
ここでは、ITサービスマネジメントについて以下の観点で解説します。
ITサービスマネジメントとは
ITサービスとは
ITサービスとは、ITを利用する顧客のビジネスを支援するIT機能の集合体のことです。
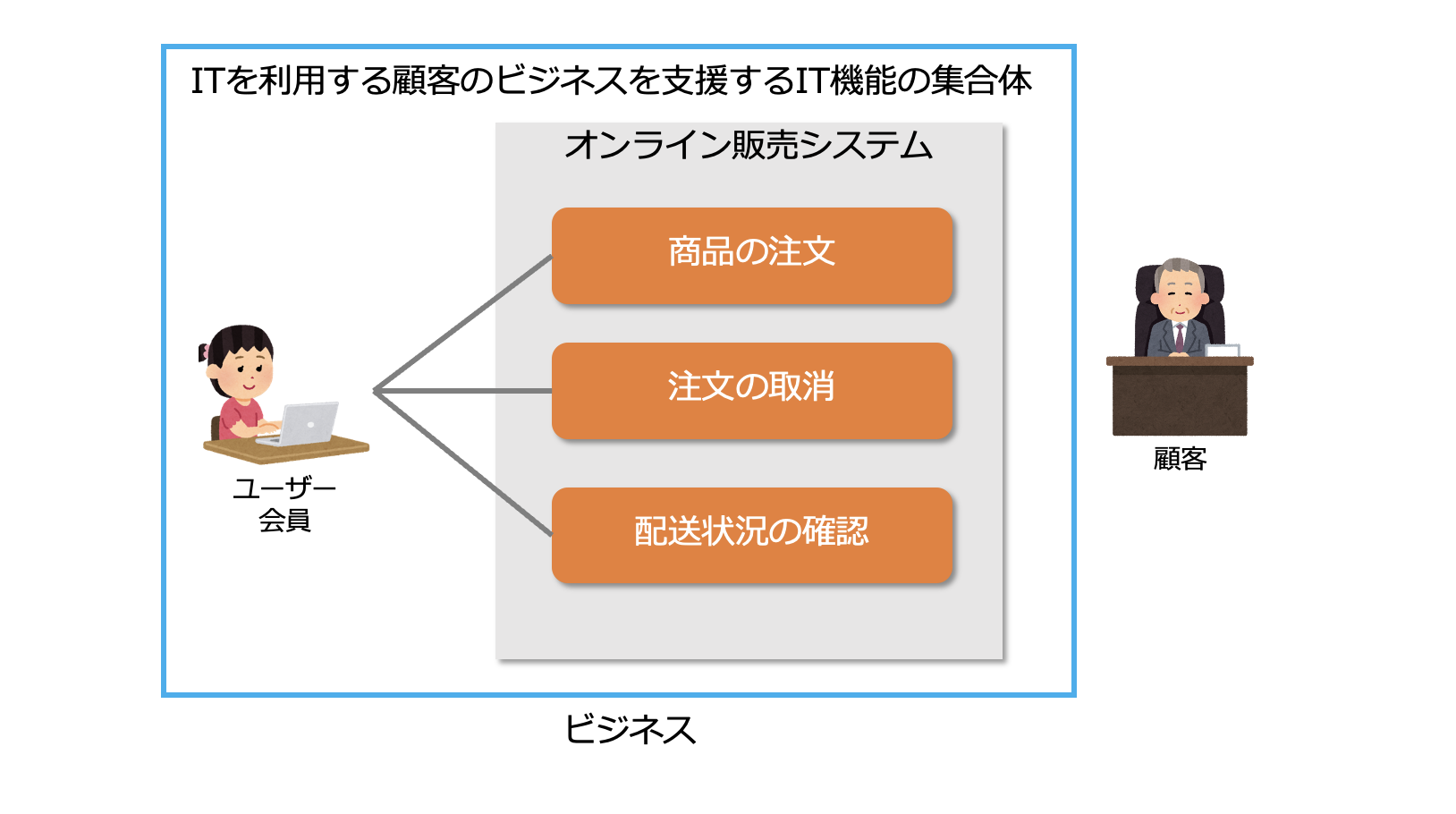
なので、ITサービスはビジネスを支援するための価値を提供するサービスです。
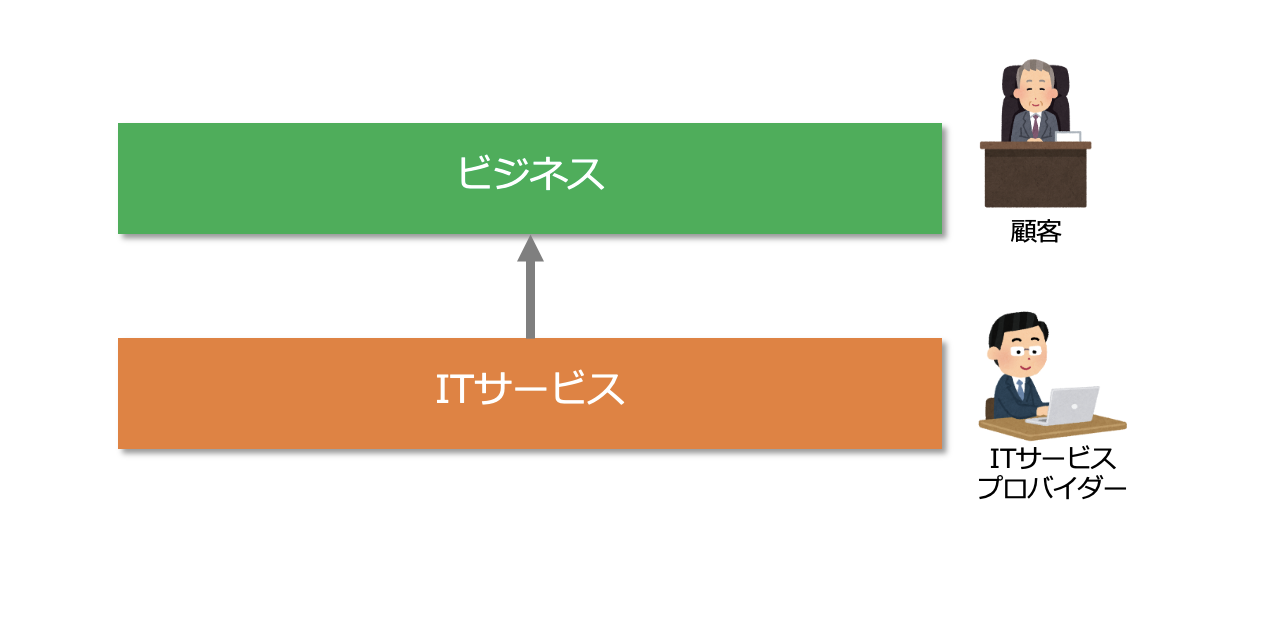
顧客とは、ITサービスの対価を支払う相手のことです。
顧客に、ITサービスを提供する役割(組織)をITサービスプロバイダーといいます。
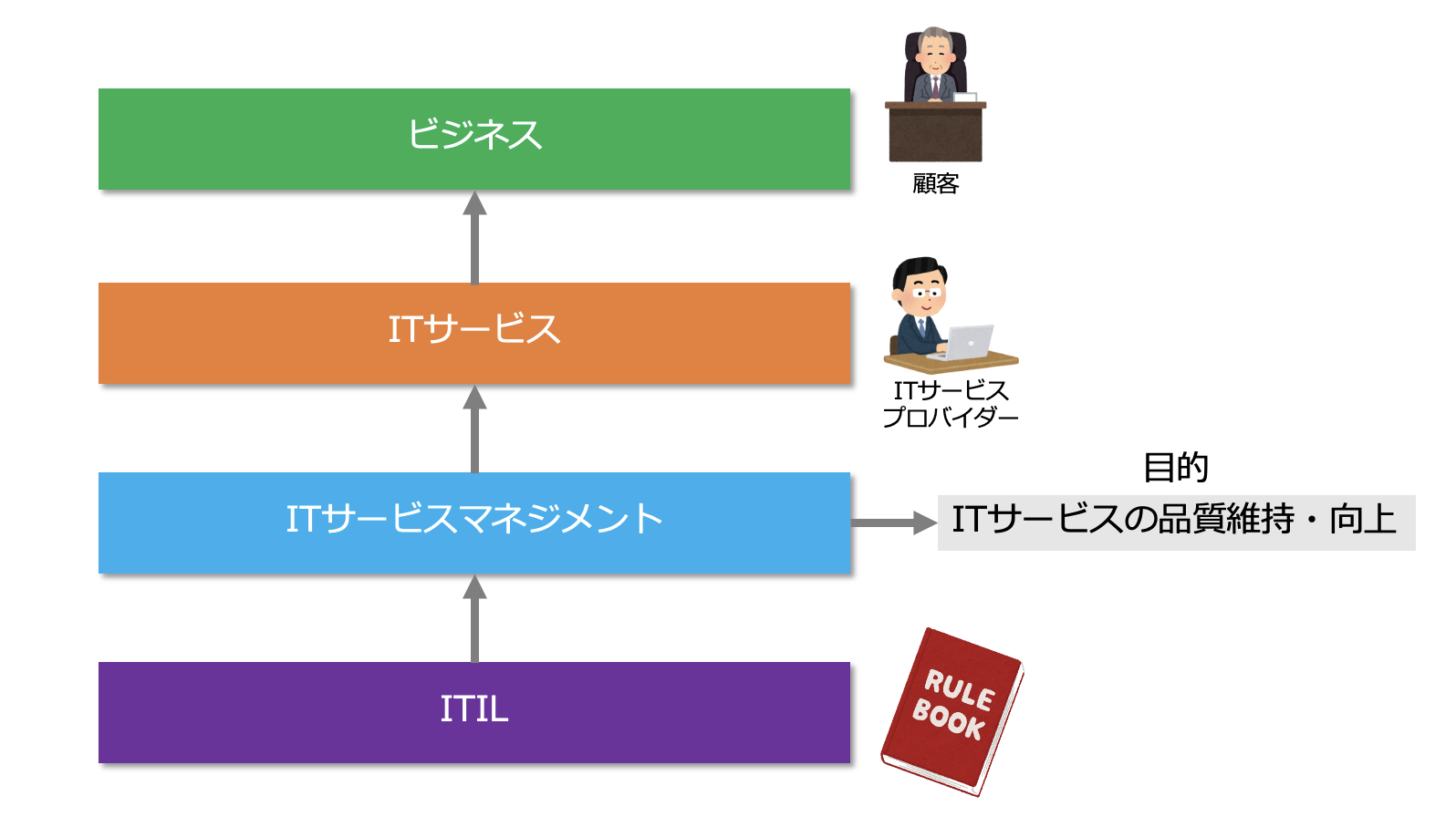
ITサービスマネジメントとは
ITサービスマネジメント(IT Service Management:ITSM)とは、ITサービスを提供する組織が、顧客ニーズとビジネス要求に合致したサービスの提供を実現し、その品質の継続的な改善を行うための仕組みのことです。
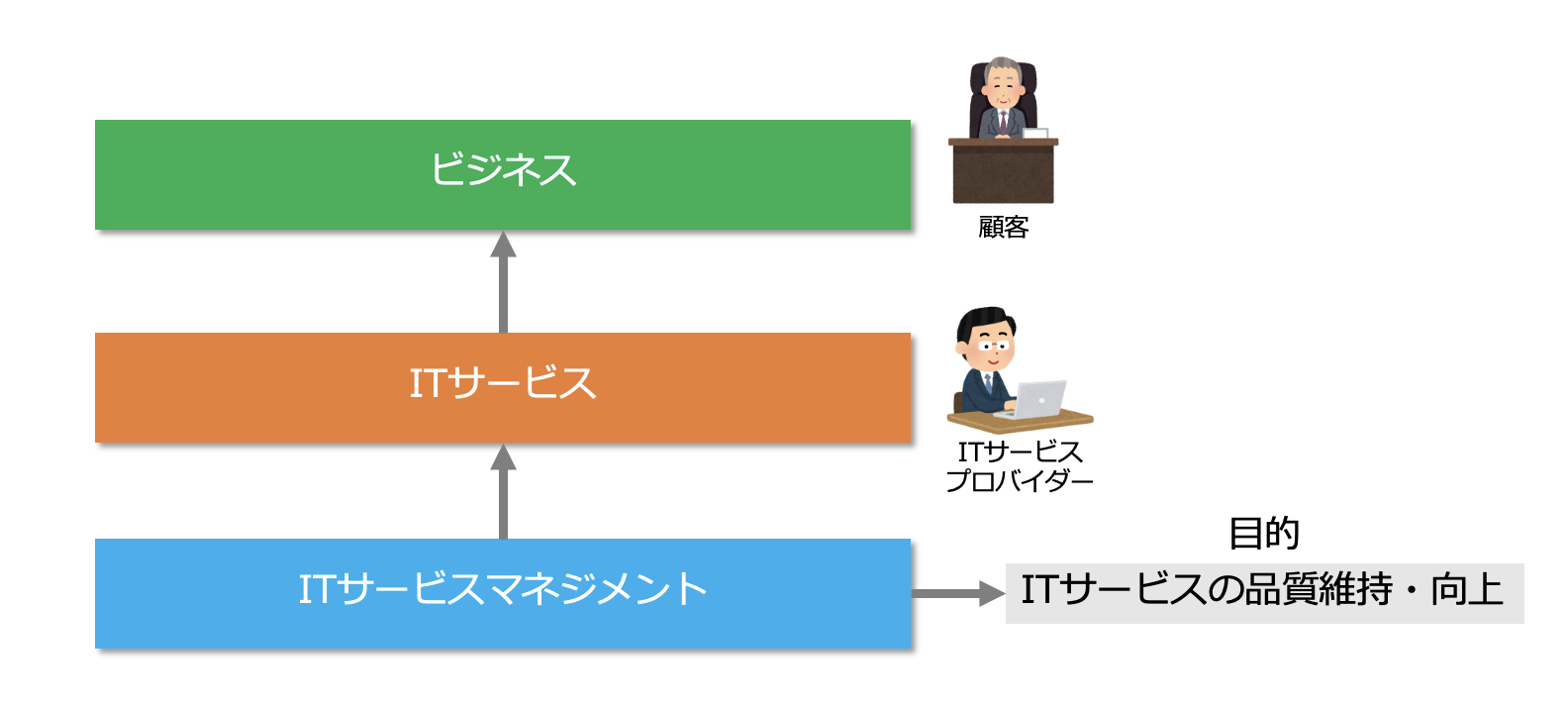
現代のビジネスはITと切り離して考えることが難しく、ITは、企業にとって新しいビジネスモデルや市場そのものを生み出す源泉となっています。
そのような状況下、ITサービスを効率的かつ効果的にマネジメントするITSMが重要になってきたのです。
ITILとは
ITIL(IT Infrastructure Library)とは、ITサービスマネジメントを実現するためのベストプラクティス(最善の実践方法)を集めたものです。
1989年に英国政府機関CCTAより初版が発行され、2019年にリリースされた第4班(ITILv4)が最新版になっています。
なお、本記事は、第3版(ITILv3)に基づいた内容になっています。
ITサービスマネジメントとバリューチェーン
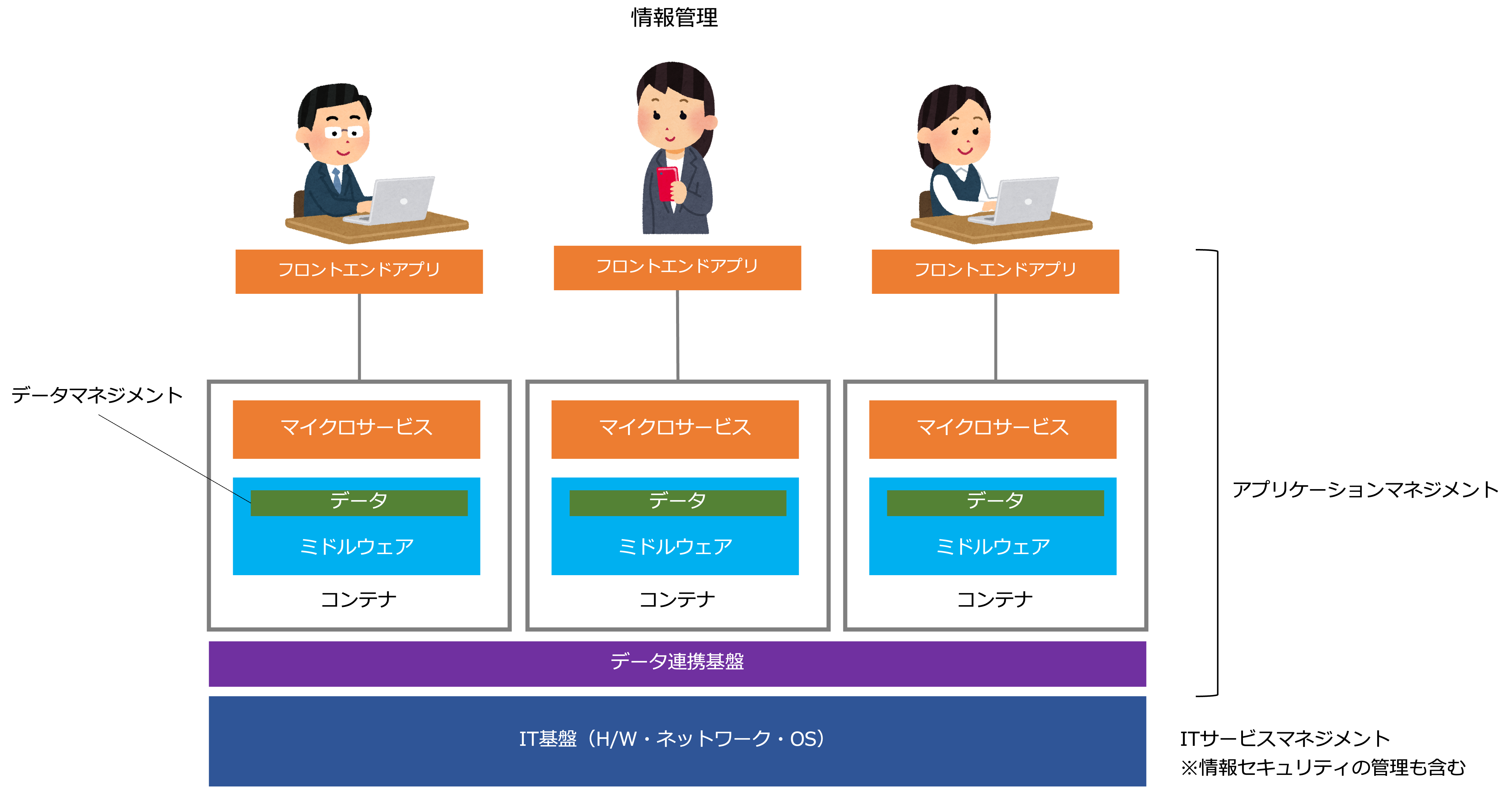
バリューチェーンを構成する活動の中でITサービスマネジメントをみると、情報管理の活動に該当します。

ここでは、次の図のように、情報管理の活動を
アプリケーションマネジメント
データマネジメント
ITサービスマネジメント
に分けて考え、ITサービスマネジメントは、IT基盤と情報セキュリティを管理する活動という位置づけで考えます。
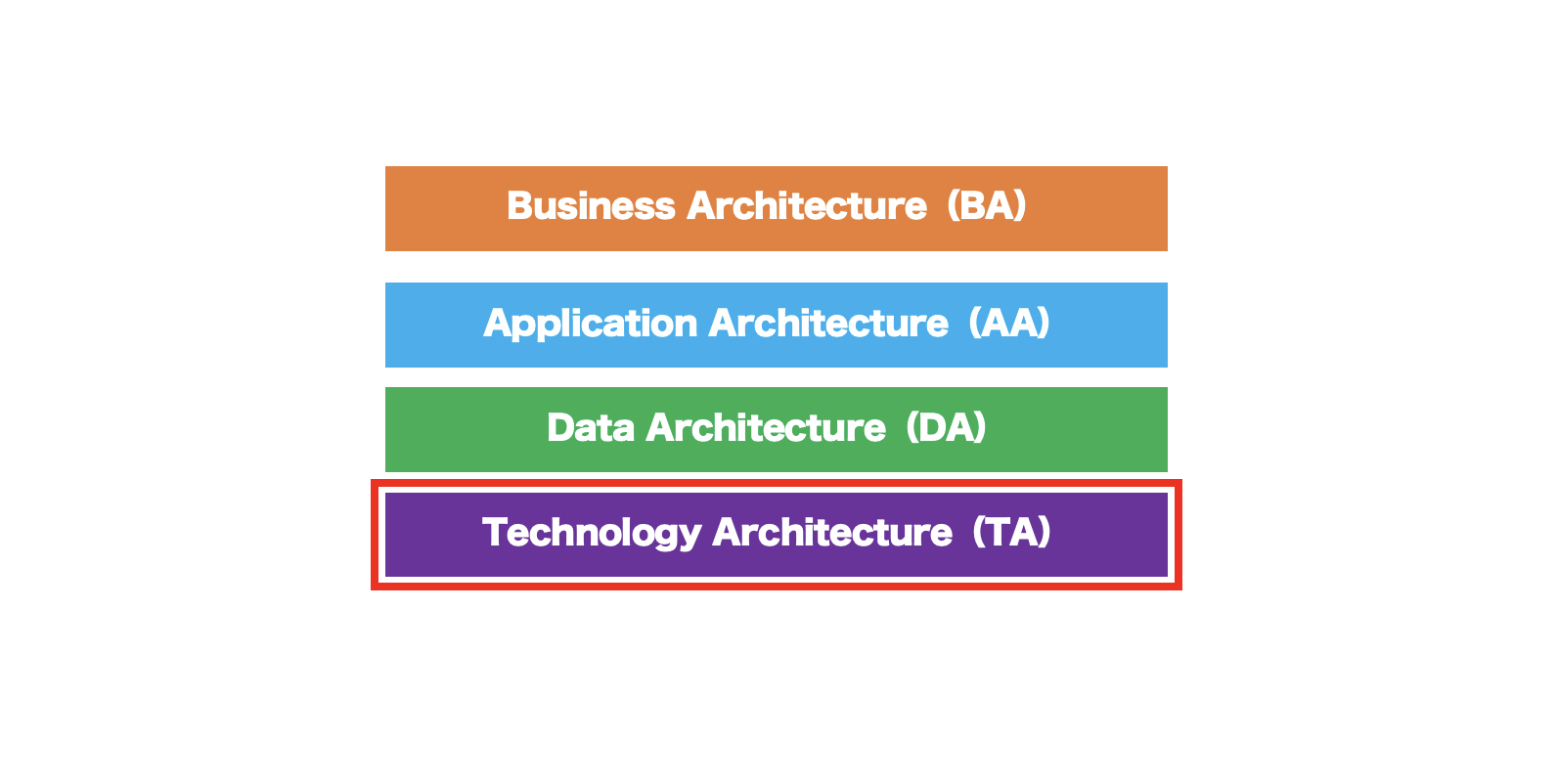
ITサービスマネジメントとEA
ITサービスマネジメントは、エンタープライズアーキテクチャ(EA)のテクノロジーアーキテクチャ(TA)に含まれます。
TAは、さらに物理インフラとマネジメントインフラに分けることができますが、ITサービスマネジメントはマネジメントインフラの一つになります。
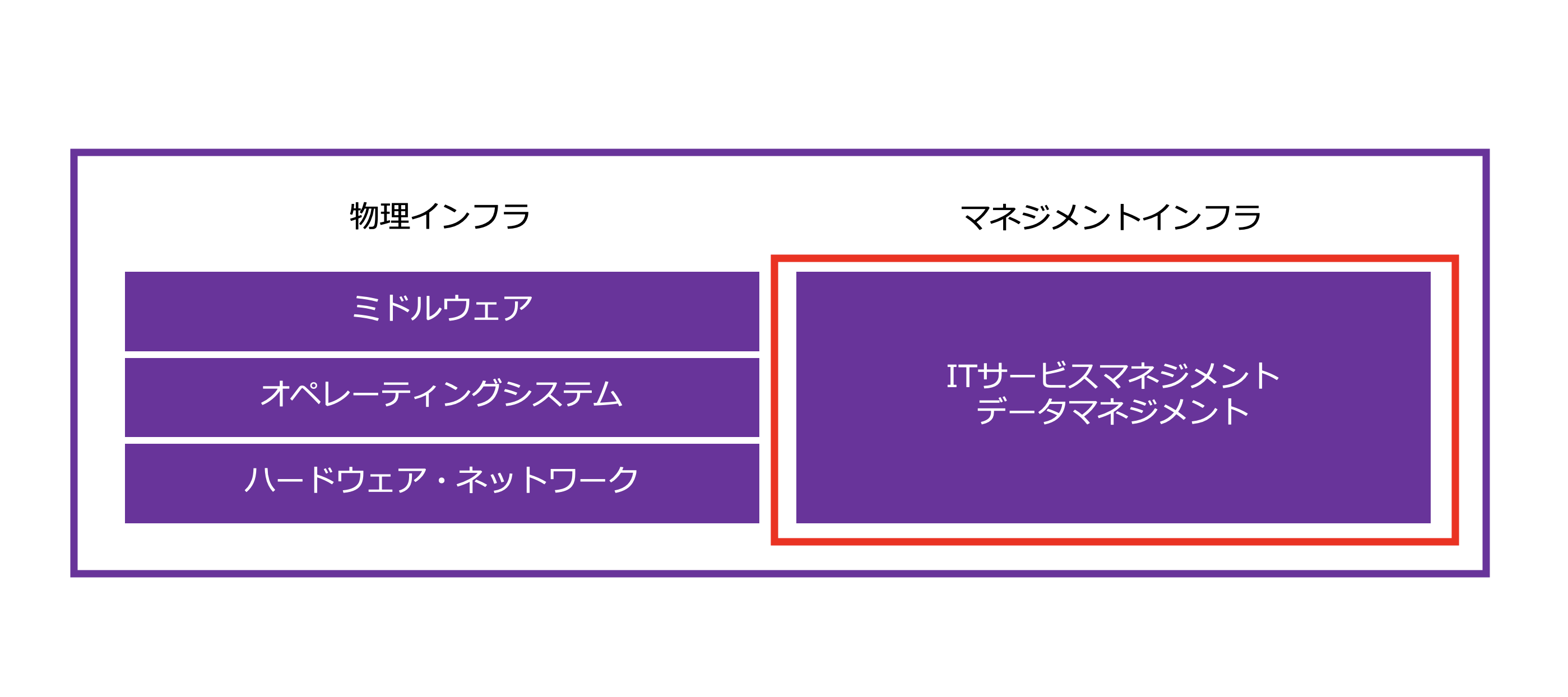
ITサービスとデータをいかにうまくマネジメントしてビジネスに活かすかが企業にとって重要な課題になっているのです。
ITサービスマネジメントの構成
ITILv3では、ITサービスのライフサイクルを次のように説明しています。
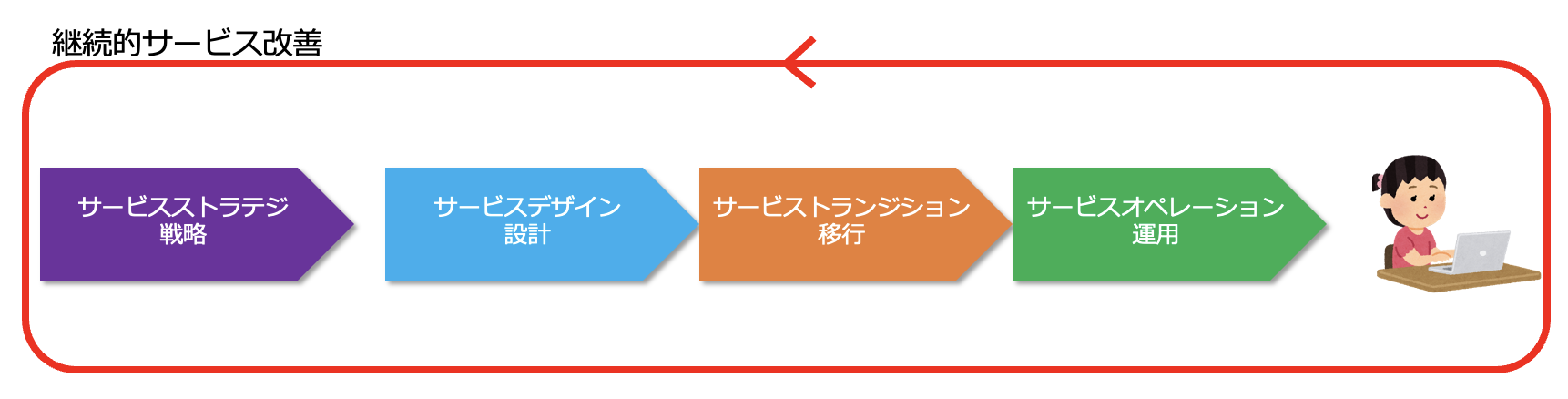
- サービスストラテジ(戦略)
顧客の事業成果を達成するためにどのようなITサービスを提供するか、それらのITサービスをどのように管理するか、ITサービスに関する戦略を決定する段階です。
需要管理、財務・コスト管理、ポートフォリオ管理、事業関係管理が含まれます。 - サービスデザイン(設計)
サービスストラテジで決定した戦略の実現に向け、新規ITサービスの投入や既存ITサービスの変更に向けた設計を行う段階です。
安全に本番環境に導入し、品質や顧客満足度、費用対効果の優れたITサービスを提供できるよう、プロセスおよび方針とともにITサービスを設計します。
サービスカタログ管理、可用性管理、キャパシティ管理、ITサービス継続性管理、サービスレベル管理、サプライヤ管理が含まれます。 - サービストランジション(移行)
サービスデザインで設計されたサービスを開発、変更し、ITサービスが運用できるように移行する段階です。
移行計画の立案、変更管理、サービス資産および構成管理、リリースおよび展開管理、サービスの妥当性確認、ナレッジ管理が含まれます。
なお、アプリケーションシステムを開発する工程(アプリケーション開発)は、変更管理やリリースおよび展開管理に含まれています。
ソフトウェア開発を高速化するため、ビルド、インテグレート、テストなどを自動化し、すぐに本番環境にリリース可能な状態にする手法にCI/CD(継続的インテグレーション/継続的デリバリ)があります。

- サービスオペレーション(運用)
サービスデザインで合意されたサービスレベルに基づき、顧客・ユーザーに対してITサービスを提供する段階です。
インシデント管理、要求実現、問題管理などのプロセスと、サービスデスク、技術管理、アプリケーション管理、IT運用管理の機能が含まれます。 - 継続的サービス改善
将来にわたって事業ニーズの変化に対応し、有効性、効率性の高いITサービスを提供し続けるために、提供しているITサービスのパフォーマンスを測定・分析、検証し、継続的な改善を行う活動で、他の4つのライフサイクルすべての段階で行われます。
このCI/CDを中心にして開発と運用を統合する手法にDevOpsがありますが、ITILv4では、DevOpsやアジャイル開発の原則も取り入れられています。
サービスストラテジ(戦略)
サービスストラテジ(戦略)では、中長期的に、どのITサービスにリソース(要員やコンピュータ資源)をどの程度配分するか決定します。
