
ここでは、リレーショナルスキームのデータモデリングについて以下の観点で説明します。
関連記事
データマネジメントの導入方法
データモデルとエンティティ
データとは、人や物、事象に関する事実を表したものです。
例えば、注文すると、その事実が注文データになります。
また、鉄塔があると、その事実が鉄塔データになります。
なので、データは、実体を表したもので、データそのものに実体があるわけではありません。
なので、データ同士の関係を表すデータモデルをつくる場合、データが表す実体をモデル化することになります。
ドイツの哲学者、ライプニッツは、
「本当に存在している」ものを、集合体と要素という観点から考えたとき、集合的に構成されたものは当然に、一次的に存在しているとは言えず、その構成要素から、その存在を受け取っているものと考えるほかないと、いうことは、ものを要素へと分割していけば、いつかは、「本当に存在している」ものでかつ「まったく要素を持たない厳密に単純な」ものへとたどり着くはずである、
とし、「まったく要素を持たない厳密に単純な」要素を実体(エンティティ)と考えました。
この場合、集合のほうを実体タイプ(エンティティタイプ)といいます。
しかし、データマネジメンチ知識体系(DMBOK)では、
「ジェーンは、従業員である」
といった場合、さきほどのライプニッツの定義だと、ジェーンがエンティティ、従業員がエンティティタイプになりますが、
「今日では、従業員をエンティティと考える方が一般的なので、集合をエンティティと考えることを推奨する」としています。
この場合、ジェーンは、エンティティインスタンスとなります。
ここでは、DMBOKに従って、集合、タイプのほうをエンティティ、要素、インスタンスの方をエンティティインスタンスとします。
データモデルの構成
DMBOKでは、データモデルの構成要素を
に分けて説明しています。
データモデルはER図を使って表現します。
ER図とは実体関連図(Entity-Relationship Diagram)のことで、エンティティ同士の関係でデータモデルを表す図です。
データモデルの表記法はいくつか種類があります。
次の図は、データモデリングスキーム(データを表現する方法)別データモデルの表記法をまとめたものです。

出典:データマネジメンチ知識体系(DMBOK)
ここでは、IE表記法(Information Engineering)とIDEF1X表記法(Integration Definition for Information Modeling)を、次のように組み合わせて使います。
- エンティティは独立エンティティと従属エンティティを分けて記述する(IDEF1X表記法)
- エンティティ名を長方形の上(外側)に書く(IDEF1X表記法)
- 主キーを長方形の1段目に、その他の属性を長方形の2段目に書く(IDEF1X表記法)
- 外部キーは属性名の後ろに(FK)を書く(IDEF1X表記法)
- リレーションシップは依存型リレーションシップと非依存型リレーションシップを分けて記述する(IDEF1X表記法)
- リレーションシップの多重度はIE記法で書く(IE表記法)
エンティティ
エンティティは、データが表す実体です。
クラス図では、参照オブジェクトのクラスでエンティティを表します。
エンティティのインスタンスは同一性を持つので、エンティティには識別子が必要です。
ここでは、次の図のように、エンティティの構成をエンティティ名、主キー、属性で表します。
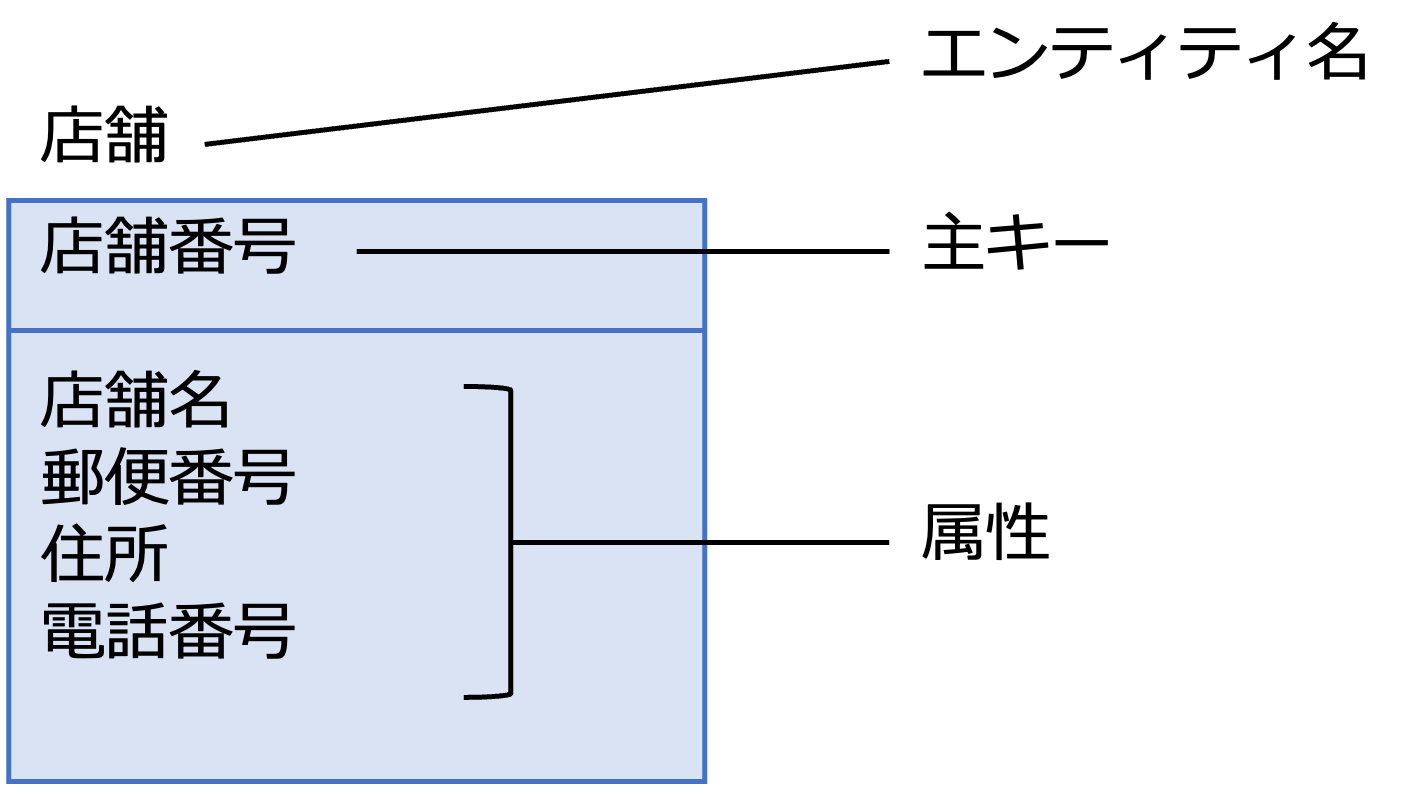
なお、クラスの場合、主キーの記載ルールはありません。
また、エンティティは、次のようにエンティティ名だけで描くこともできます。

