![]()
ここでは、自律分散型データ基盤について次の観点で説明します。
自律分散型データ基盤とは何か
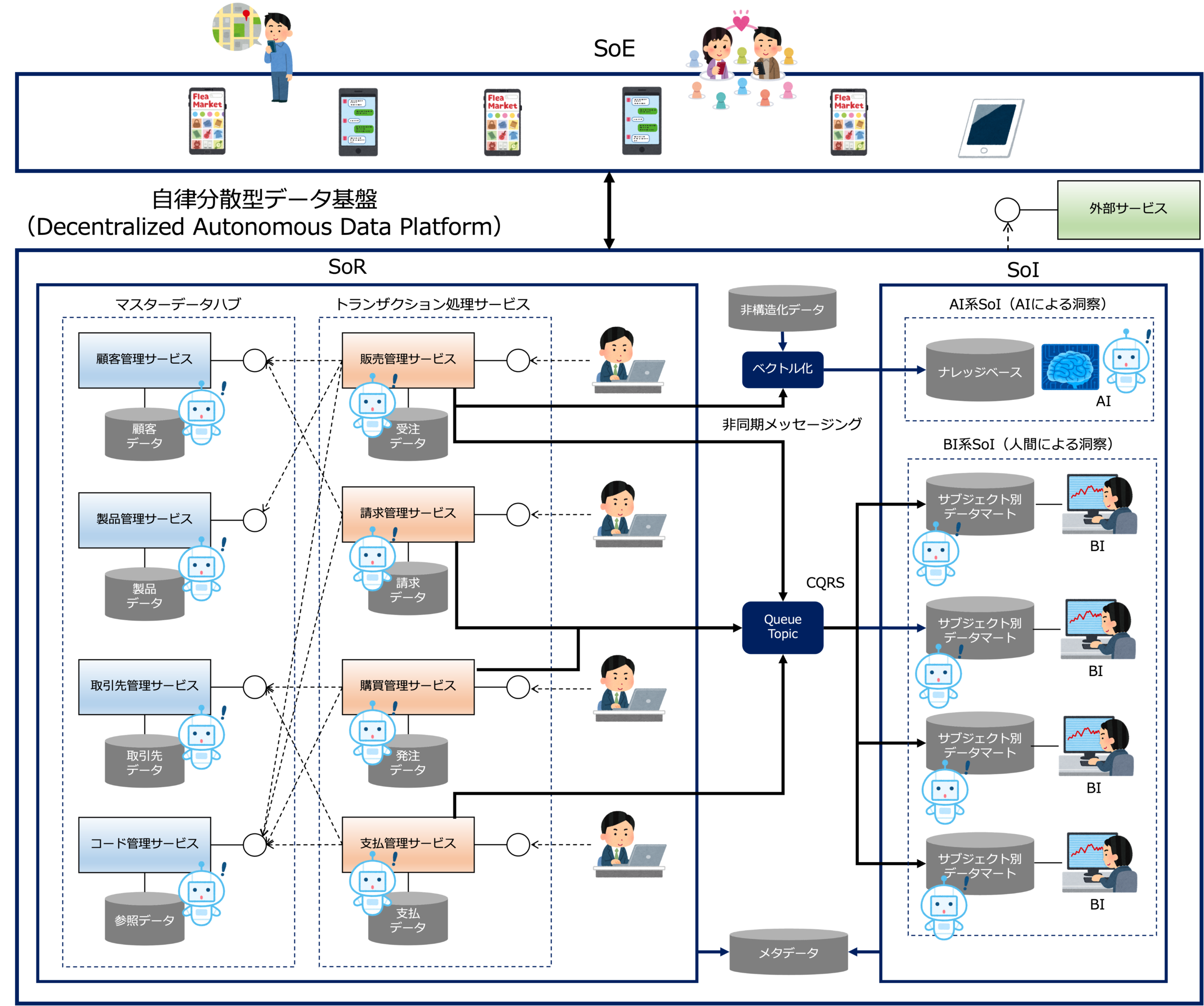
自律分散型データ基盤(Decentralized Autonomous Data Platform)とは、
会社のデータを中央のデータウェアハウスなどの管理基盤で一元的に集約・管理する集中型のデータ基盤ではなく、
データと、それを扱う業務機能をマイクロサービス単位でカプセル化し、疎結合で連携させる分散型のデータ基盤のことです。
さらに、各マイクロサービスに AI エージェントを組み込むことで、サービス同士が自律的に協調・連携することを特徴とします。
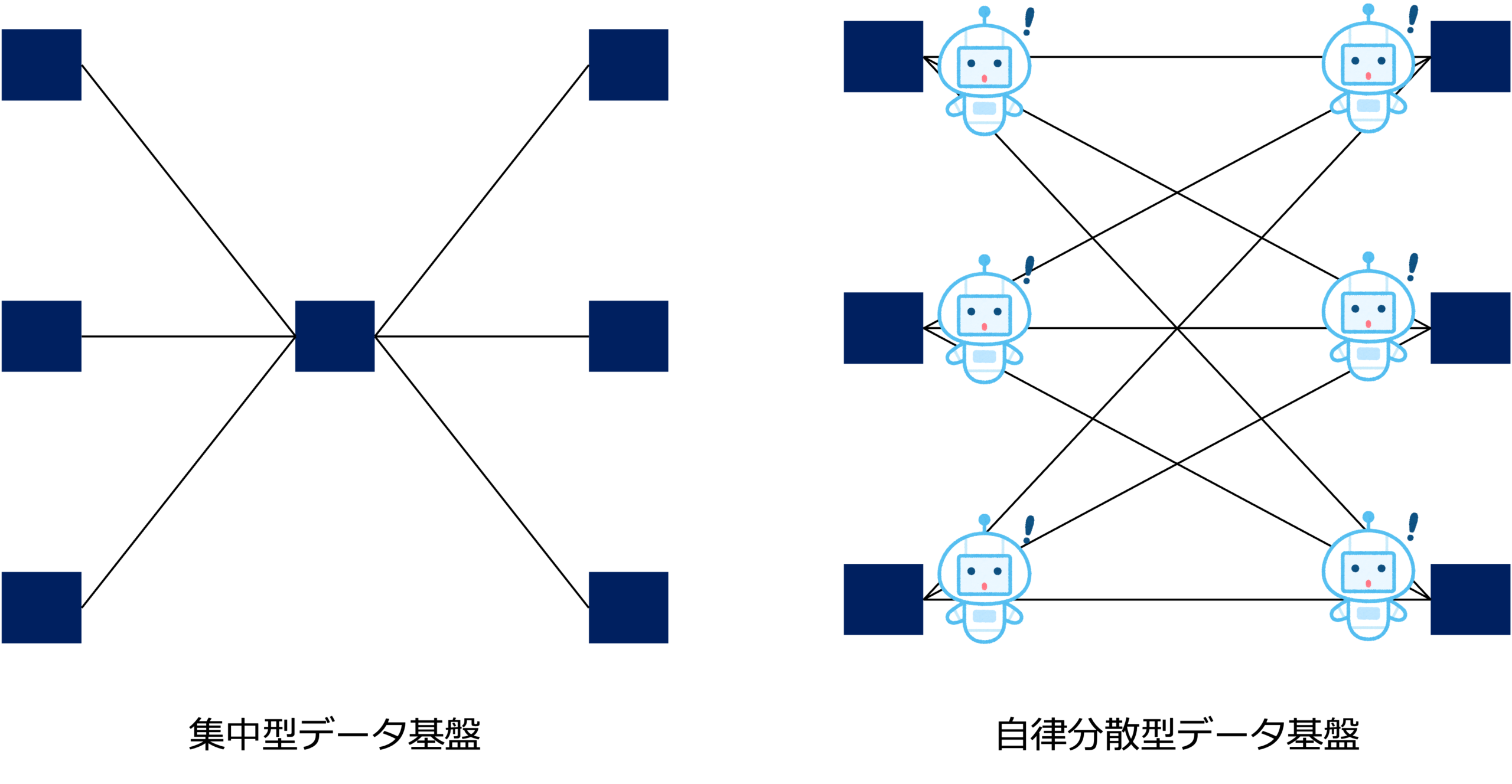
時代は、集中と分散を繰り返します。
比較的安定した時代は、データや機能の構造も安定しており、それらを集中して管理するほうが効率がよいと思います。
しかし、昨今のように先行き不透明で予測困難な時代は、データや機能を分散し、どのような事態になっても自在に形を変えられる仕組にしておくほうが、ビジネスの環境に対する適応力(レジリエンス)を上げることができます。
自律分散型データ基盤では、AIエージェントが、サービス間の連携、最適化、異常検知を担うことで、人がすべてを設計、制御しなくても全体の秩序を保つことができます。
一般的に、分散システムは管理コストが高くなりますが、自律分散型データ基盤では、複雑なP2P(PeerToPeer)接続(N対Nの接続)にかかるコストをAIエージェントが解消します。
自律分散型データ基盤の特徴
自律分散型データ基盤の特徴は次の3つです。
会社の重要なデータの品質とセキュリティを確保することができる
自律分散型データ基盤は、信頼性や機密性の高いデータをマイクロサービスにカプセル化します。
