アプリケーション単位の論理データモデルおよび物理データモデルは、上記ザックマンフレームワークでいうと、それぞれ、分析者の観点のデータアーキテクチャと、設計者の観点のデータアーキテクチャを示し、各アプリケーションを構成するエンティティと、それらの関連で表されます。

図:販売管理システムの物理データモデルの例
データフロー
データフローは、横軸に全社の業務活動の流れ、縦軸に全社のエンティティ一覧のマトリクスを書き、データがどこで生成、参照、更新、削除されるか、データのライフサイクルを示すことで作成することができます。
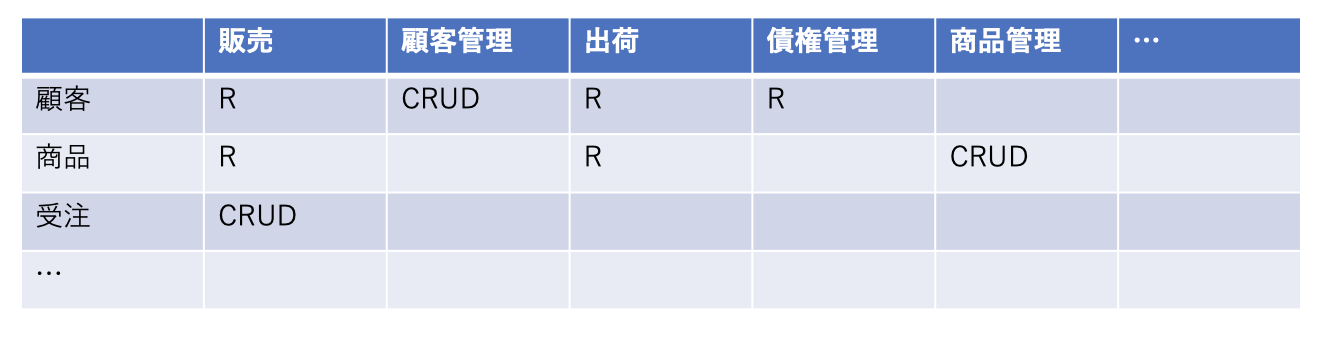
図:データフローの例
この図の場合、Cは生成、Rは参照、Uは更新、Dは削除を表しています。
なので、顧客データは、顧客管理業務で生成、更新、削除され、販売業務、顧客管理業務、出荷業務、債権管理業務で参照されることがわかります。
データモデル
次に、エンタープライズデータモデルを構成する3つのデータモデル
- 概念データモデル
- 論理データモデル
- 物理データモデル
について見ていきましょう。
この3つのモデルの違いを説明するまえにMDA(Model-Driven Architecture:モデル駆動アーキテクチャ)について説明します。
MDAは、標準化団体であるOMG(Object Management Group)が「20年持続するソフトウェアアーキテクチャ」を目標として2001年に提唱した概念で、以下の3つのモデルから構成されています。
- CIM(Computation Independent Model)
計算機処理に依存しないモデル。 - PIM(Platform Independent Model)
IT基盤に依存しないモデル。 - PSM(Platform Specific Model)
IT基盤に特化したモデル。
MDAは、この3つもモデルを分けて考えることで、より堅牢なシステムをつくることができるという考え方です。
MDAの考え方を踏まえて3つのデータモデルの違いについて説明します。
- 概念データモデル
ビジネスの仕組を実現するために必要なデータ(業務活動で発生する事実)の構造を明確にする。
CIMに該当する。 - 論理データモデル
システムの機能要件やデータの品質要件(一意性・一貫性・参照整合性など)を満たすデータの構造を明確にする。
PIMに該当する。 - 物理データモデル
システムの非機能要件(特に効率性)を満たし、IT基盤(データベース製品など)に適応したデータの構造を明確にする。
PSMに該当する。
なので、データベース製品が変わったら物理データモデルは作り直す必要がありますが、論理データモデルは再利用することができます。
また、概念データモデルは、システムに依存しないモデルなので、システムの機能要件が変わり論理データモデルが変更されても、業務の仕組が変わらない限り不変です。
なお、データモデルを作成するときは、データモデリングスキームを決める必要があります。
データモデリングスキームによって、どのようなデータモデルを作成するか、その型が決まります。