ITサービスはビジネスの目的を実現するための手段なので、それが所属する事業単位の戦略に連動します。
例えば、市場の占有率×成長率で事業単位の組み合わせを考える事業ポートフォリオに基づいて全社戦略を考える場合、投資対象となる事業単位に所属するITサービスが投資対象となり、投資レベルによってリソースの配分の程度が決まります。
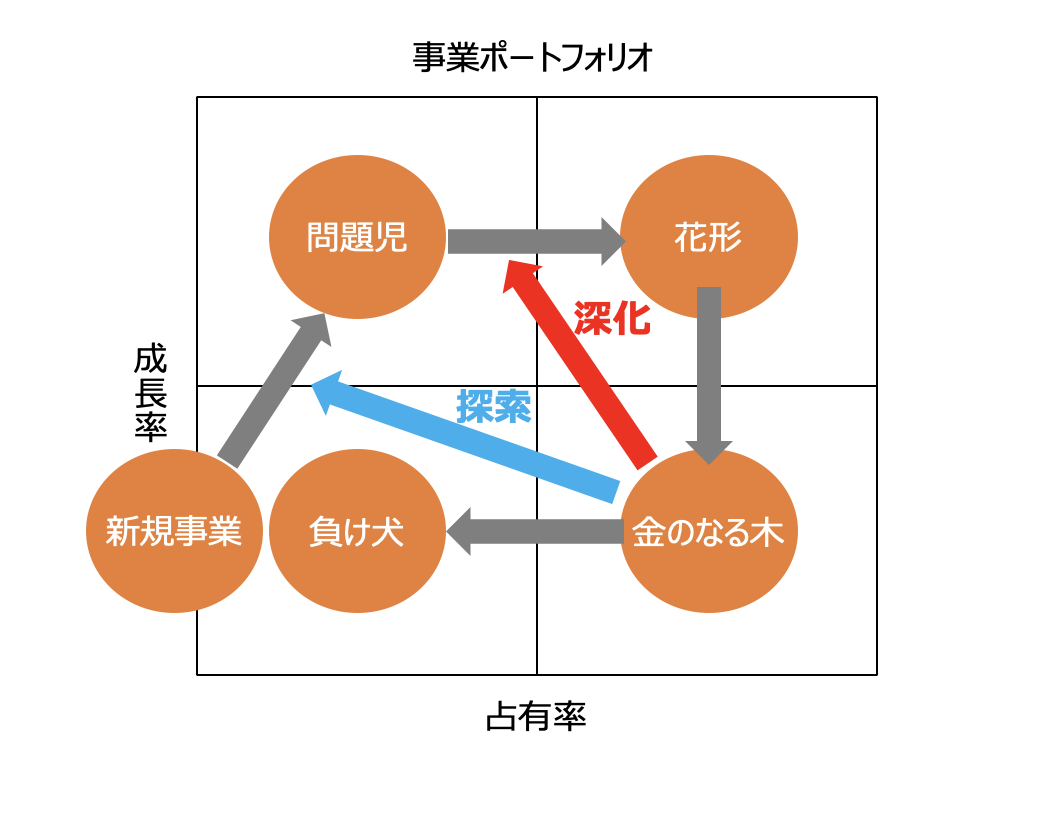
この例の場合、新規事業の成長を促す戦略(探索)と、次の花形をつくる戦略(深化)があり、それぞれに所属するITサービスが投資対象になります。
サービスデザイン(設計)
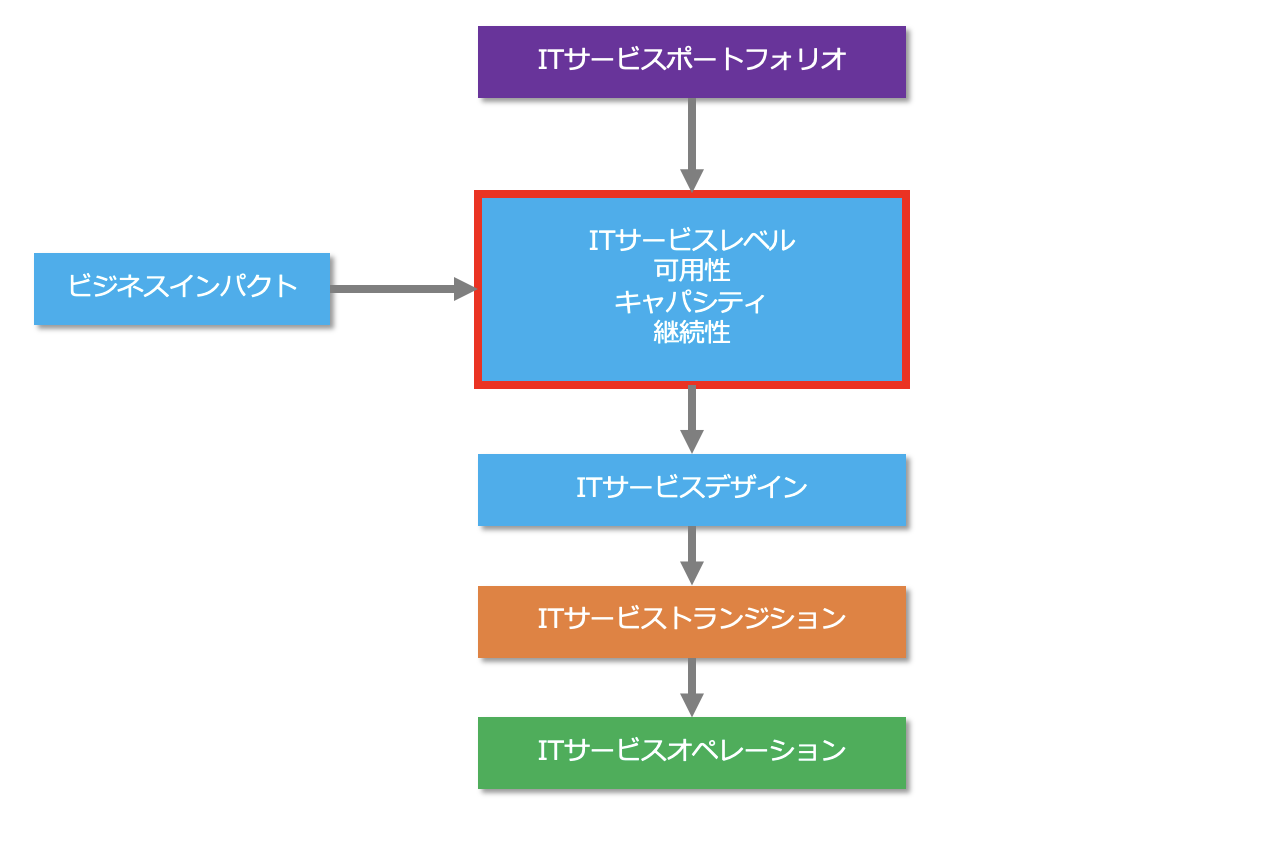
サービスストラテジ(戦略)によって、ITサービスに対するリソースの配分の方向性が決まるので、ITサービスのビジネスインパクトも考慮することで、各ITサービスにおける可用性、キャパシティ、継続性のサービスレベルが決まります。
そこで、サービスデザイン(設計)では、可用性管理やキャパシティ管理、継続性管理、情報セキュリティの観点でITサービスの基盤を設計し、具体的に必要なリソースを見積もります。
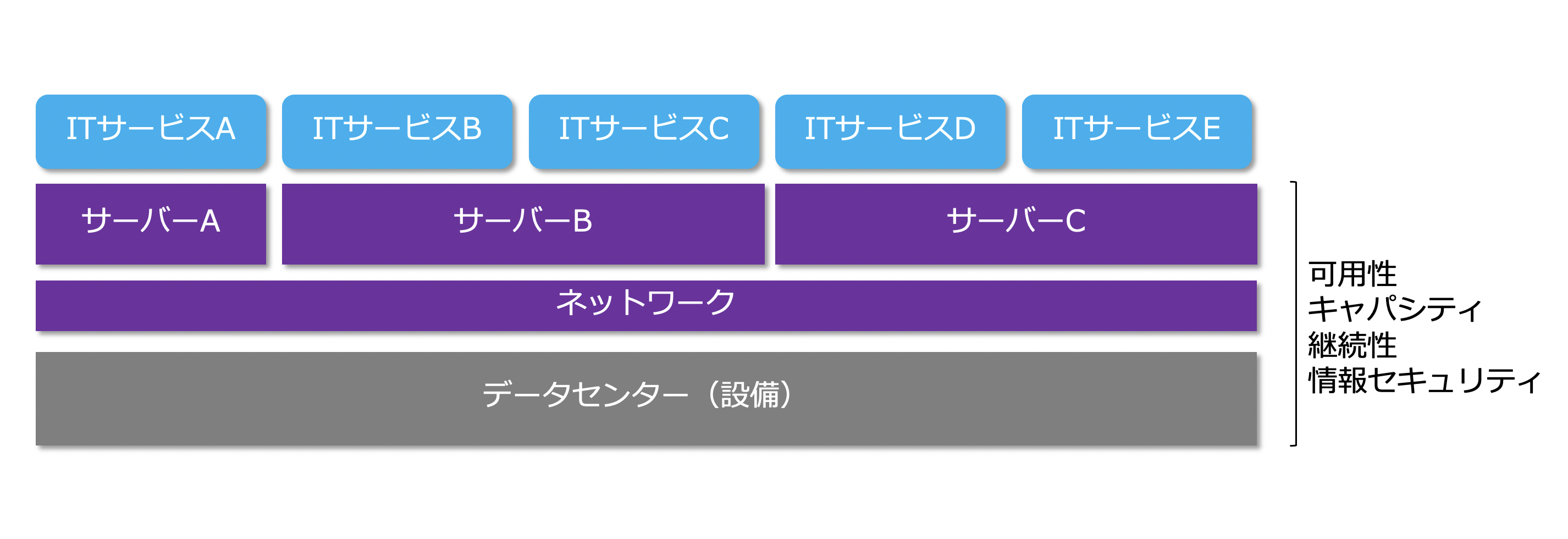
可用性管理とは、事業が必要なときにITサービスが使えるようにすることで、主にサーバー、ストレージ、ネットワーク、電源を冗長化することで稼働率を維持、向上させます。
キャパシティ管理とは、ITサービスのキャパシティ(収容能力)を確保することでパフォーマンス(実行能力)を最適にすることで、ディスク、メモリ、CPUなどの使用量を調整し、レスポンスタイムやスループットを最適化します。
継続性管理とは、災害やテロなどの不測の事態(コンティンジェンシー:Contingency)が発生した場合に、どのITサービスをどの程度継続させるかを管理することで、復旧計画の策定や復旧訓練を行います。
情報セキュリティ管理とは、情報漏洩やマルウェア感染といったセキュリティリスクに対して組織がどのように取り組むか方針をまとめ、ITサービスの機密性、完全性、可用性を管理することです。
サービストランジション(移行)
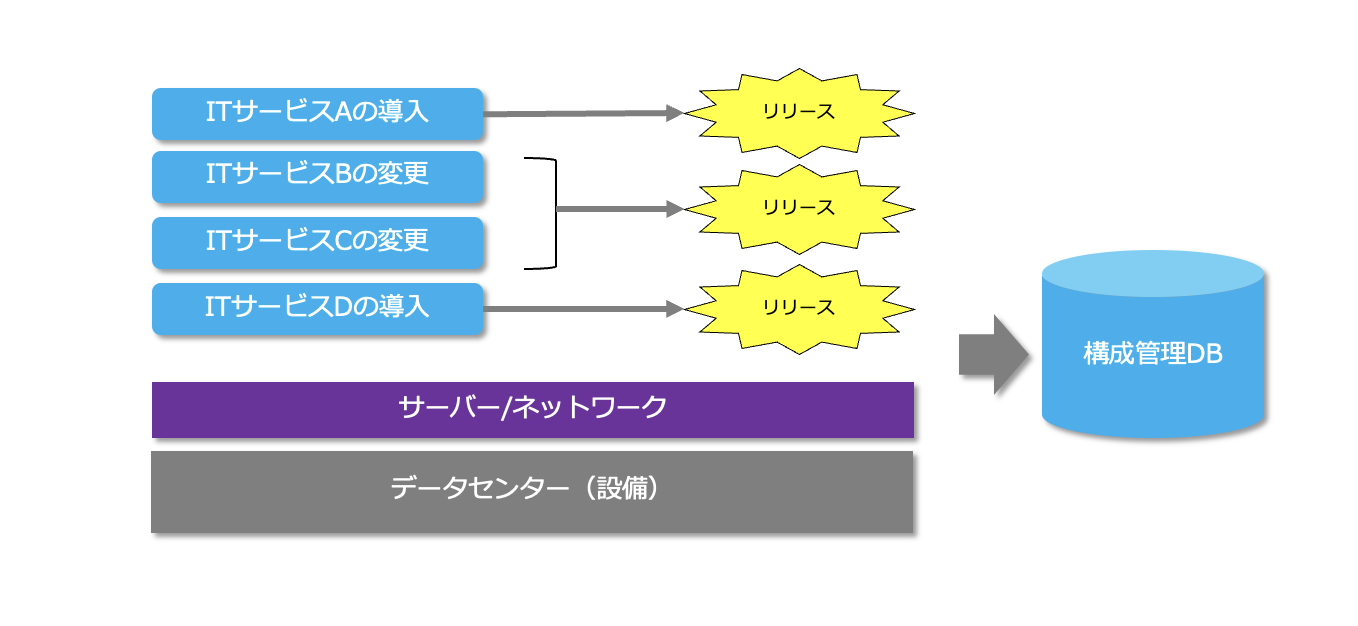
サービスデザイン(設計)でITサービスの基盤部分が設計されるので、サービストランジション(移行)では個々のITサービスを導入、変更し、リリースしていきます。
なお、ITサービスを移行する過程で、導入、変更されるITサービスの構成要素(ソフトウェア、ハードウェア、ドキュメントなど)の状態は、構成管理データベースに記録され、管理されます。
サービスオペレーション(運用)
サービストランジション(移行)でリリースされたITサービスを運用します。
定期的なコンピュータの処理やデータのバックアップだけでなく、サービスデスクを設けてユーザーからの要求やインシデントに対応します。
全体の流れを整理すると、ITサービスポートフォリオと、ITサービスのビジネスインパクトによって個々のITサービスのサービスレベルが決まるので、それを実現するためのITサービスを設計し、ITサービスを実装し運用します。
ITサービスマネジメントのプロセス
ここでは、ITサービスマネジメントを構成する個々のプロセスについて説明します。
サービスストラテジ(戦略)
事業関係管理
顧客との良好な関係を維持する
事業関係管理は、顧客である事業部門との良好な関係を保つためのプロセスです。
顧客との良好な関係を保つことで、顧客の潜在的なニーズを把握することができ、より適切なサービスを開発することができるようになります。
需要管理
ITサービスに対する需要を把握、予測する
サービスに対する顧客の需要を理解、予測し、キャパシティ管理と連携して、特定のサービスに必要な需要を満たすために十分な容量を確保します。
ITサービス財務管理
ITサービスにかかるコストを管理する
次の3つの業務があります。
- 予算
ITサービスにかかるコストを予測、計画し、会計の結果と比較してコントロールします。 - 会計
ITサービスにかかったコストを記録します。 - 請求
必要に応じて、ITサービスの代金を請求し回収します(任意)。
サービスポートフォリオ管理
ITサービスのポートフォリオを管理する
顧客(事業部門)からの情報を受けて、ITサービスの全体を把握し、規模や成長性などの観点で分類し、投資の優先順位を判断します。
ITサービスの情報は、ライフサイクルの段階ごとに分けて、次のように整理することができます。
- ITサービスパイプライン
検討中または開発中の全てのITサービスの情報。 - ITサービスカタログ
稼働中の全てのITサービスの情報。 - 廃止済みITサービス
稼働が終了した全てのITサービスの情報。
サービスデザイン(設計)
サービスレベル管理
ITサービスのサービスレベルが保証されるよう管理する
サービスレベルとは、ITサービスの品質をどの程度で提供するかを表し、その内容をSLA(Service Level Agreement)という文書に記載して、顧客と合意します。
SLAでは、ユーザーサポートレベルの他、サービスデザインで設計される
- 可用性
- キャパシティ
- ITサービス継続性
- 情報セキュリティ
のサービスレベルについて合意します。
サービスレベル管理のタスクは次のようになります。
SLAの導入
新規ITサービスを導入する都度、SLAを作成し合意します。
サービスレベルは、後述するサービスカタログで管理されます。
SLAの管理
各サービスレベルの実績値を確認し、顧客に報告します。