MECEに分割された業務ドメイン単位で「One Fact in One Place」を実現することで、データの散在を防ぎ、データ品質とセキュリティを担保することができます。
これにより、自律分散型データ基盤は、信頼できる会社で唯一のデータソース(single source of truth)を確立します。
さて、集中型のデータ基盤も、会社のデータを中央で一元管理するのでデータの品質やセキュリティを確保することができるのではないかと考えることがあります。
しかし、集中型のデータ基盤では、一元化されたデータ構造に多くの処理が依存するため、データ構造が変更されると多くの処理に影響が及ぶという問題が発生します。
DOAの思想の根底には、
「処理は業務改善などによって頻繁に変わるが、業務の本質を表すデータ構造は比較的安定している」
という考え方があります。
しかし実際には、データ構造も属性の追加や関係の拡張など、少しずつ変化していきます。
その結果、全体で一元化されたデータにアクセスする処理が増えるほど、データ構造変更の影響範囲が拡大し、処理の追加や変更の柔軟性が低下していきます。
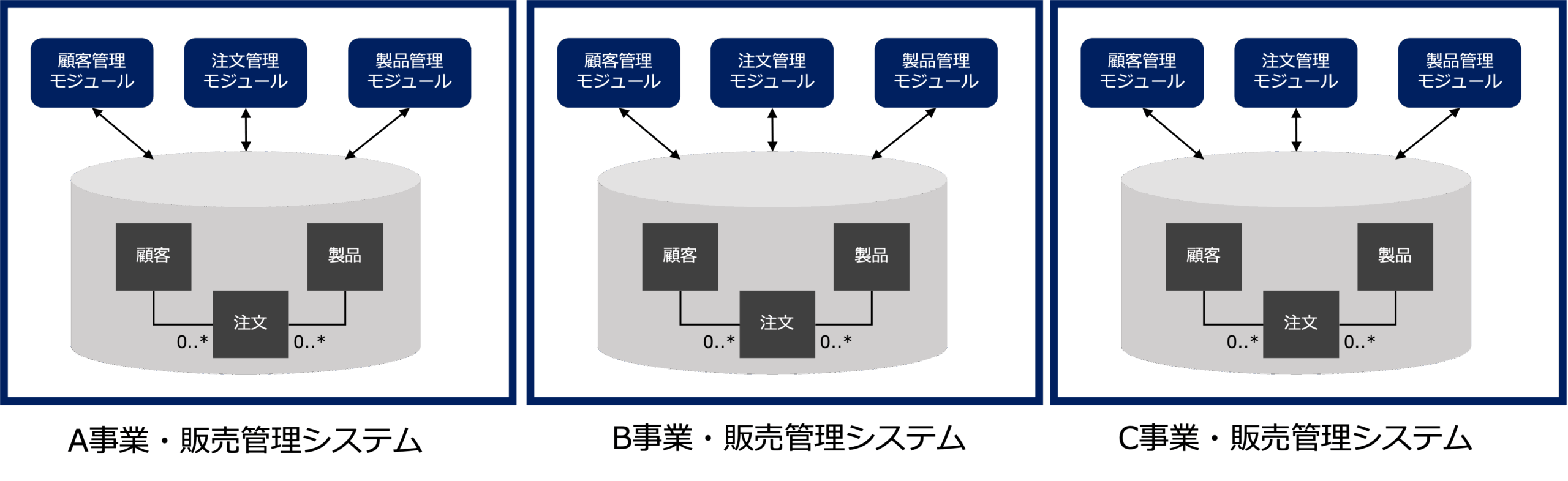
例えば、企業全体の業務機能とデータをパッケージ化して提供する業務パッケージを考えてみましょう。
業務パッケージの場合、企業の全業務の機能とデータを統合する(囲い込む)ことを前提として設計されているため、パッケージ内部で機能とデータが複雑に絡み合っており、機能の改修や追加にかかるコストが高くなります。
また、業務パッケージは、それを構成するモジュール同士がマイクロサービスアーキテクチャのようにAPIや非同期通信を通して連携できるように設計されていないため、業務モジュール単位で分割して導入すると、他のパッケージやシステムとの連携が困難になります。