代表的なデータモデリングスキームには以下があります。
- リレーショナルスキーム
行と列によって構成された表形式のデータ集合を、互いに関連付けた関係モデルによって表す方法。
リレーショナルスキームで表したデータモデルをリレーショナルモデルという。
上記リレーショナルデータベースに対応する。 - ディメンショナルスキーム
データを、時系列の数値を持つ「ファクト」と分析軸となる「ディメンション」によって表す方法。
ファクトを中心としてディメンションを周辺に配置することから 「スタースキーム」とも呼ばれる。
ディメンショナルスキームで表したデータモデルをディメンショナルモデルという。
上記マルチディメンショナルデータベースに対応する。
次の図は、学生が学校に入学申請することを表したリレーショナルモデルの例です。
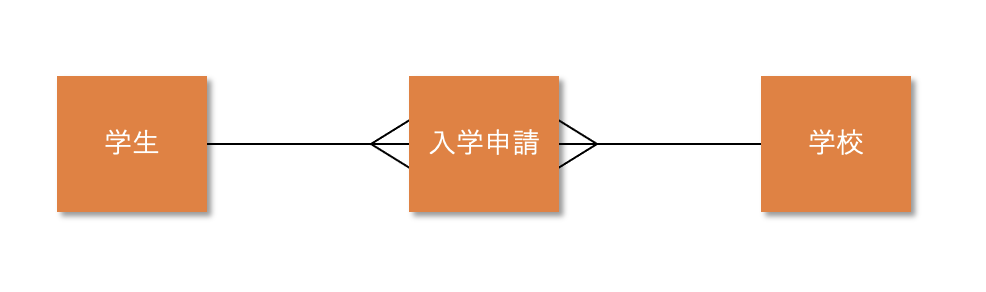
図:リレーショナルモデルの例
また、次の図は、入学申請を地理、学校、学資支援、カレンダーという次元で分析するディメンショナルモデルの例です。
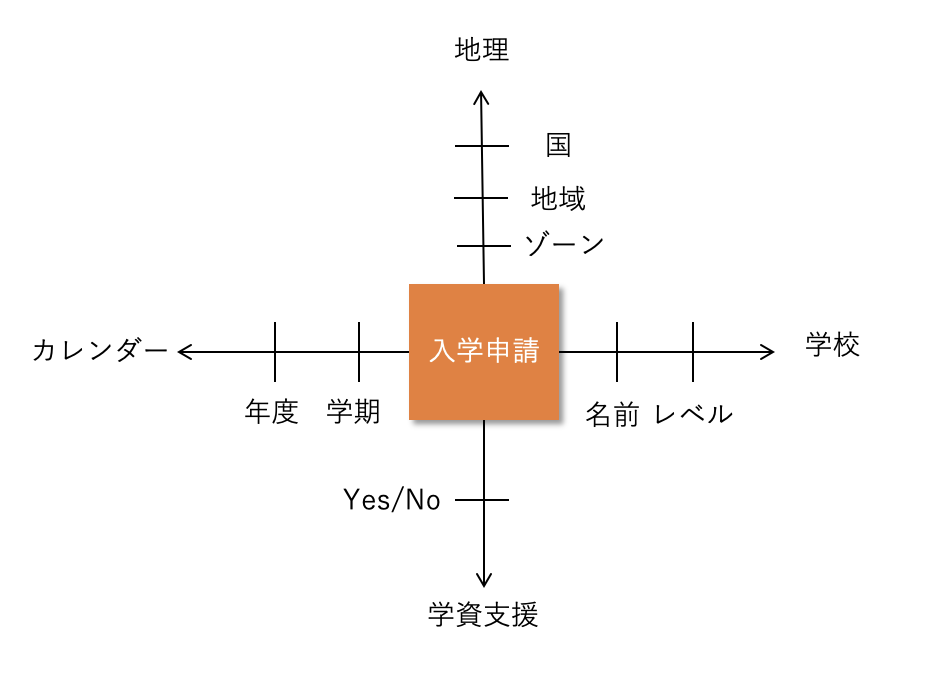
図:ディメンショナルモデルの例 出典:データマネジメント知識体系 第二版
なお、上記販売業務領域の論理データモデルの例(図)や販売管理システムの物理データモデルの例(図)は、オブジェクト指向型スキームの表記法UMLを使ってデータモデルを記述しています。
データの統合と相互運用
次にデータ統合と相互運用(Data Integration and Interoperability:DII)の概要について見ていきましょう。
DMBOKでは、データ統合と相互運用を行う上で重要な概念として以下をあげています。
- ETLとETL
- レイテンシ
- アーカイブ
- カノニカルモデル
- データ連携モデル
- DIIアーキテクチャ
ここでは、データ統合と相互運用全体に関わる中心的概念、ETLとELTについて説明します。
ETLのEはExtract(抽出)、TはTransform(変換)、LはLoad(取込)を表しています。
ETLとELTは、アプリケーション間や組織間でデータをやり取りするときのプロセスです。
ETLやELTは、
定期的に予定が組まれたバッチ処理や
データが利用可能になった時点におけるイベント駆動処理やリアルタイム処理
で実行されます。
ETLかELTは、Transform(変換)機能の多さによって選択します。
より多くの変換機能がある場合は、一旦、取り込んだ後に変換するELTが選択されます。
次の図は、構造化データと非構造化データのデータ統合とデータ利活用を表したものです。
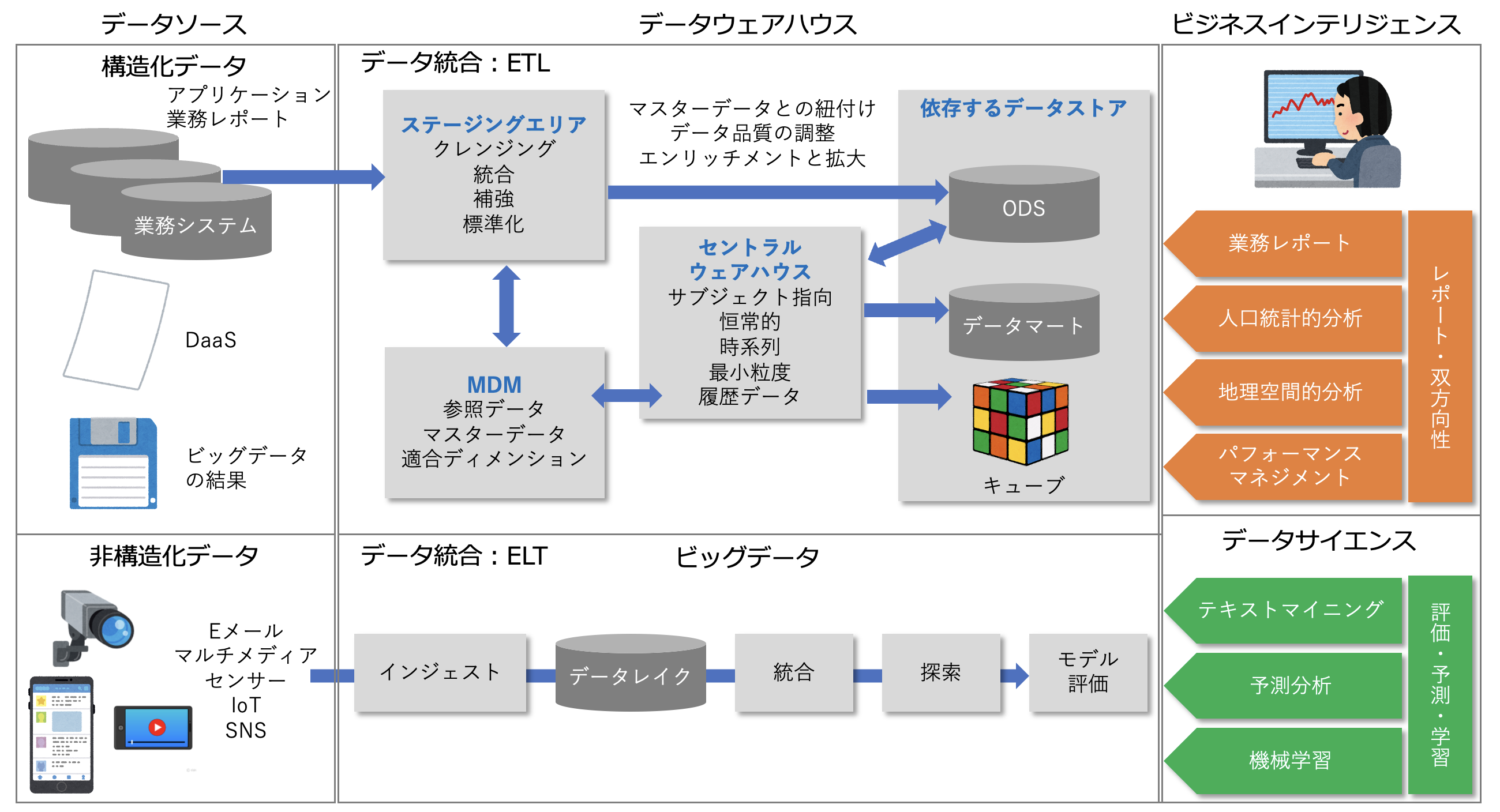
図:データウェアハウスとビッグデータのアーキテクチャ 出典:データマネジメント知識体系 第二版
この図の上段は、基幹システムの構造化データをデータウェアハウスにETLで取り込んで統合する例を示しています。
その際、リレーショナルモデルの構造化データは、ディメンショナルモデルの構造化データに変換されます。