リレーションシップ
次にリレーションシップについて説明します。
リレーションシップとは、エンティティ間の関連性を表す要素で、実線で表します。
リレーションシップは、クラス図の関連と同義です。
多重度
リレーションシップの多重度は、クラス図と同様、
一方のエンティティの一つインスタンスに対して他方のエンティティのインスタンスがいくつあり得るか、
その数を表します。
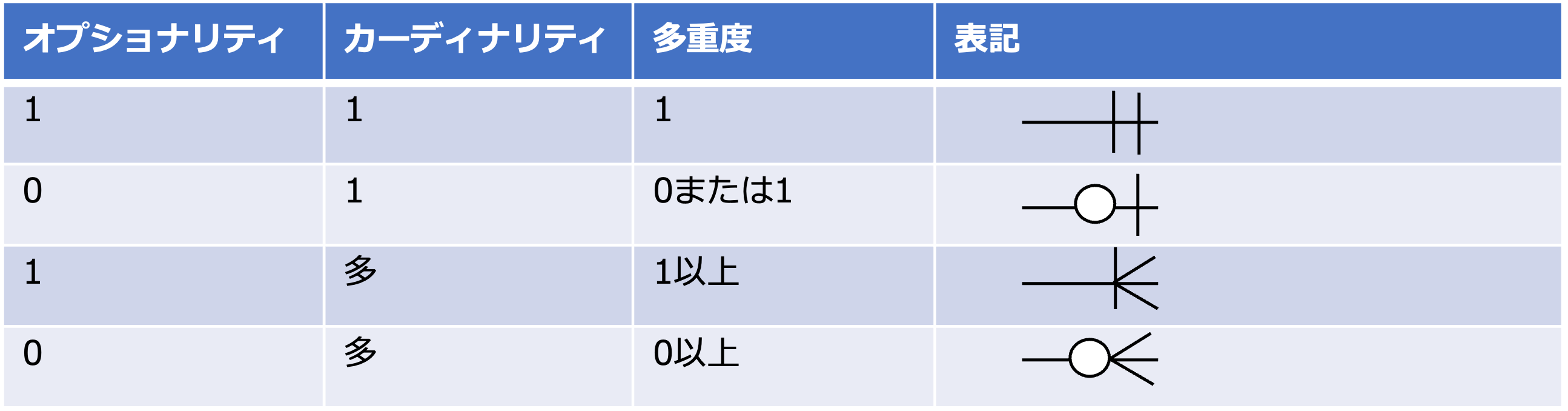
ここでは、IE表記法に従って多重度をカーディナリティ(cardinality)とオプショナリティ(optionality)を分けて記述します。
- カーディナリティ(cardinality)
基数、集合数。
エンティティから近い方に書きます。
関連付くインスタンスの最大数を1(棒線)か多(鳥の足)で表します。 - オプショナリティ(optionality)エンティティから遠い方に書きます。
選択性。
関連付くインスタンスの最小数を1(棒線)か0(丸)で表します。
1をmandatory(必須)、0をoptional(任意)と呼びます。
それぞれを組み合わせると次のような内容になります。
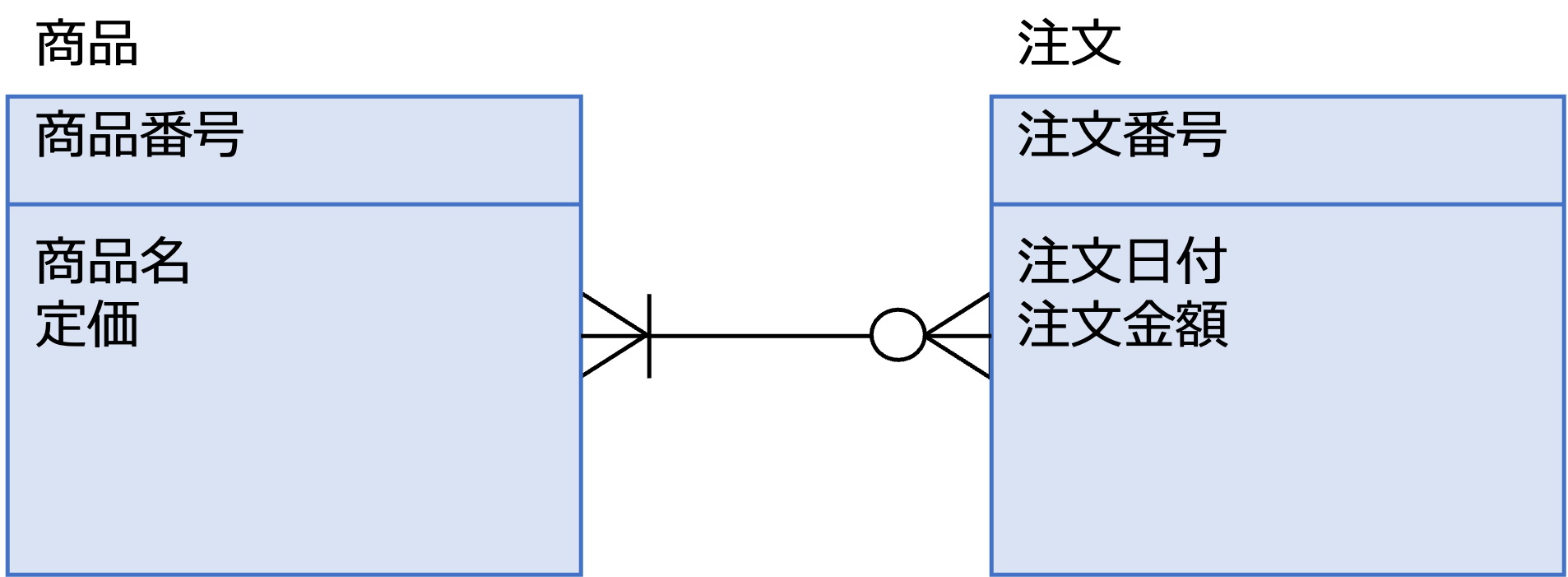
例えば、次のER図の場合、
注文エンティティ1インスタンスに対する商品エンティティのインスタンスが1以上(注文商品が存在しない注文はあり得ないので1以上)存在する、
商品エンティティ1インスタンスに対する注文エンティティのインスタンスは0以上(まだ一度も注文されていない商品もあり得るので0以上)存在する
ことになります。
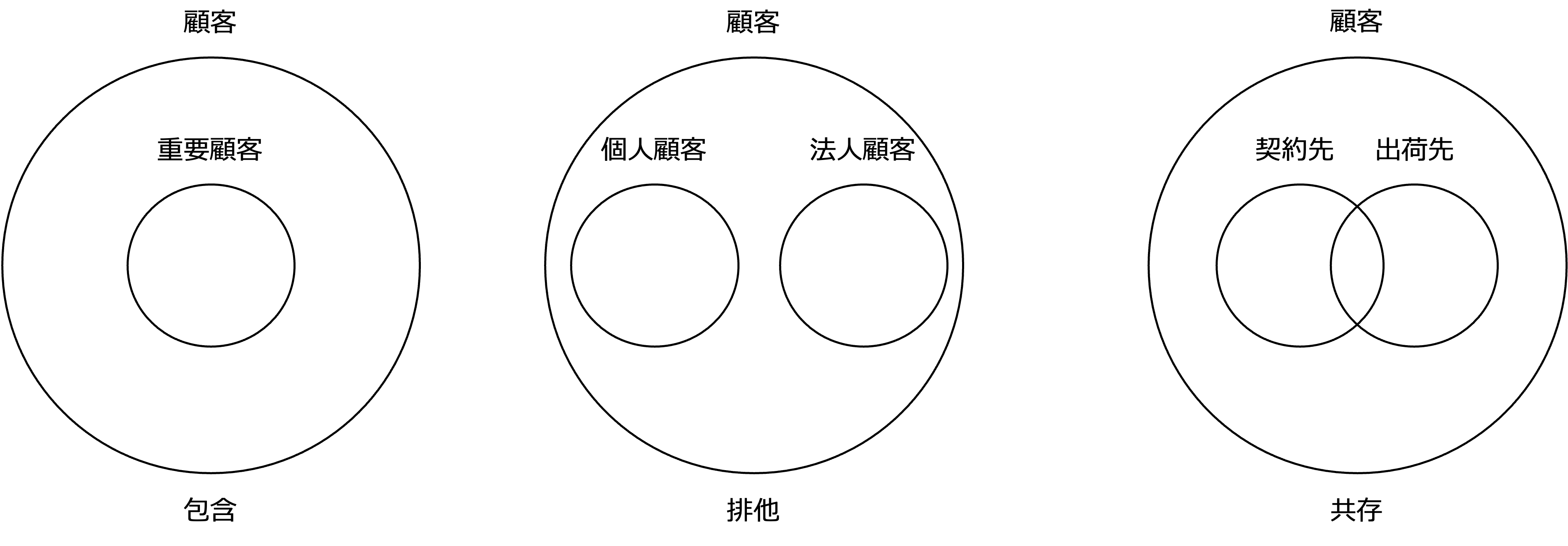
一般化
クラス図では汎化関係で概念を一般化することができます。
ここでは、ER図で一般化を表す場合の方法について説明します。
ER図では、より一般的な上位概念とより特殊な下位概念をスーパータイプとサブタイプの関係で表すことができます。
三角の記号は、クラス図同様、弁別子です。
サブタイプからスーパータイプを考える過程を一般化といいます。
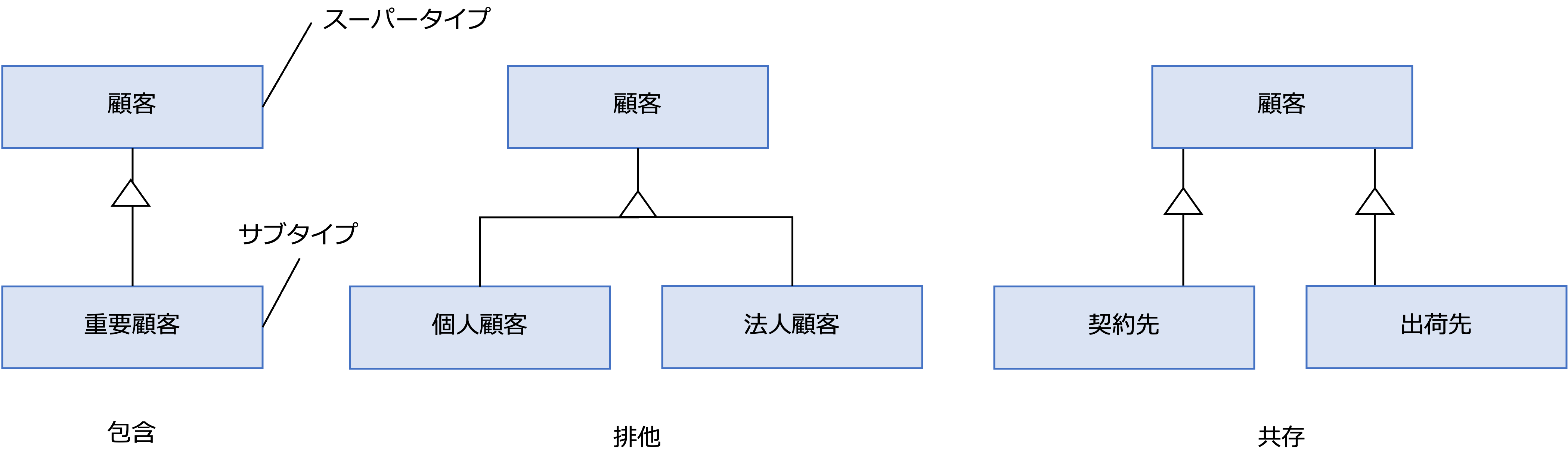
この図の包含、排他、共存は、次のように定義されます。
- 包含
サブタイプがスーパータイプの部分集合になることを表す。 - 排他
インスタンスが特定のサブタイプにしか属することができないことを表す。 - 共存
インスタンスが同時に複数のサブタイプに属することができることを表す。
属性
エンティティの属性は、クラスの属性と同様、エンティティの静的な特徴を表します。
識別子(キー)
エンティティの属性のうち、インスタンスを一意に識別するものが識別子(キー)になります。
DMBOKでは、識別子(キー)を構造と機能によって次のように分類しています。
構造による分類