結果的に、企業内に、独立した業務パッケージが乱立し、システムと業務のサイロ化が進むことになります。
会社の業務とシステムを変化に強い構造にすることができる
マイクロサービスは、会社の業務ドメインごとに、ビジネスロジックをシステム機能としてカプセル化し、モジュール化します。
モジュール化とは、ビジネスやシステムを構成する要素を、論理的な仕様(インターフェース)と、それを実現する物理的な手段に分けて設計(仕様と実装の分離)し、構成要素を利用する相手に対してインターフェースのみ公開することで、物理的手段やデータを相手から隠蔽し(ブラックボックス化)自由に交換可能にすることです。
業務の機能単位であるマイクロサービス同士をインタフェースによって疎結合することで、変更による影響を最小にする保守性の高い仕組みを実現することができます。
また、マイクロサービスをソフトウェア部品として組み合わせることで新しいシステムを開発することでシステム開発の生産性を劇的に上げることができます。
例えば、マイクロサービスによって、次のようなソフトウェア設計原則を実現することができます。
- 単一責任の原則
マイクロサービスは、特定の業務ドメインのビジネスロジックをその中に閉じ込めるので、ビジネスロジックの散在を防ぎます。
これにより、特定の業務の仕様が変わった場合、特定のマイクロサービスだけ変更すればよく、業務の変更によるリスクを局所化することができます。 - 開放閉鎖(Open/Close)の原則
マイクロサービスは、既存のインタフェース(仕様)を変更せずに内部実装を改修するように設計することができます(修正に閉じる)。
これによって、利用者は機能修正による影響を受けることがありません。