下段は、IoTはSNSなどで発生する非構造化データをデータレイクに一旦取り込んだあと必要に応じて様々なデータセットに変換する例を示しています。
この場合、データマイニングする際、適用されるモデルによって必要となるデータセットの形式が異なるためELTが採用されています。
データの利活用
次に、統合されたデータをどう利活用するのか見ていきましょう。
データを利活用する主な方法は以下の2つです。
- ビジネスインテリジェンス
ビジネスインテリジェンスは、経営上の意思決定を行う目的で、データウェアハウスに格納されているデータを多次元分析する方法です。
ビジネスインテリジェンスの場合、データウェアハウスにある構造化データをベースにしているため定型的な分析になります。
上記、データウェアハウスとビッグデータのアーキテクチャ(図)の上段にビジネスインテリジェンスの例が示されています。 - データサイエンス
データサイエンスは、データレイクに格納されたビッグデータからパターンを見つけて予測モデルを構築する科学的な手法です。
データサイエンスは、経営上の意思決定だけでなく、販売支援や人材育成など様々な目的で活用することができます。
データサイエンスの場合、IoTやSNSなどから集められた非構造化データをベースにしているため非定型的な分析になります。
上記、データウェアハウスとビッグデータのアーキテクチャ(図)の下段にデータサイエンスの例が示されています。
データ品質の管理とメタデータ
上記のように、ビジネスインテリジェンスやデータサイエンスでデータを利活用しようとしても、元となるデータの品質が悪いと、データ解析の信頼性が担保できません。
DMBOKでは、以下の観点でデータ品質について説明しています。
- データ品質とは何か
- データ品質はなぜ重要なのか
- データ品質をどう評価するか
- データ品質をどう測定するか
- データ品質をどう維持・向上させるか
DMBOKでは、品質の低いデータがもたらす事象の例として以下をあげています。
- 誤請求
- 顧客サービスコールの増加とそれを解決する能力の低下
- 事業機会の逸失による収益損失
- 合弁・買収の間に発生する業務統合の遅延
- 不正行為発覚の増加
- 不正なデータに起因する業務上の意思決定不備がもたらす損失
- 良好な信用力の欠如による事業の損失
データ品質の詳細については、データ品質を参照してください。
次に、メタデータについて説明します。
メタデータとは、データに関するデータのことで、主にデータの品質を管理する目的で収集、管理されます。
DMBOKには、メタデータの重要性を示すために以下のような記述があります。
データマネジメントにおけるメタデータの重要な役割を理解するために大きな図書館を想像してみよう。
そこには、数十万の書籍と雑誌があるのに、図書目録がない。
図書目録がなければ、利用者は特定の本や特定のトピックの検索を開始する方法さえわからないかもしれない。
図書目録は、必要な情報(図書館が所有する本と資料、保管場所)を提供するだけでなく、利用者が様々な着眼点(対象分野、著者、タイトル)から資料を見つけ出すことを可能にする。
メタデータを持たない組織は、図書目録のない図書館にようなものである。