機能による分類

なお、候補キーの中から主キーを選択するときの基準は次のようになります。
- データ量の小さいもの
主キーは検索のキーとして利用されたり、他の関係に参照のために格納されたりする確率が高いため、できる限りデータ量の小さい方がよいとされます。
よって、複合キーはあまり適しません。
データ量が多いキーしかない場合は、サロゲートキーを設けることがあります。 - 簡潔に間違いなく伝達できるもの
主キーは検索のキーとして利用されるほか、電話や書面で伝達されることも多いので、簡潔に間違いなく伝達できる形式であるのが望ましいとされます。
一定の桁数のアルファベットや数字からなる主キーは、この点でも優れています。 - 不変的なもの
主キーはその関係の外部(他の関係や、外部システム、ユーザなど)で識別子として利用される確率が高いため、不変 (immutable) であるべきです。
つまり、更新がかからない項目がよいとされます。
例えば、町村(町村ID, 町村名, 郡名, 都道府県名)というエンティティの場合、町村ID と {都道府県名, 郡名, 町村名} が候補キーになります。
この場合、上記3つの基準で考えると、町村ID が主キーとして選択され、{都道府県名, 郡名, 町村名} は代替キーになります。

外部キー
一方のエンティティの属性が他方のエンティティの属性を参照することで、2つのエンティティ間のリレーションシップを表すとき、参照元の属性を外部キーといいます。
外部キーは、エンティティ間の参照整合性制約になります。
参照整合性制約とは、参照元の属性と参照先の属性の値に一貫性がある(不整合がない)こと(参照整合性)を保証する制約のことです。
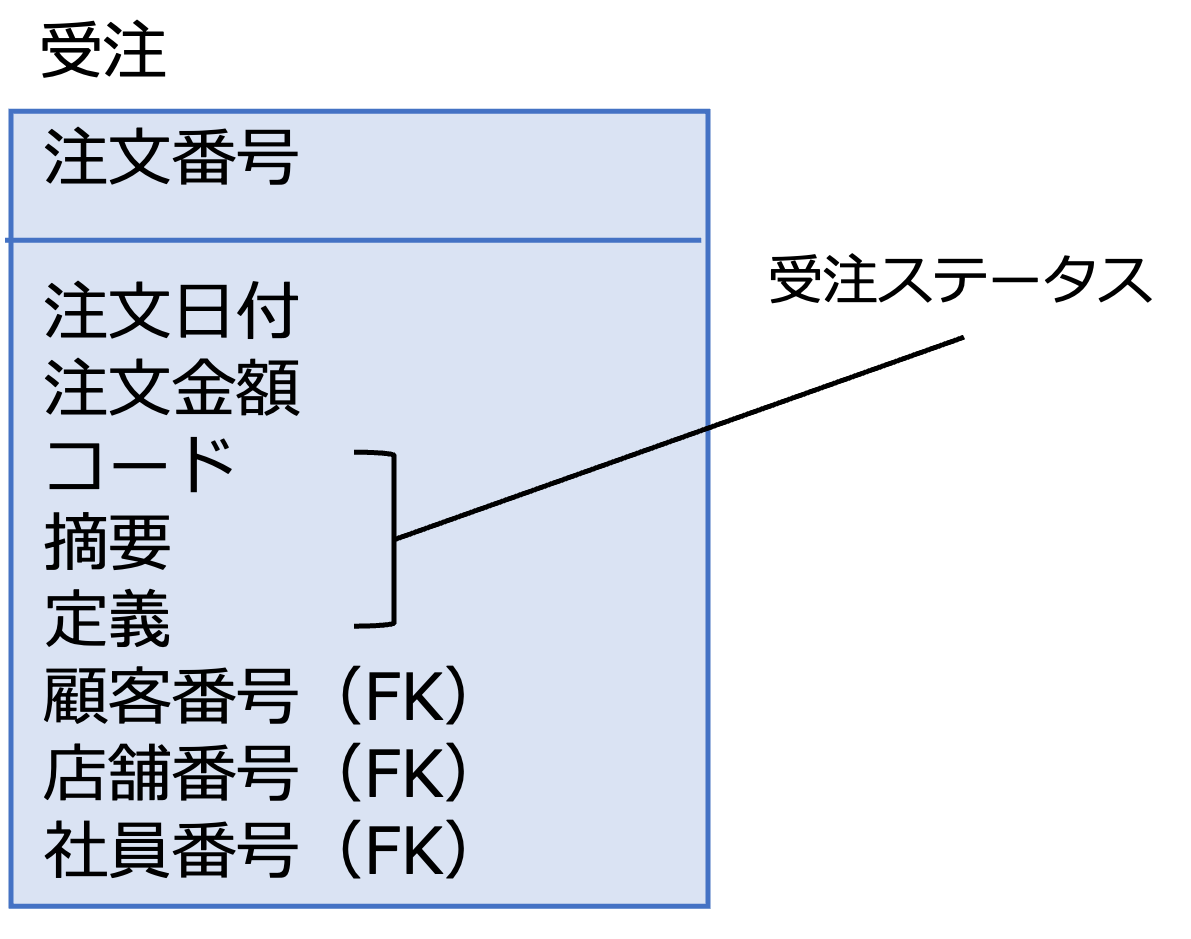
外部キーは、次の図のように、属性名の後ろに(FK)を書くことで定義します。
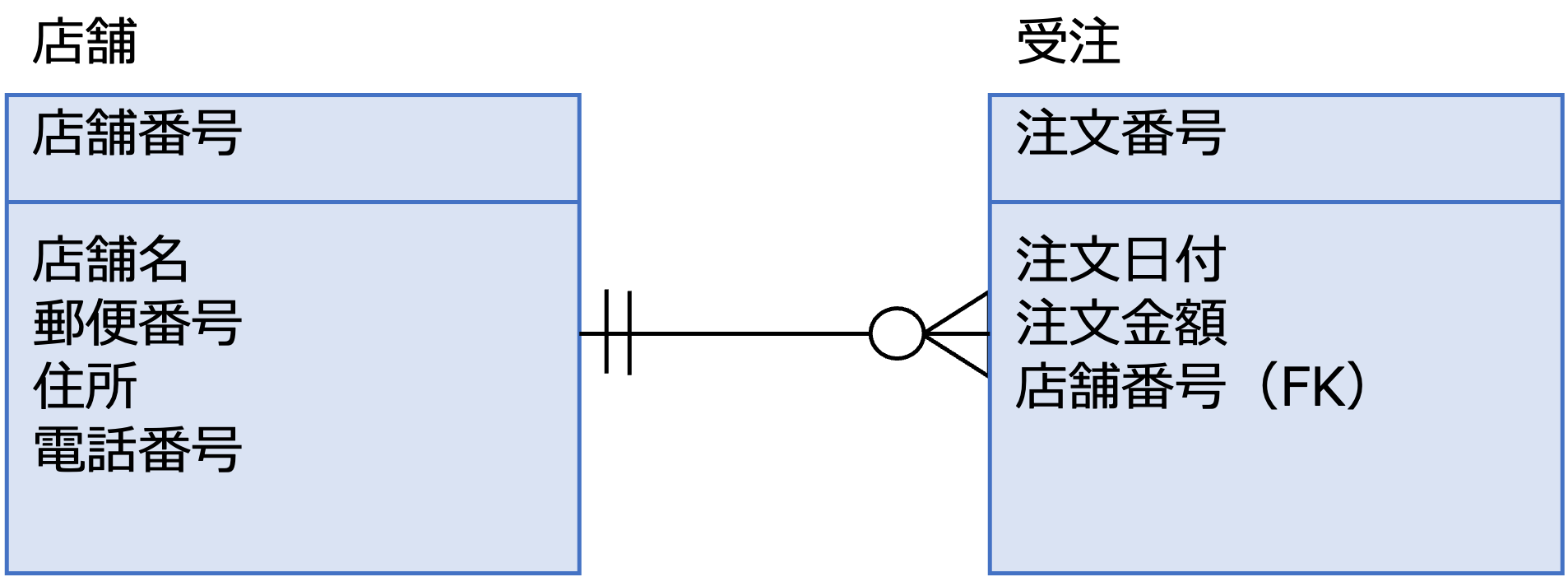
この例では、受注エンティティの店舗番号が外部キーとして、店舗エンティティの店舗番号を参照しています。
この場合、参照整合性制約により、受注エンティティの店舗番号の値と、店舗エンティティの店舗番号の値に不整合があってはいけません。
依存型リレーションシップと非依存型リレーションシップ
エンティティは、それが保持する属性によって次のように分類することができます。
- 独立エンティティ
エンティティ自身が持つ属性のみで主キーが成り立っているエンティティ。
角が直角の四角形としてエンティティを表す。 - 従属エンティティ
主キーに、別のエンティティ内にある属性が最低一つ含まれるエンティティ。
角が丸い四角形としてエンティティを表す。
また、リレーションシップも、エンティティが保持する属性によって次のように分類することができます。
- 依存型リレーションシップ
リレーションシップの一方のエンティティの主キーが、他方のエンティティの外部キーとなり、かつ、主キーを構成する一部になったもの。
従属エンティティには少なくとも一つの依存型リレーションシップがある。
依存型リレーションシップは実線で表す。 - 非依存型リレーションシップ
リレーションシップの一方のエンティティの主キーが、他方のエンティティの外部キーとなるが、それが主キーの一部にはなっていないもの。
非依存型リレーションシップは破線で表す。
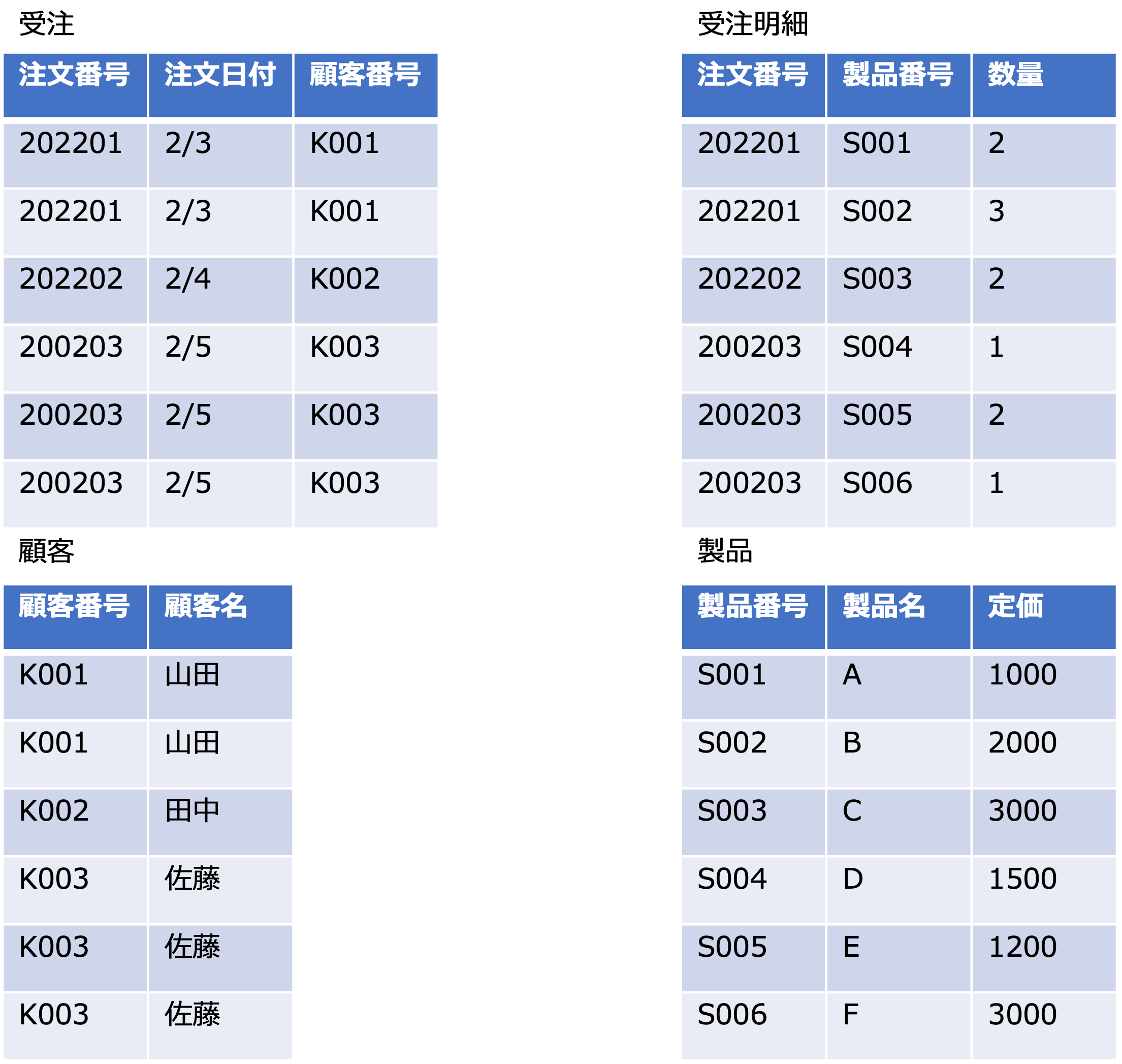
次の図は、独立エンティティと従属エンティティ、依存型リレーションシップと非依存型リレーションシップを示した例です。