また、既存のインターフェース(契約)を壊さず、新しいインターフェースやイベントとして機能を拡張することができます(拡張に開く)。
これによって、利用者は拡張された機能を利用するタイミングを選べるため、その影響を最小化することができます。
会社の業務とシステムを自律化することができる
マイクロサービスにAIエージェントを組み込み、コアプロセスを再設計することで、環境の変化を自動的に察知し、自律的に最適な状態へと調整する、生物のホメオスタシスのような仕組みを実現することができます。
業務とシステムの自律化
ここでは、自律分散型データ基盤の特徴の一つ「会社の業務とシステムを自律化することができる」について詳細に説明します。
まず、ここでは、自律分散型データ基盤に組み込むAIエージェントを次の4つに分類します。
- BSCエージェント
BSCに組み込まれたAIエージェントで、KPIの因果関係に基づいて以下を実行します。- KPI因果関係の妥当性検証
- KPI因果関係の改善提案
- 上位KPIの根本原因となる下位KPIの予測
- 下位KPIの状態変化を受けた上記KPIの状態予測
- KPIエージェント
個別KPI単位のSoIサービスに組み込まれたAIエージェントで、KPI値の異常検知などを実行します。 - バリューチェーンエージェント
オペレーションサイクル単位で設置されたAIエージェントでTOCの制約の特定、制御を実行します。
バリューチェーンエージェントは、それを構成するビジネスプロセス単位のビジネスプロセスエージェントを配下に持ちます。 - ジョブエージェント
個別のジョブ単位のSoRごとのAIエージェントで、各業務活動の品質向上や内部統制などを通して業務を最適化します。
SoRエージェントは、BSCエージェントやTOCエージェントの判断やポリシーに基づいて業務ルールやプロセスを調整する、企業組織におけるアクチュエータの役割を担います。