このメタデータですが、DMBOKでは次の3つの種類をあげています。
- ビジネスメタデータ
ビジネスメタデータは、主にデータの内容と状態に重点を置いており、データガバナンスに必要な詳細を含む。
ビジネスメタデータには、概念、対象領域、エンティティ、属性に関する名称と定義が含まれる。 - テクニカルメタデータ
テクニカルメタデータは、データの技術的な詳細、データを格納するシステム、および、システム内やシステム間でデータを移動するプロセスに関する情報を提供する。 - オペレーショナルメタデータ
オペレーショナルメタデータは、バッチジョブのログやデータ抽出の履歴などデータ処理とアクセスの詳細を表す。
それでは、このメタデータをデータ品質の管理にどう活かすのでしょうか。
DMBOKにはデータ品質とメタデータについて次のような記述があります。
メタデータはデータ品質を管理する上で重要である。
データ品質は、データ利用者の要件をどれだけ満たしているかによって決まる。
データが何を表現するかはメタデータで定義される。
データを定義する安定した手順を踏むことで、データ品質の測定標準と要件を規格化し文書化する組織の能力を上げる。
データに関する利用者の期待はデータ品質によって担保され、メタデータは、その期待を明確にする主要な手段である。
このように、メタデータによってデータ品質の測定標準と要件を規格化し文書化することができます。
なお、メタデータは構造化データだけでなく画像、動画、音声など非構造化データの品質を管理する上でも重要です。
データのリスク管理とデータセキュリティ
データの品質と共にデータのリスクを管理することも重要です。
データのリスクとは、主にデータの安全性(セキュリティ)に関するリスクです。
詳細は、データセキュリティを参照してください。
データガバナンス
最後にデータのライフサイクル管理、品質管理、リスク管理をどう統治するのかデータガバナンスについて見ていきましょう。
DMBOKでは、データガバナンスを
職務権限を通してデータマネジメントを統制(コントロール)すること
と説明しています。
最初に注意しておきたいのは、データガバナンスは、データが適切にマネジメントされるようにすることであって、データマネジメントを直接実施するわけではないということです。
DMBOKでは、データガバナンスとデータマネジメントを以下のように分けています。
- データガバナンス
データを適切にマネジメントさせること。 - データマネジメント
ゴールに到達するためにデータを管理すること。

図:データガバナンスとデータマネジメント 出典:データマネジメント知識体系 第二版
このように、職務を監督側と実行側に分離することによってデータマネジメントに対する統治(ガバナンス)が働くのです。
会計監査人と経理が分かれていることを考えていただければよいかと思います。
さて、DMBOKでは、データガバナンスを行う上で重要な概念として以下をあげています。
- データ中心組織
- データガバナンス組織
- データガバナンスオペレーティングモデルタイプ
- データスチュワード制
- データポリシー