内容は次のようになります。
- 受注明細エンティティは、受注エンティティの属性(この場合主キー)「注文番号」が主キーに含まれるので従属エンティティになります。
- 受注エンティティの主キー「注文番号」が、受注明細エンティティの外部キーとなり、かつ、受注明細の主キーを構成する一部になっているので、受注明細エンティティが受注エンティティに依存するリレーションになります。
- 製品エンティティの主キー「製品番号」が、受注明細エンティティの外部キーとなっていますが、受注明細エンティティの主キーを構成する一部にはなっていないので製品エンティティと受注明細エンティティのリレーションは非依存型リレーションになります。
- 店舗エンティティの主キー「店舗番号」が、受注エンティティの外部キーとなっていますが、受注エンティティの主キーを構成する一部にはなっていないので店舗エンティティと受注エンティティのリレーションは非依存型リレーションになります。
データドメイン
データドメインとは、属性の定義域のことで、属性が取りうる値一式を定義したものです。
データドメインを使うと、属性の特性を標準化することができます。
例えば、有効な日付をすべて含む日付というドメインを定義すると、それを論理データモデル内の任意の日付属性や物理データモデル内の日付カラム(フィールド)に割り当てることができます。
DMBOKでは、データドメインの形式を次のように説明しています。

なお、データドメインは、概念データモデル上、値オブジェクトのクラスとして定義されています。
概念データモデリング
概念データモデルは、ビジネスの目的を実現するために必要なデータの構造を明確にするモデルのことです。
なので、概念データモデルには、ビジネスの目的を実現するために必要なデータが全て含まれている必要があります。
結果的に、概念データモデルは、ビジネスの仕組を構成する実体の構造を表し、MDAでいうとCIM(Computation Independent Model)になります。
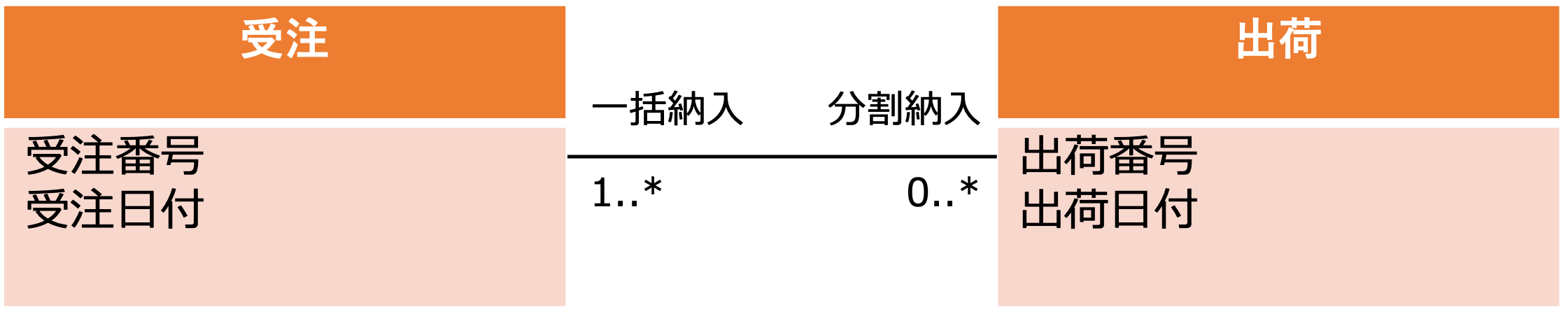
例えば、上図は、受注と出荷の関連を表した概念データモデル(クラス図)ですが、これを見ると次のことがわかります。
- このビジネスでは、一つの注文の製品を複数に分けて出荷することがある(分納)
- このビジネスでは、複数の注文をまとめて出荷することがある(一括納入)
これは、このビジネス固有の仕組を構成する実体の構造を表していることを示しています。
なお、概念データモデルは、データモデルだけでなくアプリケーションのドメインモデルとしても共有できるので、クラス図を使った概念モデルとして作ることを推奨します。
詳細は、クラス図を使った概念モデルの作り方を参照してください。
概念データモデルは、データアーキテクチャをベースに作成します。
論理データモデリング
論理データモデルは、システムの機能要件やデータの品質要件を満たすデータの構造を明確にするモデルのことです。
なので、システムの機能要件やデータの品質要件を満たすデータモデルが論理的に正しいデータモデルということになります。
概念データモデルは、MDAでいうとPIM(Platform Independent Model)になります。
正規化
リレーショナルスキームの論理データモデルで、データ品質要件、特に一意性や一貫性を確保するための方法に正規化(normalize:一定の規則に基づいて変形し利用しやすくすること)があります。
正規化の目的は、冗長性を排除するために一つの属性データを一つの場所に保持し、冗長性に起因するデータの不整合をなくすことです。
これを
One Fact in One Place(一つの事実は一つの場所に)
といいます。
正規化の方法とは、主キーと外部キーに従って属性を整理することです。
正規化が行われたデータモデルを正規形と呼びます。
ここでは、次の3つのレベルの正規形について説明します。
なお、後に示した正規形は、それより前に示した正規形の十分条件になっています。
例えば、第3正規形は常に第2正規形です。
第1正規形
属性およびエンティティが原子的(アトミック)な形になっていること。
属性およびエンティティが原子的(アトミック)な形になっていないと「One Fact in One Place」にならなくなるとともに、最終的にテーブル(表)にデータが格納できなくなり関係演算もできません。
※関係演算
リレーショナルスキームのテーブル(表)から目的のデータを取り出すための操作のこと。
属性が原子的であるとは、一つの属性にカンマ区切りなどで複数の値が含まれていないことです。
一つの属性に複数の値が含まれる場合、複数の事実(値)が一つの場所(属性)に含まれることになるので「One Fact in One Place」ではなくなります。