環境の変化などでSLAが遵守できなくなってきた場合は、顧客と適宜レビューを行いSALを見直します。
サービスカタログ管理
最新のサービスカタログを維持し、利用できるようにする
サービスカタログとは、顧客(事業部門など)に提供するすべてのITサービスの特徴、サービスレベル、関係する業務(部門)、課金の選択肢などを記述した文書です。
サービスカタログ管理のタスクは次のようになります。
サービスカタログの導入
既存サービス、新規サービスを整理しサービスカタログを作成します。
サービスカタログの管理
新しいITサービスの導入やサービスレベルの変更、既存ITサービスの廃止など、ITサービスのライフサイクルに合わせてサービスカタログを更新します。
可用性管理
事業が必要なときにITサービスが使えるようにする
ITILでは可用性について次のように定義しています。
可用性とは、ITサービス、または、その他の構成アイテムが、必要とさてたとき、合意済の機能を実行する能力。
可用性管理で重要なのはコストパフォーマンス(費用対効果)を考えて管理することです。
なので、
- 事業にとって本当に必要なITサービスは何か(サービスストラテジの策定)
- ITサービスが必要とされるタイミング(曜日や時間帯)
- その際、どの程度、使える必要があるのか(サービスレベル)
を顧客と話し合い、SLAとして合意する必要があります。
可用性を管理する際のポイントは以下です。
- 将来のサービス損失の予防
ITサービスの重要性の変化に応じて情報システムの脆弱性や冗長性を見直し(過剰な冗長化の排除など)、現在および将来に必要な変更要求を行う。 - 外部ベンダに対する契約の調整
外部ベンダ製品などは、外部ベンダと請負契約を適切に締結してサービスレベルを担保する。 - サービスを構成する要素の適切な保守
サービスの構成要素を把握し、個々の要素の故障状況などの非可用性を監視して適切な保守を行い信頼性の高い状態を保持する。
可用性要件の定義
ITサービス(システム)の要件定義の際、非機能要件の一つとして可用性要件を定義します。
可用性要件として定義すべきKPIの例は次のようになります。
- 可用性
可用性とは、SLAで合意した稼働時間に対し、実際にどのくらいの時間稼働するかを示します。
可用性は次のように測ることができます。
可用性=実際の稼働時間/合意した稼働時間
たとえば、月に200時間の稼働をSLAで定め、実際に稼働したのが198時間であれば、可用性は99%となります。 - 信頼性
信頼性とは、どれほど中断せずにシステムを利用できるかを示す指標です。
信頼性は次のように測ることができます。
MTBF=(使用可能時間-総停止時間)/停止回数
MTBSI=使用可能時間/停止回数
MTBFは「Mean Time Between Failure(平均故障間隔)」の略で、停止して回復した時点から、次に停止するまでの平均時間のことです。
MTBSIは「Mean Time Between Service Incidents(平均サービス間隔)」の略で、停止した時点から次に停止するまでの平均時間のことです。
なお、MTBSIには停止している間の時間が含まれますが、MTBFには含まれません。 - 保守性
保守性とは、システムが停止から回復する能力を示す指標です。
保守性は次のように測ることができます。
MTRS=総停止時間/停止回数
MTRSは「Mean Time to Restore Service(平均サービス回復時間)」の略で、一度の停止でどのくらいの回復時間を要するのかを示し、これが小さいほど保守性に優れていると言えます。 - 対障害弾力性
対障害弾力性とは、障害発生時に稼働を継続する能力(レジリエンス)のことです。
対障害弾力性が高ければ、たとえシステムの一部に障害が発生しても停止せずに済みます。
可用性要件を定義する際、次のような関連要素が定義されます。
- ITサービスが支える重要なビジネス機能
- サービス時間
- 時間帯別の重要性
- 可能な状態の定義(同時利用者数、許容される応答時間など)
- サービス中断による事業インパクト
また、可用性要件を受けて、可用性を維持するための可用性管理要件を定義しサービスレベルとして設定します。
可用性管理のKPIの例は次のようになります。
- 可用性の状況
サービスの稼働率
システムコンポーネント別の稼働率 - サービスレベルの管理
SLAにおける可用性事項のレビュー回数
SLAにおける可用性事項に対する違反件数 - 可用性の費用対効果
システム非可用性状態による事業損失
対障害弾力性の見直し回数
対障害弾力性の見直し、非冗長化による削減コスト
可用性管理のKPIは、月次レポートなどの報告内容として重視されます。
可用性の設計
ITサービス(システム)のシステム設計の際、可用性要件で定義された内容をどう実現するか設計します。
可用性の設計は次の手順で行います。
- 単一障害点の確認
まず、単一障害点がないか確認します。
単一障害点(SPOF:Single Point Of Failure)とは、冗長構成などによるバックアップ機能がなく、故障発生時にビジネスに重大な影響を与える可能性のある構成要素のことです。 - リスクの分析と管理
IT資産ごとに、「どんな価値があって(資産価値)」「どんな脅威があって(脅威)」「どんな脆弱性があるか(脆弱性)」という3つの観点でリスクを分析し、対策を講じて管理します。
次に各例を示します。- 資産価値
サービス中断時の事業インパクト(可用性要件として定義)など - 脅威
単一障害点における障害
陳腐化した旧技術における不具合
未成熟な新技術に潜在する不具合
キャパシティ不足やセキュリティ事故など - 脆弱性
バックアップがない