- データ資産評価
DMBOKではデータが適切にマネジメントされるよう統治するデータガバナンス組織を次のように表しています。

- 立法機能
ポリシー、規定、エンタープライズデータアーキテクチャを定義する。 - 司法機能
課題管理と報告。 - 行政機能
データの保護とサービス、行政責任。
この中のデータスチュワードは主に次のような活動を行います。
- コアとなるメタデータの作成と管理
業務用語、データの有効値などの重要なメタデータの定義と管理。 - データに関するルールと標準の文書化
業務ルール、データ標準、データ品質ルール(品質評価指標や品質評価基準含む)を定義し文書化する。 - データ品質の問題管理
データ関連の問題の特定と解決や、解決プロセスの推進。 - データガバナンス運営
プロジェクト毎、および、定期的にデータガバナンスポリシーと取り組みが忠実に守られるように統制する。


[…] ここで、データマネジメント知識体系(DMBOK)におけるデータサイエンスの位置付けについて説明します。 これは、DMBOKで説明しているデータマネジメントの機能フレームワークです。 […]
[…] されるブロックチェーンを、ブロックチェーンデータベースといいます。 データマネジメント知識体系(DMBOK)では、ブロックチェーンデータベースを分散型データベースの一種として […]
[…] DAOを再利用可能なデータ部品とすることで生産性を高めることができます。 データモデルや、データの分類の詳細についてはデータマネジメント知識体系(DMBOK)を参照してください。 […]
[…] データマネジメント知識体系(DMBOK)によると、データアーキテクチャとは、 […]
[…] ここでは、データマネジメント知識体系(DMBOK)を参考にして、マスターデータ管理(MDM)について以下の観点で解説します。 […]
[…] ます。 なお、ここでは、情報管理の中のデータのライフサイクルを管理する活動をデータマネジメントとして考えています。 データマネジメントが データ資産の価値を提供、維持向上 […]
[…] るためにデータライフサイクルを通して計画、実施、監督すること です。 データマネジメント知識体系(DMBOK)では、品質の低いデータがもたらす事象の例として以下をあげています。 […]
[…] ここでは、データマネジメント知識体系(DMBOK)を参考にして、メタデータ管理(MDM)について以下の観点で解説します。 […]
[…] 管理してデータ品質を維持・向上させるデータマネジメントが重要です。 データマネジメント知識体系(DMBOK)では、データマネジメントを、 データという資産の価値を提供し、管理 […]
[…] DMBOKではデータセキュリティを次のように定義しています。 […]
[…] と、データ解析の信頼性が担保できません。 データ品質とは、データがどれだけ信頼できるかを表すもので、DMBOKには、主に次のような指標で評価することができると説明されています。 […]