この例の場合、属性に設定されるべき値以外の値が混入する可能性があります。
属性が原子的ではない場合は、複数の値を別々の属性に分割することで第1正規形にします。
他の属性から導くことができる属性(導出属性)も排除するようにします。
例えば、注文金額は単価×数量で導出できるので属性として定義する必要がありません。
次に、エンティティが原子的であるとは、一つのエンティティに同種の属性が複数含まれていないことです。
一つのエンティティに同種の属性が複数あるということは、同じ内容の事実が一つの場所(エンティティ)で複数発生することになり、冗長性に起因するデータの不整合が発生する可能性があります。

この例の場合、同じ事実にも関わらず異なるデータが混入する可能性があります。
特に、一つのエンティティに同種の属性の組みが繰り返しある場合、同種の属性の組みを、繰り返しグループといいます。
エンティティにに繰り返しグループがある場合は、エンティティ内の繰り返しグループを分割することで第1正規形にします。
例

この例の場合、{製品番号, 製品名、定価、数量}の組みが繰り返しグループになっているので、エンティティが原子的になっていません。
なので、繰り返しグループを分割して第1正規形にすると次のようになります。

第2正規形
エンティティのすべての候補キーにおいて部分関数従属していない形になっていること。
関数従属
A及びBを属性または属性の集合としたとき、「AがBに関数従属する」とは、Bの値を決めると、常にAの値が一つに定まるような性質(関数従属性)をAが有することをいい、これを「B→A」(原因B→結果A)と書きます。
例
{会員番号, 会員氏名} という関係の場合、会員番号が決まれば会員氏名も一つに定まるから、会員氏名は会員番号に関数従属しています。
部分関数従属
部分関数従属とは、ある非キー属性(候補キーに含まれない属性)が、「候補キーのー部」に関数従属していることを指します。
部分関数従属している非キー属性の値は、同じ値が複数の場所(異なるレコード)に重複して保存されることになり、「One Fact in One Place」にならず、結果的にデータの不整合を起こす可能性があります。
部分関数従属がある場合、部分関数従属している属性部分を切り出して別のエンティティにすることで第2正規形にすることができます。
例
例えば、{会社コード, 代表者氏名, 従業員番号, 従業員氏名} という従業員エンティティで、{会社コード, 従業員番号} の集合が候補キーだとすると、会社コード→代表者氏名という部分従属があるから、この関係は第2正規形ではありません。
この関係では、代表者氏名が複数の場所(異なるレコード)に重複して発生し、結果的に、会社コードと代表者氏名の対応が場所(レコード)によって異なるという不整合が発生する危険があります。
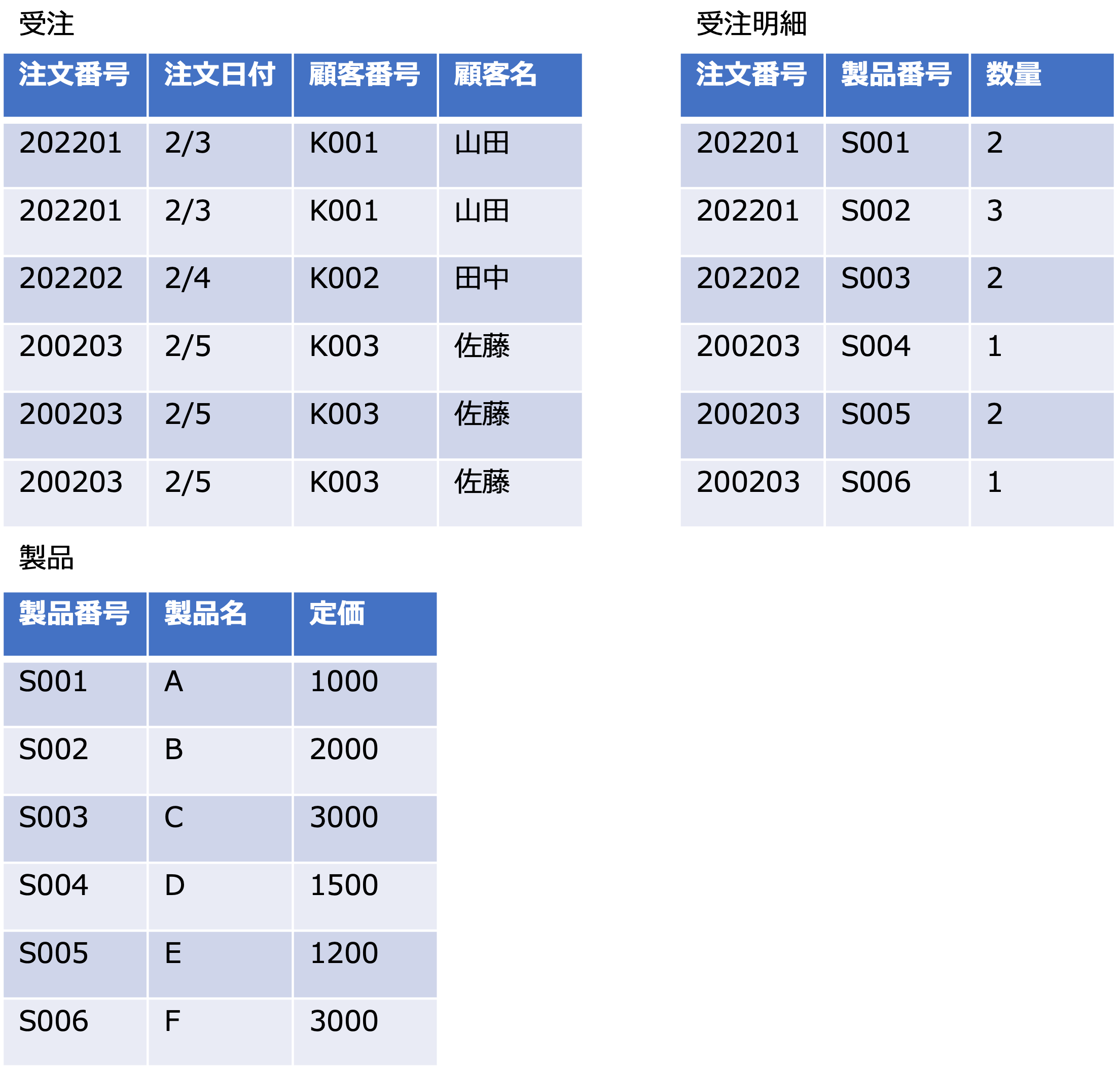
例
この例の場合、主キーを構成する注文番号に{注文日付, 顧客番号, 顧客名}が部分従属しています。
また、主キーを構成する製品番号に{製品名, 定価}が部分従属しています。
これは、受注というエンティティ(実体)に受注と製品という2つの事実が混在していることになります。
なので、これらを分割して第2正規形にすると次のようになります。
第3正規形
エンティティに推移関数従属している属性がない形になっていること。
候補キー以外の属性に関数従属している属性がないようにします。
推移関数従属
候補キーA及び非キー属性B, Cを含む関係があり、A→BかつB→Cのとき、Cは候補キーAに推移関数従属する(推移的に関数従属する)といいます。
推移関数従属している非キー属性の値は、同じ値が複数の場所(異なるレコード)に重複して保存されることになり、「One Fact in One Place」にならず、結果的にデータの不整合を起こす可能性があります。データの不整合を起こす可能性があります。
推移関数従属がある場合、推移関数従属している属性部分を切り出して別のエンティティにすることで第3正規形にすることができます。
例
この例の場合、顧客番号は注文番号に関数従属する、かつ、顧客名は顧客番号に関数従属することから、顧客名が注文番号に推移関数従属することになります。
これは、受注というエンティティ(実体)に、受注と顧客という2つの事実が混在していることになります。
なので、これらを分割して第3正規形にすると次のようになります。
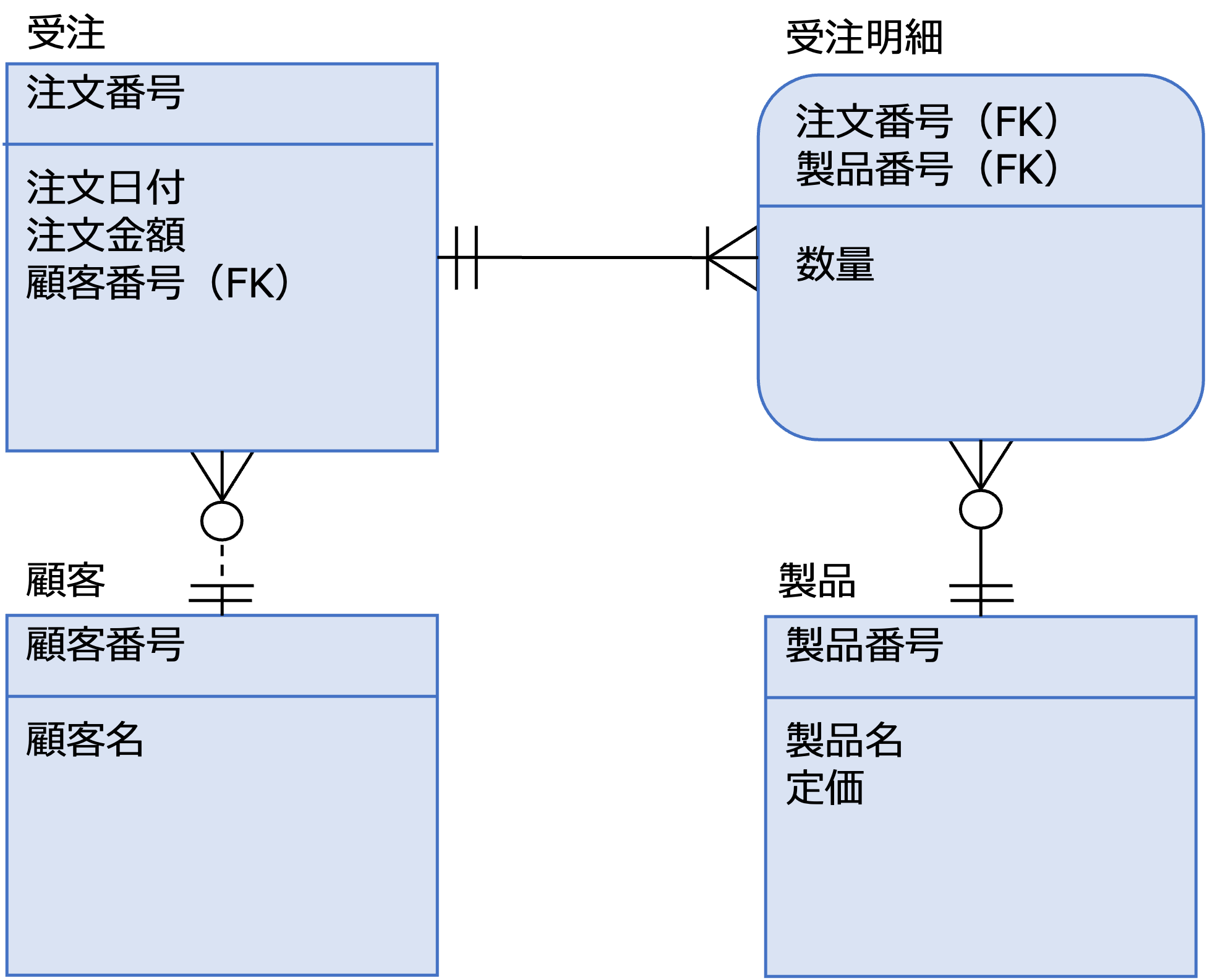
これを論理データモデルで表すと次のようになります。
論理データモデリングの活動
ここでは、DMBOKも参考にして、次のような活動を定義します。
データ要件の定義
ビジネス上の課題を解決するために定義されたシステム機能要件をベースに、次の二つのデータ要件を定義します。
- データ機能要件
システムの機能を満たすために必要なエンティティが全て揃っているか確認し、不足があれば追加します。
システムの機能を満たすためのデータ項目(システムのインプット、アウトプットに必要なデータ項目)を洗い出して定義します。
論理データモデルの属性はデータ項目として定義します。 - データ品質要件
必要なエンティティが満たすべき品質も含めて、エンティティを次のように定義します。
エンティティ定義の例
必要なデータ項目が満たすべき品質も含めて、データ項目を次のように定義します。
データ項目定義の例