情報セキュリティ上の欠陥があるなど
資産価値、脅威、脆弱性の観点からリスクを分析し、管理する手法を、CRAMM(CCTA Risk Analysis & Management)といいます。
- 資産価値
- テスト要件の定義
可用性要件など非機能要件への対応は、一般的にシステム開発においけて配慮を欠きやすいので、テスト要件としてあらかじめ定義しておきます。 - 冗長化の設計
リスク分析の結果を踏まえて、重要なサービスの構成要素における単一障害点の冗長化や費用対効果の出ない冗長化の見直しなど行います。
冗長化の設計について具体的に説明します。- サーバー
サービスの可用性を高めるためには、まず、サービス提供の土台となるサーバーの冗長化が必要です。- オンプレミス
- 障害時に切り替える方法
オンプレミスでは、サーバーの予備機を用意し、障害時に切り替える運用が一般的です。
これには2台のサーバーでクラスターを組み、障害時には運用系から待機系に自動的に切り替えるホットスタンバイや運用系サーバーと同じサーバーを停止状態で用意しておき、障害時に待機系を起動して切り替えるコールドスタンバイといった手法があります。 - 常時稼働させる方法
障害時に切り替えるのではなく、常にサーバーを複数台稼動させておき、ロードバランサーを用いて分散処理させる方法もあります。この方法の場合、複数台のサーバーを使うためシステム全体の処理能力が高くなるというメリットもありますが、逆にシステムの性能が要求に対して過剰となってしまうこともあり、注意が必要です。また、ロードバランサー自体が新たな単一障害点(SPoF)とならないよう、考慮しなければなりません。
- 障害時に切り替える方法
- クラウド
クラウドでは、サーバーは仮想化されているため、自動フェイルオーバーが可能です。
これは仮想サーバーが動作している物理サーバーが停止した場合、自動的にほかの物理サーバー上で仮想サーバーを再起動する機能です。
自動フェイルオーバーが利用できる場合、ユーザーは物理サーバーの故障について一切考慮する必要はありません。
- オンプレミス
- ストレージ
ストレージは、故障時にサービスが停止するだけにとどまらず、重要なデータの喪失という危険性もはらむため、冗長化が特に重要な部分です。- オンプレミスオンプレミスでは、RAIDを利用してサーバー内でストレージを冗長化するのが一般的です。
その場合、RAIDを管理するコントローラーが単一障害点(SPoF)になってしまうため、1台のサーバー内にコントローラーを複数搭載して信頼性を上げるという構成がよく採用されます。
ストレージを格納する筐体自体を二重化し、ソフトウェアによって筐体間でデータをミラーリングするという構成もあります。
ミラーリングを実現するためには、「リモート・アドバンスト・コピー」や「PRIMECLUSTER GDS」などのソフトウェアが利用されています。 - クラウド
多くのクラウドでは内部で冗長化が行われています。
そのため、ユーザーがサーバー内であらためてRAIDを組む必要はなく、ストレージのメンテナンス時も無停止で利用できるようになっています。
- オンプレミスオンプレミスでは、RAIDを利用してサーバー内でストレージを冗長化するのが一般的です。
- ネットワーク
- オンプレミス
オンプレミスでは、ネットワークの経路を構成する個々の要素を冗長化し、障害時には経路を切り替えるのが一般的です。
このような冗長化を実現するため、
サーバーでは複数のNICを束ねて利用する
ネットワークでは複数の転送経路を確保する
複数のルーターで仮想的なルーターを構築する
といった対策がなされています。
また、データセンターとインターネットを接続する上位のキャリア回線も複数の系統を用意する必要があります。 - クラウド
クラウドでは、ネットワークはクラウド事業者によって冗長化されており、通常ユーザーが意識する必要はありません。
- オンプレミス
- 電源
電源が断たれるとハードウェアは停止してしまいますから、複数の電源を確保することはとても重要です。- オンプレミス
オンプレミスでは、サーバーの電源ユニットを冗長化することはもちろんサーバーラックに2系統の電源を引き込み、それぞれの電源ユニットに給電する構成を取ります。
こうすることで、電源ユニットの故障だけでなく、万が一の停電にも備えることができます。
しかし、そのためにはラックに複数系統の電源が引き込まれていなければならないため、データセンターによっては実現できない場合もあり、注意が必要です。また、停電に備えた緊急用の自家発電設備を備えているかといった点も、データセンターを選定する際の重要な基準となります。 - クラウド
クラウドでは、当然ベンダーの管理下にある部分のため、ユーザーが電源について意識する必要はありません。
- オンプレミス
- サーバー
リカバリの設計
予防しきれずに発生するサービス中断に対して、次のようにインシデントのライフサイクルを考慮した対策を講じます。
- インシデントの発生
インシデントが発生してから検出されるまでの時間を検出経過時間といいます。 - インシデントの検出
インシデントが検出されてから診断されるまでの時間を応答時間といいます。 - インシデントの診断
インシデントを診断してから構成要素が復旧するまでの時間を修理時間といいます。 - 構成要素の復旧
構成要素の復旧が始まって回復する(使用可能になる)までの時間を復旧時間といいます。 - サービスの回復
これらの時間がサービス回復時間の内訳になります。
なので、各時間をどのように短くするか、それぞれ策を講じます。
ダウンタイムの管理
サービスの稼働時にSALの可用性要件を遵守できるようダウンタイムを管理します。