[…] オブジェクトが等価(equivalent)とは、オブジェクトの値が等しいということです。 これは、オブジェクトの持つ状態変数の値が等しいことを意味します。 等価性(equivalence)とは、オブジェクトが持つ、等価かどうかを示す性質のことです。 ビットコインなどの暗号通貨も含め通貨には等価性があります。 Aさんが持つ1000円とBさんが持つ1000円は、同一性はありませんが、同じ1000円という価値を持ちます。 ソフトウェア開発で、問題領域(ドメイン)に存在するオブジェクトを分析するときに重要な観点は、オブジェクトの等価性を意識するかどうかです。 オブジェクトにおける同一性と等価性の関係は、論理包含の関係になります。 同一⇒等価 つまり、同一(IDが同じ)ならば等価(値も同じ)という論理関係です。 同一(IDは同じ)だけど等価でない(値は違う)という状況はありません。 Aさんが持つ1000円もBさんが持つ1000円は、同一性はありませんが、同じ1000円という価値を持ちます。 これは、「同一ではないが等価である」という例です。 同一性を持つオブジェクトのことを参照オブジェクト(reference object)といいます。 また、参照オブジェクトのクラスをエンティティといいます。 同一ではないが等価であるオブジェクトのことを値オブジェクト(value object)といいます。 次の図は、製品のパワータイプである製品アイテムが、色、サイズ、外形という分類基準によって製品を分類することを表しています。 製品の識別子である「製造番号」は製品個体一つ一つを識別する番号ですが、製品アイテムの識別子である「製品番号」は製品の種類一つ一つを識別する番号です。 なので、製品アイテムと製品は参照オブジェクトのクラス(エンティティ)です。 一方、コード、摘要、定義しか属性を持たない分類基準、色、サイズ、外形は値オブジェクトのクラスになります。 ※分類基準は「集合の条件」になります。 書籍「実践ドメイン駆動設計」では、値オブジェクトは、何かを計測したり定量化したり説明したりするものと定義されており、同一性を必要としません。 なので、値オブジェクトは、値が決まった属性をクラスとして抽出した形になります。 なお、値オブジェクトはDMBOKで参照データとして説明されています。 […]
[…] 、集合のほうを実体タイプ(エンティティタイプ)といいます。 しかし、データマネジメンチ知識体系(DMBOK)では、 「ジェーンは、従業員である」 といった場合、さきほどのライプ […]
[…] 2488;ランザクションデータなどデータの種類がありますが、ここでは、} […]
[…] 377;る事実を表したものです。 データマネジメント知識体系(DMBOK)では、 […]
[…] #35328;及しましたが、データマネジメント知識体系(DMBOK)では、データアー […]
[…] ;価し分析できる環境のことです。 DMBOKでは、データレイクについて次の […]
[…] 3;になるか設定します。 次の図は、DMBOKのデータマネジメント成熟度モデ […]
[…] 12434;表すものです。 データマネジメント知識体系(DMBOK)には、データアー […]
[…] ここでは、マスターデータの全体概念データモデルを設計します。 法 […]