データマネジメントプロセスの「データ設計の検証」活動で、データ管理実行者は、定義されたエンティティとデータ項目をビジネスメタデータとして登録します。
ここで、データ品質を測る指標の一つであるデータの一貫性に関する制約(一貫性制約)についてまとめておきます。
データの一貫性制約は、次の3つに分けることができます。
- データ項目の一貫性制約
- データ項目間の一貫制約
- エンティティ間の一貫制約
データ項目の一貫性制約
データ項目の値にに関する一貫性制約は、データドメインによって定義することができます。
これを、ここではドメイン制約と呼びます。
例えば、概念データモデル(クラス図)では、次の図のように、値オブジェクトでデータドメインを定義し、エンティティから依存関係で参照させるという関係でドメイン制約を表すことができます。

論理データモデルの場合、データ項目定義のドメイン制約で定義するようにします。
データ項目間の一貫制約
データ項目間の制約を、ここでは関連制約と呼びます。
次のような例があります。
受注日当日の出荷はできないので、受注エンティティの出荷予定日は注文日付より後になるようにする。
概念データモデルでは、受注エンティティの注文日付に以下のような制約を定義することができます。
{出荷予定日>注文日付}
論理データモデルの場合、データ項目定義の関連制約で定義するようにします。
エンティティ間の一貫制約
代表的なエンティティ間の一貫制約には次の2つがあります。
存在制約
あるインスタンスが存在するには、他のインスタンスの存在が必要であるという制約です。
概念データモデルの場合、クラス図の関連や多重度で存在制約を表現することができます。
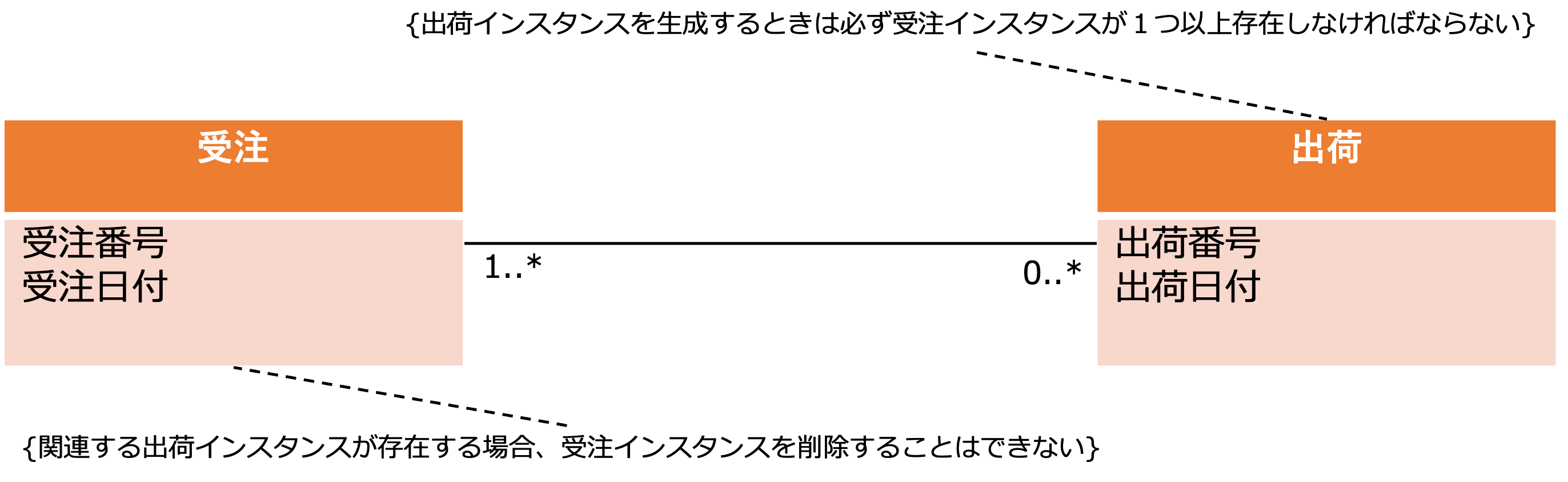
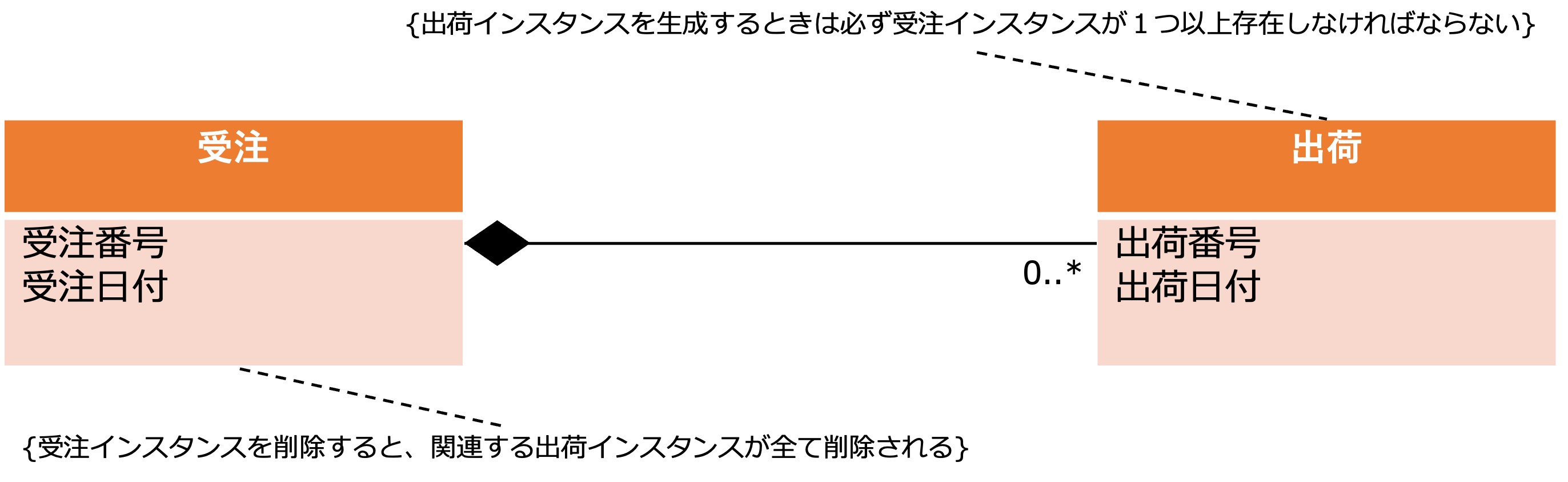
例えば、上図のように、出荷エンティティに対して受注エンティティの多重度が1以上になっている場合、以下の存在制約が発生します。
- 出荷インスタンスを生成するときは必ず受注インスタンスが1つ以上存在しなければならない
- 関連する出荷インスタンスが存在する場合、受注インスタンスを削除することはできない
これを明示的に図上の表記したい場合は、上のクラス図のように関連に対する制約を設けて表すことができます。
また、下図のように、受注側の関連がコンポジションになっていた場合、受注インスタンスと出荷インスタンスのライフサイクルが同じになるので、受注インスタンスを削除すると関連する出荷インスタンスもすべて削除されることになります。
論理データモデルの場合、多重度のオプショナリティやリレーションシップで存在制約を表現することができます。
例えば、上図のように、受注明細エンティティが受注エンティティに対して強く依存している場合、オプショナリティを考慮すると、以下の存在制約が発生します。
- 生成時の制約
- 受注インスタンスを生成するとき、必ず受注明細インスタンスが1つ以上存在する必要がある(受注明細側が必須になっているため)
- 受注明細インスタンスを生成するときには、必ずそれに対応する受注インスタンスが存在する必要がある(受注側が必須になっているため)
- 削除時の制約
- 受注インスタンスを削除すると、それに対応する受注明細インスタンスはすべて削除される(受注側は必須になっているが、受注と受注明細の関係が依存型リレーションシップになっているため)
- 受注明細を削除するときには、そのインスタンスが対応する受注インスタンスの最後の明細であれば、受注インスタンスも削除される(受注明細側が必須になっているため)
一方、上図のように、受注明細エンティティと製品エンティティが非依存型リレーションシップになっている場合、オプショナリティを考慮すると、以下の存在制約が発生します。