ダウンタイムには以下のような種類があります。
- 定期保守のための計画停止
- インシデントの発生からクローズまで
- 変更、リリース実施のためにスケジュールされたサービス停止
キャパシティ管理
ITサービスのキャパシティ(収容能力)とパフォーマンス(実行能力)を最適にする
キャパシティ管理では、
ネットワークの帯域幅
サーバールームの広さ
IT部門の人数
など、サービスを構成する要素のキャパシティ(収容能力)だけではなく、
その結果としてのITサービスのパフォーマンス(実行能力)も管理しなければなりません。
キャパシティ管理は、常にビジネス需要に対して過不足のない最適なキャパシティを提供することを主眼に置いています。
なので、ビジネス需要を、個々のサービス構成要素(コンポーネントと呼びます)レベルの最適なキャパシティに落とし込む3段階のサブプロセスが定義されています。
- 事業キャパシティ管理
計画・導入に関わる部分であり、ITサービスが将来必要とするリソースとパフォーマンスを予測し、必要となるキャパシティを計画、実装するプロセス。 - サービス・キャパシティ管理
運用中のパフォーマンスを常に監視し、SLAなどの目標値を達成するよう改善していくプロセス。 - コンポーネント・キャパシティ管理
個別のコンポーネント(ハードディスクやメモリ、CPU等)の利用率の傾向やパフォーマンスを監視し、リソース不足などの問題を未然に防止するプロセス。
タイムリーで費用対効果の高いITサービスの処理能力の実現
というキャパシティ管理の目標を達成するためのポイントは次のようになります。
- 事業計画の理解とキャパシティ計画
中長期の事業計画から現在と将来にわたる事業のボリュームを把握し、ITサービスに求められるキャパシティやパフォーマンスを理解します。
将来も含めたキャパシティ計画を行い、ITサービスの処理能力の最適化を図ります。 - コストとのバランスや需要とのバランス
ITサービスのキャパシティを計画し、実装するにあたり、コストとキャパシティのバランスや需要と供給のバランスを考慮し、ITインフラへの無駄な投資を抑制します。 - モニタリングによる先行的な対応
ITサービスへの実際の需要やIT資源の使用状況を監視し、将来の能力不足への可能性など課題への対策を先行的に着手することで、事業にとってタイムリーな解決を図ります。
短期間の対処としてチューニングを行なったりIT資源を追加実装して増強を行なったりします。
キャパシティ要件の定義
ITサービス(システム)の要件定義の際、非機能要件の一つとしてキャパシティ要件を定義します。
キャパシティ要件として設定されるKPIには次のようなものがあります。
- サービスのKPI
- トランザクション量
- スループット
単位時間当たりに処理できるトランザクション量。 - レスポンスタイム
データを入力して応答が返るまでの時間。 - ターンアラウンドタイム
コンピュータに処理(ジョブ)を依頼してから処理結果が出力されるまでの時間。
- コンポーネントのKPI
- CPU使用率
- メモリ使用率
- ディスク使用率
- バッファヒット率
- ログインユーザー数
- ネットワークノード数
また、ITサービス稼働後、キャパシティ管理が有効に機能しているかどうか、活動が成功したかどうか、などを具体的かつ客観的に測るKPIは次のようになります。
これらのKPIはサービスレベルとして設定され、月次レポートなどの報告内容として重要視されます。
- キャパシティ計画の正確性を測るKPI
サービスの使用量
システムコンポーネント別使用量 - キャパシティ上の課題が事業にもたらす影響の抑制を示すKPI
計画外システム増強数
キャパシティ管理のSLA違反に対する予防対策数
性能障害によるインシデント件数
キャパシティ不足によるビジネス損失
アプリケーション・サイジング
ITサービス(システム)のシステム設計の際、サービスのキャパシティ要件で定義されたKPIの目標が実現できるよう、アプリケーションに関連するコンポーネントの容量を見積ります。
例えば、アプリケーションに求められるスループットをもとにCPU処理性能、メモリーサイズ、ディスクサイズなどを見積ります。
定期的キャパシティ管理
サービス(アプリケーションシステム)稼働中、以下のサイクルでキャパシティを管理します。
- 監視
キャパシティ要件で定義されたKPIを監視項目とし、定期的に、その実績値を測ります。
その際、各監視項目に、性能劣化や容量不足の判断基準となる閾値(Threshold)を設定し、閾値からの逸脱を監視します。
なお、監視作業自体は、ツールを使って自動化することができます。 - 分析
監視によって観測されたデータを以下の観点で分析します。- 事業のボリュームの変動予測と実際のサービス提供量との比較
- 正常域やサービスレベル要件と比較した傾向の把握
- 日次、週次、月次のピーク時間の把握
- 想定外のデータの検出と潜在的な問題の識別
- チューニング
分析で得られた課題に対して、次のような具体的な対応策を検討します。- トランザクション処理を追加されたサーバーに振り分けて負荷を分散する
- ストライピングなどでディスクのアクセス負荷を分散する
- 排他制御のレベルの調整(ロック待ちの解消)
- 物理メモリーの増強
- 実装
後述する変更管理やリリース管理を通してチューニング策を実装します。
ITサービス継続性管理
ITサービスに深刻な影響を与える可能性のあるリスクを最小にする
ITILにおけるITサービス継続性管理とは、
災害やテロなどの不測の事態(コンティンジェンシー:Contingency)が発生した場合に、
どのITサービスをどの程度継続させるか
を管理することです。