この4つのエージェントが協働(コラボレーション)しながら組織のホメオスタシスを実現します。
まず、生物のホメオスタシスは次の4つの段階で実現されます。
- 観測(Sense)
今の状態を見る。
体の中にあるセンサーが、常に状態を見張っています。
例
体温・血糖などを測る。 - 判定(Decide)
理想と比べる。
観測した値を「理想の状態」と比べ正常か異常か判断します。
例
体温や血糖値が正常値に比べて高い。 - 介入(Act)
ズレを元に戻す動きをする。
ズレを元に戻すために体が動きます。
例
発汗、インスリン分泌など。 - 学習(Learn)
次はもっと上手に(より少ない負担で、より安定して、ズレを小さくするように)調整できるように変わる。
閾値や反応を変えて環境に適応します。
体は「どのくらいズレたら反応するか(閾値)」や「どれくらい強く反応するか」を調整します。
生物の場合、目的関数が生存確率であるため、異常を検知した際に強い調整を頻発させることによる負担を避けるべく、異常と判定する基準や反応強度を調整し、結果として異常検知と調整が発生する頻度を下げる方向に適応します。
例
血糖値の異常を判断する閾値が上がる。
同じインスリンの量では血糖値が下がらなくなる。
これを自律的分散型データ基盤に写像すると次のようになります。
- 観測(Sense)
KPI/メトリクス/品質/統制/制約スコア。
SoIエージェントが行う。 - 判定(Decide)
異常検知・因果仮説・制約推定・予測。
SoIエージェントが異常検知→BSCエージェントが仮説立案→TOCエージェントが制約特定。 - 介入(Act)
プロセス/ルール/パラメータ/リソース配分の変更(※自動化の範囲は段階的)
TOCエージェント→SoRエージェントが調整。 - 学習(Learn)
閾値、因果信頼度、施策効果の更新