- 生成時の制約
- 受注明細インスタンスを生成するときには、必ずそれに対応する製品インスタンスが存在する必要がある(製品側が必須になっているため)
- 製品インスタンスを生成するとき、必ずしも受注明細インスタンスが1つ以上存在する必要はない(受注明細側が任意になっているため制約は発生しない)
- 削除時の制約
- 製品インスタンスを削除するとき、それに対応する受注明細インスタンスが存在している場合、製品インスタンスは削除できない(製品側が必須かつ、製品と受注明細の関係が非依存型リレーションシップになっているため)
- 受注明細インスタンスを削除するとき、そのインスタンスが対応する製品インスタンスの最後の明細であっても、製品インスタンスを削除する必要はない(受注明細側が必任意になっているため制約は発生しない)
また、店舗エンティティと受注エンティティが非依存型リレーションシップになっている場合、次のような制約が発生します。
- 生成時の制約
- 受注インスタンスを生成するときには、必ずそれに対応する店舗インスタンスが存在する必要がある(店舗側が必須になっているため)
- 店舗インスタンスを生成するとき、必ずしも受注インスタンスが1つ以上存在する必要はない(受注が任意になっているため制約は発生しない)
- 削除時の制約
- 店舗インスタンスを削除するとき、それに対応する受注インスタンスが存在している場合、店舗インスタンスは削除できない(店舗側が必須かつ、店舗と受注の関係が非依存型リレーションシップになっているため)
- 受注インスタンスを削除するとき、店舗インスタンスを削除する必要はない(受注が必任意になっているため制約は発生しない)
参照整合性制約
外部キーの値が主キーの値として存在することを保証する制約です。
上記、存在制約が発生します。
属性の追加
データ要件として定義されたデータ項目を、論理データモデルのエンティティの属性として追加します。
論理データモデルの属性は正規化(第1正規形)されて、アトミック(原子的)でなければなりません。
アトミックな属性とは、その中にたった一つのデータ(事実)しか入らないもので、そのデータは、それ以上分割できません。
例
電話番号は、電話の種類、国コード、市外局番、局番、電話番号、内線番号などに分割されます。
識別子(キー)の割り当て
論理データモデルのエンティティの属性の中から候補キーを探し、主キーと代替キーを特定します。
関連エンティティの追加
概念データモデルに多対多のリレーションシップがある場合、正規化の観点から、関連エンティティを定義します。
関連エンティティとは、多対多のリレーションシップの間で、互いのエンティティの識別子を持ったリレーションシップだけを記述するエンティティのことです。
例えば、次のように概念データモデルで受注エンティティと製品エンティティの多対多の関連があると、実際のデータを格納するとき、一つの属性にカンマ区切りなどで複数の値が含まれ属性が原子的にならないので、第一正規形に正規化する必要があります。
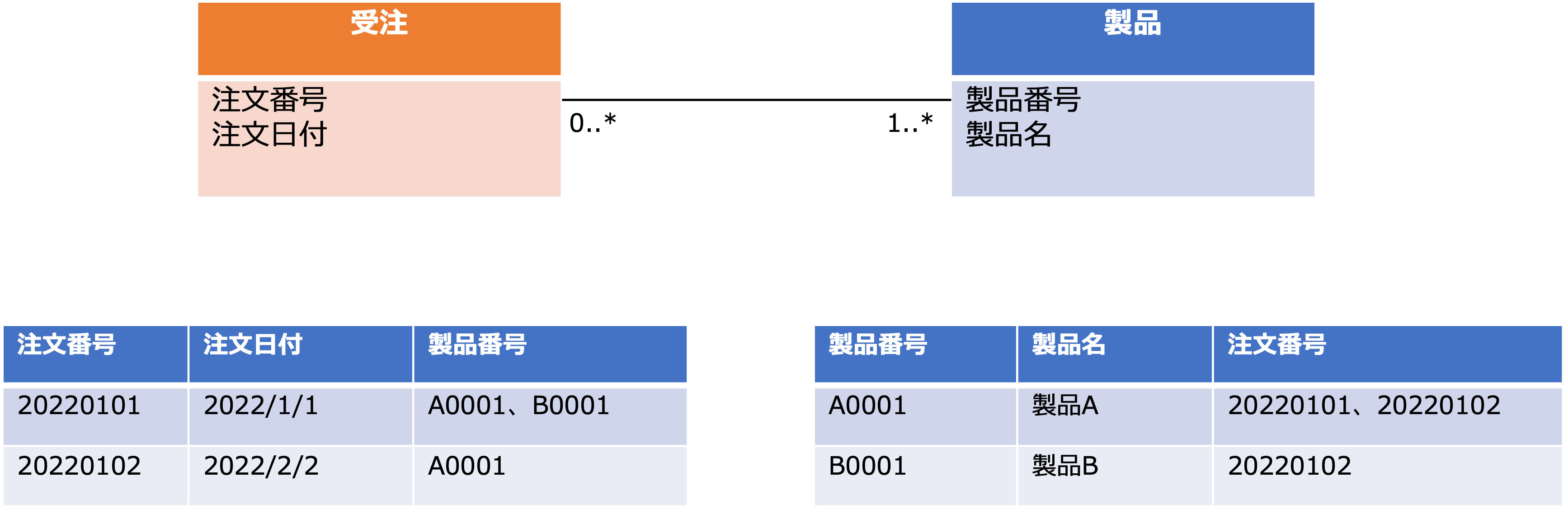
上の例を第一正規形に正規化すると次のような論理データモデルになります。
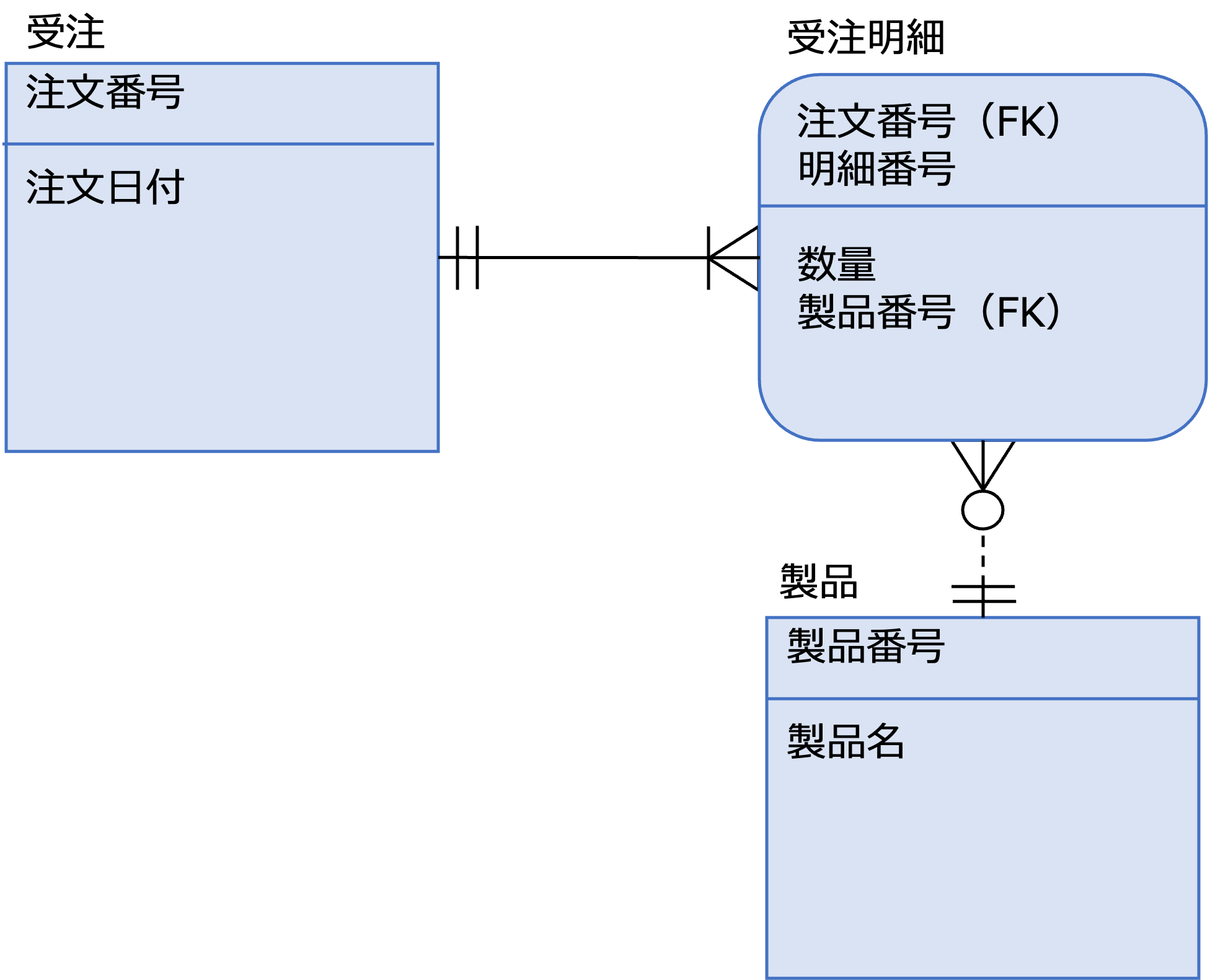
受注エンティティと製品エンティティの間に関連エンティティとして受注明細エンティティが定義されいることがわかります。
関連エンティティとは本来、リレーションシップだけを記述するエンティティのことですが、受注明細エンティティの場合、注文数量など業務的な意味を持つ属性も定義されます。
一般化
論理データモデルのエンティティで、一般化できるものがあれば、スーパータイプとサブタイプに分けることで一般化します。