多くの企業では事業継続性管理を実施していますが、ITサービス継続性管理は、この事業継続性管理と連動します。
事業継続性管理(Business Continuity Management:BCM)
事業の影響を与える災害やテロなどの重大なインシデントを予測し、組織があらかじめ計画し訓練した方法で確実に対応するようにする管理プロセス。
ITサービス継続性管理のタスクは次のようになります。
ITサービス継続性要件の定義
SLAのサービスレベルとしてITサービス継続性要件を定義します。
サービスレベルとして設定されるKPIには次のようなものがあります。
- リスク低減の事業損失削減効果
- ITサービスのうち復旧時間の検証済み比率
- ITサービス継続性計画のテスト頻度(回/年)
- ITサービス継続性計画の監視とレビュー(回/年)
- 運用スタッフの訓練頻度(回/年)
ITサービス継続性計画の導入
ITサービス継続性計画には次のような内容があります。
- リスク低減手段の導入
UPSなど補助電源の導入、マシン構成の冗長化、ネットワークの多重化など可用性管理と協調して行います。 - スタンバイ対策の導入
バックアップサイト、スタンバイ設備を構築します。 - 復旧計画の策定
特に重要なサービスについて復旧計画を具体化します。 - 復旧手順の開発
技術的な復旧手順をドキュメント化します。 - 初期テスト
実際の運用に入る前に初期テストを行います。
ITサービス継続性計画の運用
ITサービス継続性計画の保証と維持のために次のような活動を行います。
- スタッフの教育と意識づけ
- 定期的なレビューと監査
- 定期的なテスト
- バックアップサイトへの変更管理
- 復旧訓練(トレーニング)
ITサービス継続性計画の発動
実際の救急事態時においてはITサービス継続性計画が発動されます。
情報セキュリティ管理
ITサービスが安全に利用できるようにする
情報セキュリティ管理とは、情報漏洩やマルウェア感染といったセキュリティリスクに対して組織がどのように取り組むか方針をまとめ、ITサービスの機密性、完全性、可用性を管理することで、情報セキュリティを確保するプロセスです。
- 機密性
機密性とは、適切な権限を持つ人物以外には情報にアクセスさせない状態のことです。
パスワードやIPアドレスなどでユーザーを識別し、許可がないユーザーのアクセスを排除する仕組みが求められます。 - 完全性
完全性とは、情報を改ざんさせない状態のことです。
これを確保する具体的な対策としては、情報の変更履歴の保存や操作制限が考えられます。 - 可用性
可用性とは、アクセス権を持つ人物にスムーズに情報を利用させられる状態のことです。
具体的には、バックアップやシステム二重化による災害・サイバー攻撃対策などを行います。
情報セキュリティ要件の定義
ITサービス(システム)の要件定義の際、非機能要件の一つとして情報セキュリティ要件を定義します。
情報セキュリティ要件は、SLAのサービスレベルとして設定します。
情報セキュリティ方針の策定
どのように情報セキュリティ要件を満たすか、その方針(ポリシー)を策定します。
情報セキュリティルールの策定
情報セキュリティ方針に従って、具体的にどのような対策を行うのか明確にします。
その際、現在のセキュリティ状況を把握し、保護すべきポイントを明確にします。
- 機密性に関するルール化のポイント
- アカウント追加・変更・削除の手順や承認フローは機能しているか
- システムを構成している各種リソースへのアクセス権が、目的通り維持出来ているか
- 機器、ファームウェア、オペレーティングシステム、ミドルウェア、アプリケーションに対する脆弱性はモニタリング出来ているか、脆弱性が発見された場合の修正の適用手順や承認フローは機能しているか
- 認証ログをはじめとしたセキュリティログは収集されているか
- 重要なデータは安全に保管出来ているのか
- ログイン管理を行い、不当に設定情報等が変更されない仕組みか
- 収集されているログからは、不自然な通信(業務利用外のURLへの定期的な通信、業務時間外の通信)や、通常の認証要求とは異なる特殊な操作要求が行われたことを検知できているか
- 適切なアカウント管理やアクセス制御は行われているか
- 完全性に関するルール化のポイント
- システムや機能を変更する際の操作マニュアルの更新手順や検証・承認フローは機能しているか
- システム構成が変更された場合の設計書類の更新手順や検証・承認フローは機能しているか
- システムや機能が変更された際の障害対応マニュアルの更新手順や検証・承認フローは機能しているか
- 設定情報、仕様書、マニュアル類の世代管理は行われているか
- サイトやシステムの改ざんを防御できているか
- 可用性に関するルール化のポイント
- システムが提供するサービス(機能)の正常性 と 異常性 が全て認識出来ているか
- サービス提供に必要な設備、ハードウェア、ソフトウェア、アプリケーション、サービスの状態をモニタリング出来ているか
- 地盤が固く地震に強い場所にDCを複数設置し、冗長化できているか
- 冗長化構成された機構のハードウェアやソフトウェアの状態をモニタリング出来ているか
- 冗長化されたシステム間でのデータ同期が正しく機能しているかをモニタリング出来ているか
- システムに障害が発生した際の切替動作を定期的に検証できているか
- 冗長化されたシステム間でのデータ同期に障害が発生した際のリカバリ方法を検証できているか
- 保管したデータからの復元が正しく行えることを定期的に検証できているか
情報セキュリティルールの導入
情報セキュリティルールを社内に浸透させるために社員教育などを実施します。