SoIエージェントが効果測定し正常に戻ることを確認すると各エージェントが学習を行います。
企業の目的関数は企業価値の最大化です。
なので、各エージェントは次のように学習します。- BSCエージェント
KPI因果関係における因果の強度を変える。
例
そのKPIの重みを高くする。 - SoIエージェント
異常検知閾値や感度の更新。
例
より速く異常値を察知できるようにする。 - TOCエージェント
制約制御ルールや調整幅の更新。
例
より厳しいルールにし、制約解消後に段階的に緩める。 - SoRエージェント
制御方法(品質管理・内部統制)の変更。
例
制御方法の強化し、安定後に段階的に戻す。
- BSCエージェント
例えば、次のようなBSC(KPIの因果関係)があったとします。
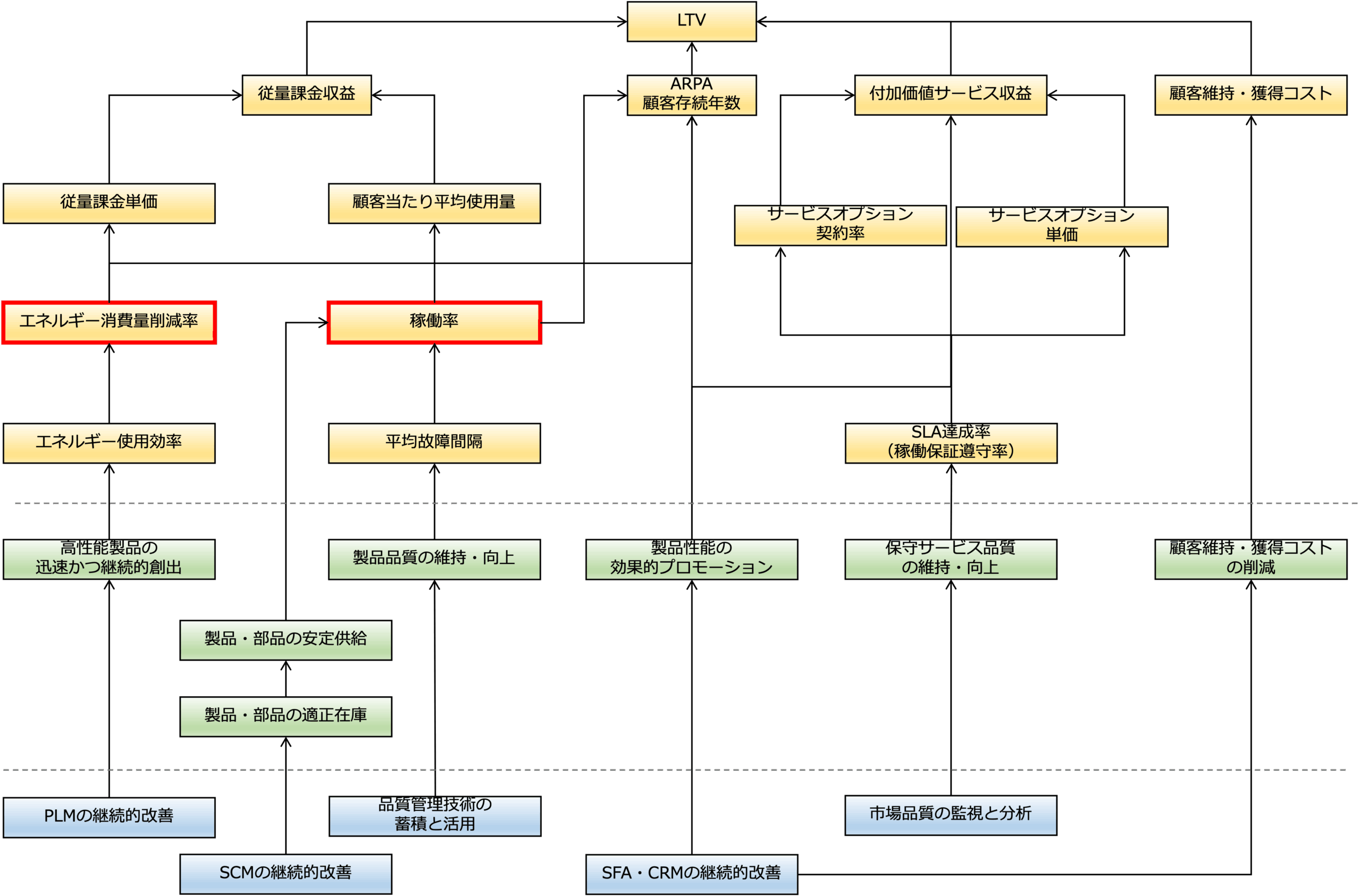
このうち稼働率を例にすると次のような制御が働きます。
平常状態
稼働率:98%
平均故障間隔:長い
部品供給:安定
TOC制約:通常は「保全対応キャパ」
制約は静的、WIPも安定
- 観測(Sense)
稼働率のSoIエージェントが以下を観測します。
トリガー
稼働率:98% → 94%
SLA達成率も微減
SoIエージェントの観測イベント例
{
“kpi”: “稼働率”,
“change”: “-4%”,
“anomaly”: true,
“confidence”: 0.92
} - 判定(Decide)
- 仮説立案
SoIエージェントがBSCエージェントに分析と判定を依頼
このBSCでは稼働率の上流は以下。
・平均故障間隔
・製品品質の維持・向上
・製品・部品の安定供給
BSCエージェントの仮説ランキング例
{
“hypotheses”: [
{
“cause”: “部品交換遅延”,
“path”: “安定供給 → 平均故障間隔 → 稼働率”,