後述するアクセス管理を通して情報セキュリティルールが遵守されているか確認します。
サプライヤ管理
ITサービスのサプライヤを管理する
サプライヤー管理とは、サプライヤー(供給者)に関する様々な情報を取得し、それらの情報からサプライヤーを評価して、調達戦略の策定に活かすことです。
サプライヤー管理の管理項目には、製品の種類・価格等の基本的な情報だけでなく、過去の取引実績や納品品質、納期の順守率、契約書なども含まれます。
サービストランジション(移行)
変更管理
ITサービスがスムーズに導入、変更、終了できるよう管理する
変更とは、ITサービスに影響を及ぼす可能性のあるものを、追加、修正、削除することです。
変更の例には次のようなものがあります。
- 新しいシステムの導入
- サービスデスクのサポート時間の変更
- マニュアルの修正
- バグ修正パッチの適用
- ITサービスの終了
変更管理では、可能な限りITサービスを中断せず、スムーズに変更が遂行されるように管理します。
なお、変更の手続きは、構成管理と連携して、構成アイテムの状態変化をCMDBに反映させます。
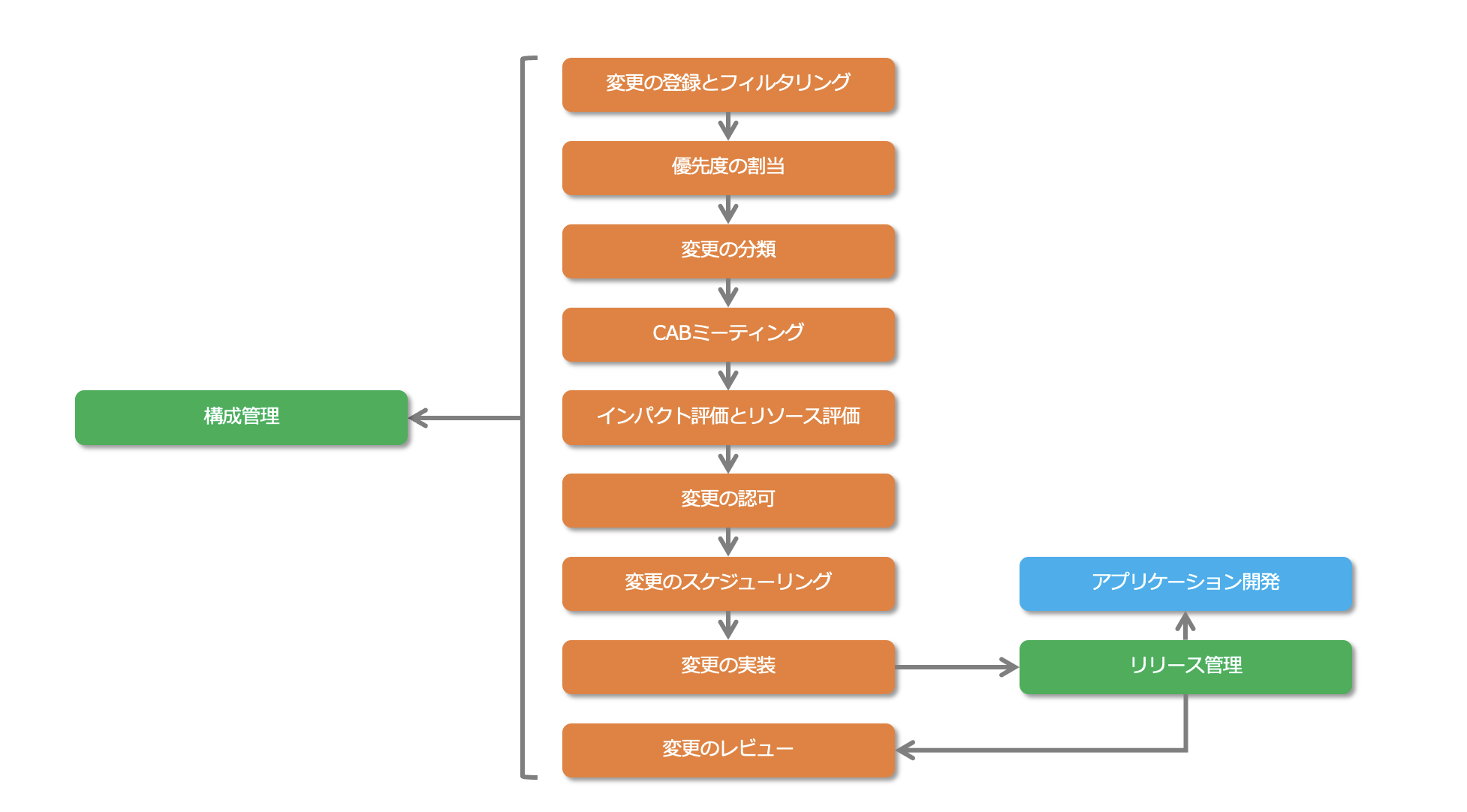
- 変更の登録とフィルタリング
問題管理やユーザーなどから受け取った変更要求(RFC:Request For Change)を記録し、定められた手順を踏んでない変更要求や非現実的なものに対して否認通知を返します。 - 優先度の割当
変更要求の緊急性に応じて優先度を割り当てます。 - 変更の分類
変更を実施する場合のサービスに与えるインパクトや必要なリソースによって変更を分類します。 - CABミーティング
変更の緊急性やインパクトにより、変更マネージャーはCABを招集します。
CABとは、変更諮問委員会(CAB:Change Advisory Board)のことで、ビジネス、技術、財務的な観点から変更要求に対して評価を行う権限を持った代表グループのことで、変更マネージャー、顧客、ユーザーの代表、アプリケーション開発者、技術アドバイザ、サポートスタッフ代表、外部ベンダーなどから構成されます。 - インパクト評価とリソース評価
変更要求に対してビジネス、技術、財務(費用対効果)の観点からインパクトとリソースの評価を行います。 - 変更の許可
インパクトとリソースの評価の結果を受けて変更の許可が行われます。 - 変更のスケジューリング
許可された変更に対して、緊急性や構築期間などを考慮して変更を、将来的な変更スケジュールとして関係者に共有します。
将来的な変更スケジュール(FSC:Forward Schedule of Change)とは、実行を許可された変更の詳細と実施予定日を含むスケジュールのことです。 - 変更の実装
許可された変更は、リリース管理を通してアプリケーション開発チームに受け渡されます。 - 変更のレビュー
変更の実装後、ある経過時間をおいて、CABミーティングなどを通して実装された変更のレビューを行います。
リリースおよび展開管理
ITサービスの構築、テスト、展開を管理する
リリースとは、一緒に構築され、テストされ、展開されるITサービスに対する一つまたは複数の変更のことです。
リリースには次の種類があります。
- フルリリース
リリースを構成するすべてのコンポーネントを同時にテストし、配布するリリースです。- デルタリリース
新たに変更されたコンポーネントのみを含むリリースです。- パッケージリリース
フルリリースとデルタリリースを複数まとめて行うリリースです。
変更管理で許可された変更を、スムーズに構築、テスト、展開し、変更の目的が実現できるよう管理することがリリースおよび展開管理の目的です。
展開とは、新規または変更されたハードウェア、ソフトウェア、文書、プロセスなどを稼働環境へ移行することを責務とする活動のことです。
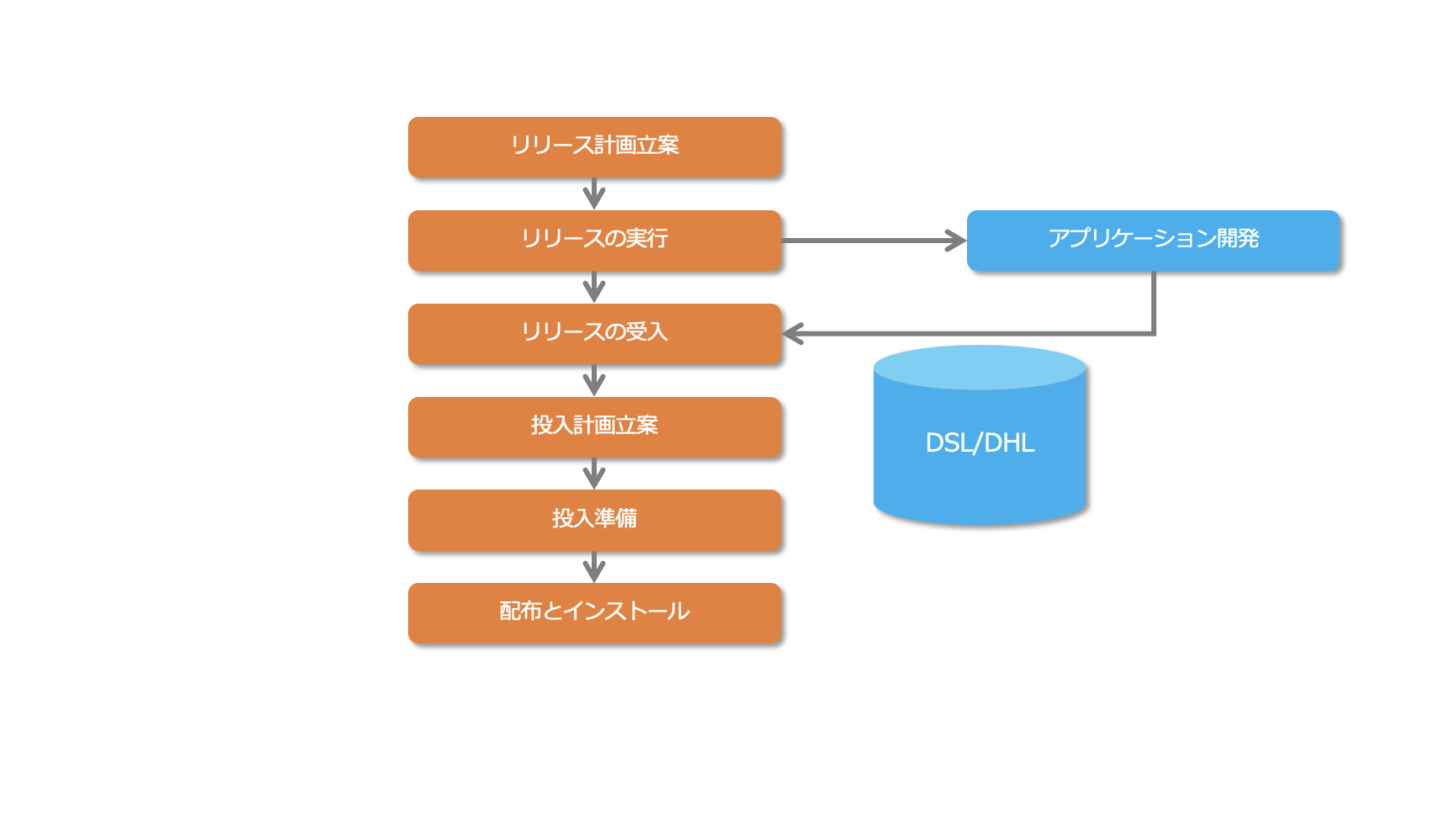
- リリース計画の立案
例えば、
フルリリースは年1回2月に実施する
デルタリリースは8月に実施する
など、リリースの頻度と規模の基本スケジュールを設けておきます。
ただし、緊急な変更が入る場合は、それに合わせてリリースを実施します。 - リリースの設計、構築、設定
リリースされる新バージョンのシステム開発や調達を行います。
その際、以下の成果物を作成します。- リリースされるコンポーネント(ソフトウェア、ハードウェア)
- 導入手順
- 自動化のための導入スクリプト
- 切り戻し手順(投入に失敗した場合に元のバージョンに復旧する手順)
成果物は、この時点でテスト用マスターコピーとしてDSL、DHLに保管されます。
- DSL(Definitive Software Library)
確定版ソフトウェア保管庫。
開発されるソフトウェアだけでなく購入したソフトウェアも含めて、企業に存在する承認されたすべてのソフトウェアのバージョンのマスターコピーを格納する物理的な保管庫のことです。 - DHL(Definitive Hardware Library)
稼働環境におけるハードウェアと同等の予備機器を安全に保管するための場所のことです。
- リリースの受入
DSLに保管されたマスターコピーに対してテストが行われます。
テストは独立したテストチームによって行われます。
以下のような成果物が作成されます。- テスト済のリリースされるコンポーネント(ソフトウェア、ハードウェア)
- テスト済の導入手順
- テスト済の自動化のための導入スクリプト
- テスト済の切り戻し手順(投入に失敗した場合に元のバージョンに復旧する手順)
- テスト結果
- 運用管理手順
- サポートスタッフやユーザーのトレーニング計画
- 投入計画立案
投入(Roll-out)とは、一連の新規、または、変更された構成アイテムをまとめ、論理的、物理的に組織にまたがって、提供、インストール、動作させる作業のことです。
受け入れられたリリースについて、稼働環境への物理的な配布や展開をする計画を立案します。
- 投入準備
ユーザーや顧客、サポートスタッフへのトレーニングなど含め投入前の準備を進めます。 - 配布とインストール
投入計画に沿って、DSLやDHLからソフトウェアの配布、ハードウェアの展開を行います。
サービス資産および構成管理
ITサービスの資産を管理し、正確な情報を必要なときに利用できるようにする
構成管理は、ITサービスを構成するすべてのアイテムの情報を管理し、他の活動に提供するプロセスです。
構成管理で管理される構成アイテム(CI:Configuration Item)には次のようなものがあります。
- ハードウェア
PC、サーバ、メインフレームなど。 - ソフトウェア
業務アプリケーション、パッケージソフト、DBMS、OSなど。 - サービス
提供される個々のITサービス。 - 関連ドキュメント
SLA、利用者マニュアル、運用マニュアル、導入マニュアルなど。 - 設備環境
構成アイテムが設置される物理的環境。
構成アイテムは、構成管理データベースで管理されます。
構成管理データベース(CMDB:Configuration Management Database)
各構成アイテムの詳細や構成アイテム間の関係についての情報を保管するデータベース。
構成アイテムのID、バージョン、稼働ステータスなどの属性だけでなく、構成アイテムに関連するインシデントレコードや問題レコード、変更要求などのレコードも関連付けされます。

ナレッジ管理
ITサービスに関するナレッジを管理する
ITサービスに関するあらゆる経験やノウハウをナレッジ(知識)として蓄積し、共有することでITサービスの品質を改善することができます。
サービスオペレーション(運用)
要求実現
ユーザーのサービス要求を迅速かつ確実に実現する
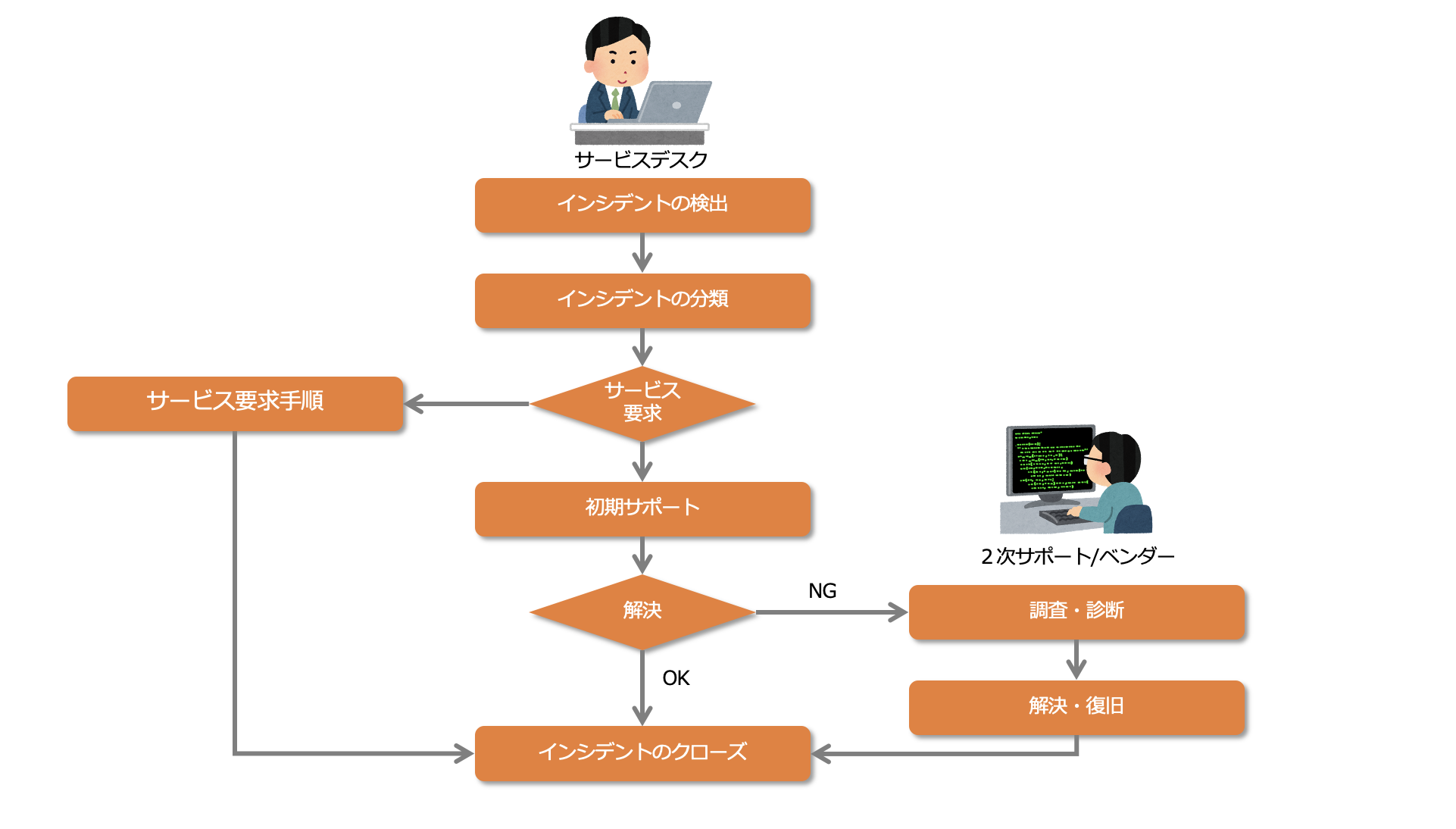
サービス要求とは、何かの提供を求めるユーザーからの正式な要求のことです。
例えば、情報の提供や助言、パスワードのリセット、新しいユーザーのためのワークステーションの設置依頼などがあります。
インシデント管理
インシデントに対する応急処置を行いITサービスの中断を短くする
インシデントとは、サーバーの中断またはサービスの品質低下を引き起こす可能性のあるイベントのことです。
ビジネス上の要求に対して合意したサービスレベルの解決時間内で、可能な限り迅速に(ASAP:As Soon As Possible)サービスを回復することがインシデント管理の目標です。
問題管理
インシデントの根本的な原因を取り除き、恒久的な解決を図る
問題とは、一つまたは複数のインシデントを発生させている未知の根本原因のことです。
問題管理は、インシデントの再発防止や未然防止に向けて根本原因を切り分け、恒久的な解決策を立案するプロセスです。
なので、インシデント管理が応急処置をするのに対して問題管理は恒久的な解決を図ります。
問題の根本的原因がわかった場合、これをエラーといい、変更管理を通してエラーの解決を図ります。

イベント管理
ITサービスのイベントを記録(システムログなど)、分析しITサービスの改善に活用する
イベントとは、ITサービスやその他の構成アイテムの管理にとって重要な状態の変更を伴う事象のことです。
例えば、サーバーやネットワーク機器で発生している事象は、正常も異常も含めてイベントとなります。
イベントを記録し保存しておくことで、インシデント発生時の障害の切り分けや、原因の調査分析の情報源として活用することができます。
アクセス管理
必要な人が必要なITサービスにアクセスできるようにする
アクセス管理とは、情報セキュリティ管理で策定した情報セキュリティ方針やルールを運用することです。
IT運用管理
ITインフラストラクチャの日常的な運用を行う
ITインフラストラクチャーを安定的に維持できるよう、日常的に、次のようなタスクを行います。
- コンソール監視
- ジョブスケジューリング
- バックアップ
- プリントおよびアウトプットの管理
- 保守活動
サービスデスク
サービスデスクは、インシデント管理の1次サポートを行う機能です。
技術管理
ITインフラストラクチャの運用を行うのに必要な技術やリソースの提供
ITインフラストラクチャの運用を行うのに必要な技術やリソースを提供します。
アプリケーション管理
アプリケーションを管理するのに必要な技術やリソースの提供
ITサービスマネジメントのライフサイクルをサポートするリソース、アプリケーションの管理に必要な技術力などの専門知識、アプリケーションの技術的障害を迅速に診断し解析する技術スキルの迅速な提供します。
【関連動画】



[…] ITサービスマネジメント導入プロセス […]
[…] ITサービスマネジメント […]
[…] 可用性要件 […]
[…] 、キャパシティ要件、ITサービス継続性要件、情報セキュリティ要件な […]
[…] 品質要件定義 アプリケーションの品質要件を定義します。 ITILの可用性要件の定義とキャパシティ要件の定義も合わせて参照してください。 […]
[…] 91;稼働している時間の割合を可用性(availability)とし、稼働率で測ることが […]
[…] プリケーションアーキテクチャとして、マイクロサービスアーキテクチャを考える場合、可用性要件、キャパシティ要件、ITサービス継続性要件、情報セキュリティ要件などの非機能要件 […]