“confidence”: 0.65
},
{
“cause”: “市場環境悪化”,
“confidence”: 0.2
},
{
“cause”: “使い方の変化”,
“confidence”: 0.15
}
]
} - 制約特定
BSCエージェントが製品出荷プロセスのTOCエージェントに制約の特定を依頼。
TOCエージェントはBAMのデータから計算された制約スコアを参照して品質検査工程が制約になっていると特定する。
詳細は、オペレーションの実践を参照してください。
- 仮説立案
- 介入(Act)
製品出荷プロセスのTOCエージェントは、品質検査エージェント(SoRエージェント)に不良リスクを予測するタスクの稼働率を上げるよう指示します(制約の改善)。
詳細は、アクティビティフローの設計を参照してください。 - 学習(Learn)
数日後、稼働率のSoIエージェントは効果を測定します。
・予防保全実施率 ↑
・平均故障間隔 ↑
・稼働率:94% → 97%
イベントの例
{
“result”: {
“uptime”: “+3%”,
“sla”: “+2.5%”,
“cost”: “+1.2%”
},
“verdict”: “effective”
}
それを受けて、各エージェントは異常値検知の強化などの学習を行います。
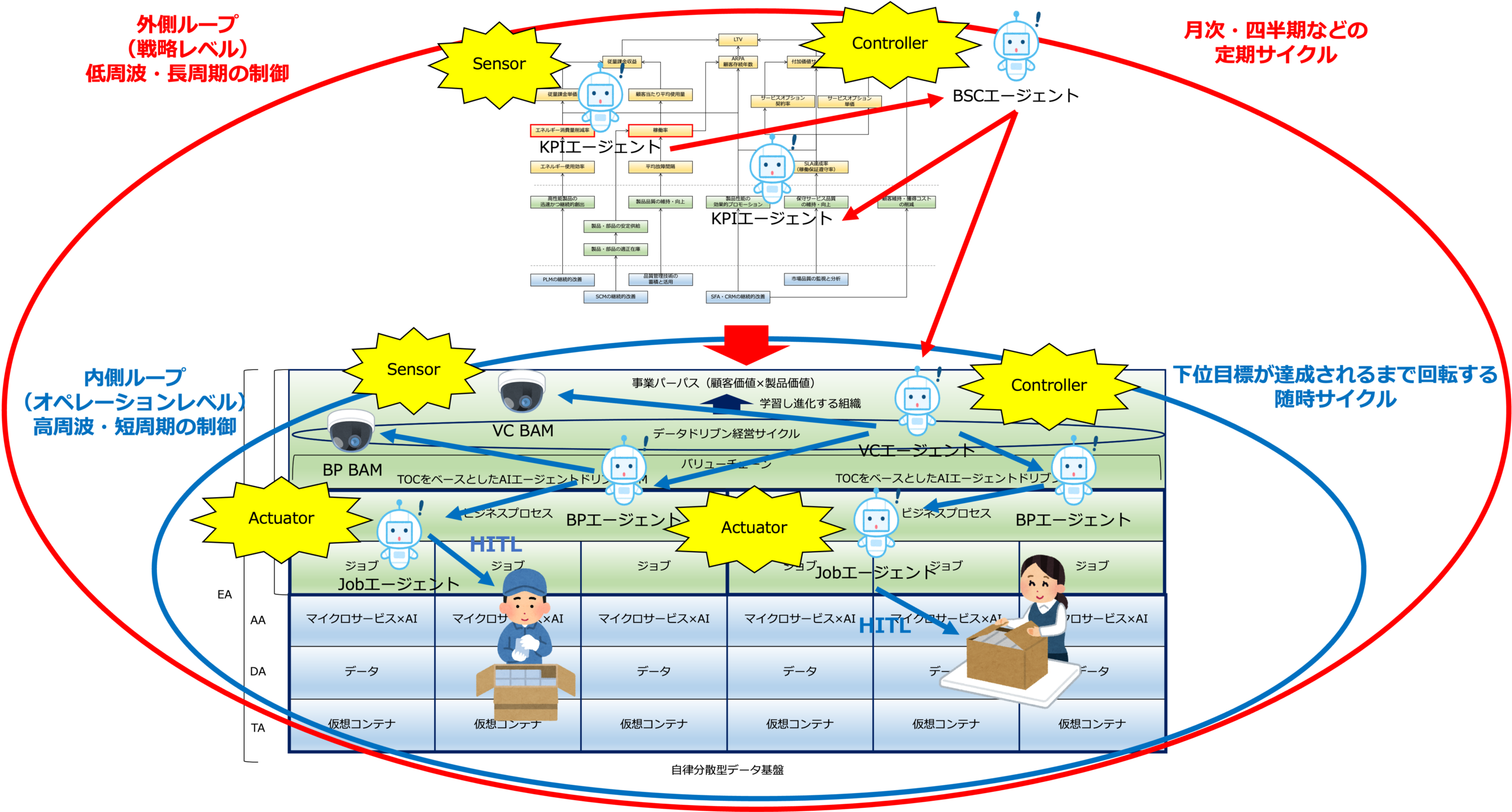
次の図は、AIエージェントドリブンBPMのイメージを表したものです。
経営の制御サイクル(階層型カスケード制御)


[…] 自律分散型データ基盤 | 楽水 より: […]
[…] 調整する、ホメオスタシスのような仕組みを実現することができます。 次の図は、自律分散型データ基盤のイメージ図です。 ここでは、ユースケースベースAPIを備えた別システムを […]