上の図は、顧客は、個人顧客と法人顧客に分かれるという排他関係を表した例です。
この例の顧客区分のように、スーパータイプに、サブタイプを分ける区分属性を設定し、その属性値でサブタイプを切り分けます。
データドメインの割り当て
概念データモデルの値オブジェクトクラスをデータドメインとして割り当てます。
具体的には、次の例のように「メイン番号」を該当するデータ項目に定義します。
データ項目定義の例
物理データモデリング
物理データモデルは、システムの非機能要件(特に効率性)を満たし、IT基盤(データベース製品など)に適応したデータの構造を明確にするモデルのことです。
概念データモデルは、MDAでいうとPSM(Platform Specific Model)になります。
DMBOKでは、物理データモデリングとして次のような活動を定義しています。
一般化の解消
論理データモデルで行なった一般化を解消して、物理データモデルに変換します。
上の図は、顧客は、個人顧客と法人顧客に分かれるという排他関係を表した例です。
顧客エンティティに顧客共通属性があり、個人顧客と法人顧客に、それぞれ個人顧客固有属性と法人顧客固有属性が定義されていることがわかります。
次の3つの方法があります。
- 全てのサブタイプを個別のテーブルに実装する
次のような場合に適用します。- 排他的サブタイプであること
- 同一の子テーブルを持たないこと
- サブタイプ間の独立性が高く、複数のサブタイプを同一の処理で扱わないこと
一般化を解消すると次のような形になります。

- 全てのサブタイプを同一テーブルに実装する
次のような場合に適用します。- サブタイプ固有の属性が少ないこと(=サブタイプ間の違いが小さい)
- サブタイプ間の独立性が低く、同一の処理で複数のサブタイプを扱う場合が多いこと
- テーブルのサイズ(行数×行長)が大きくなりすぎないこと
一般化を解消すると次のような形になります。

- スーパータイプとサブタイプを分けてテーブルに実装する
次のような場合に適用します。- サブタイプ固有の属性が少なくないこと(サブタイプ間の違いがそれなりにある)
- サブタイプ間の独立性がそこそこあるが、共通の処理も存在すること
一般化を解消すると次のような形になります。
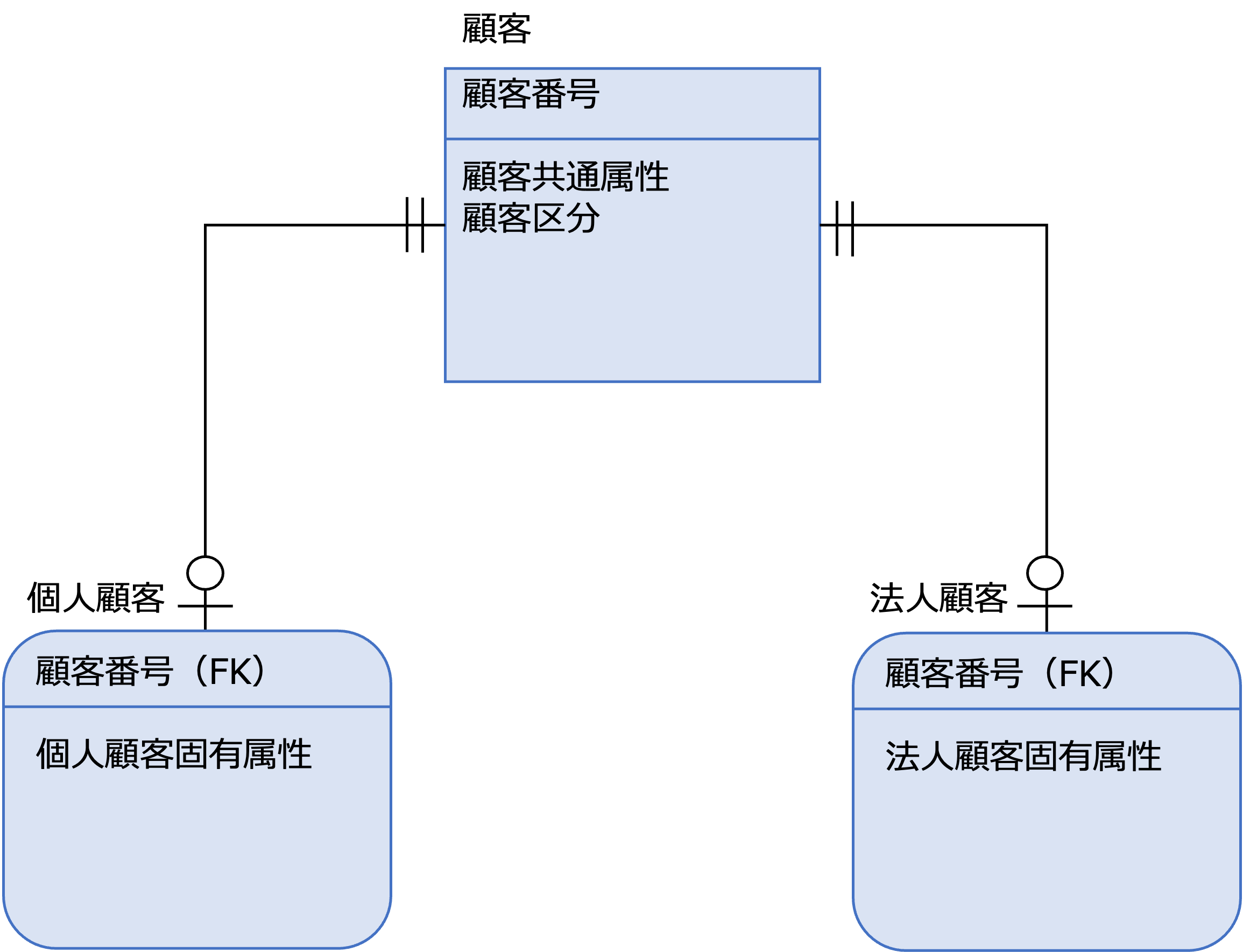
それぞれのサブタイプに、顧客共通属性が定義されていることがわかります。
顧客エンティティにすべての属性が統合されていることがわかります。
顧客エンティティが独立エンティティ、個人顧客エンティティ、法人顧客エンティティが従属エンティティという依存型リレーションになります。
顧客側の多重度は1ですが、従属エンティティである個人顧客エンティティ、法人顧客エンティティの場合、それぞれの場合があるので、多重度が0または1になっていることに注意してください。
参照データオブジェクトの追加
概念データモデルで値オブジェクトとして定義したものは、参照データとして、次のように定義することができます。
- 個別のコードテーブルを定義する
値オブジェクトを個別のコードテーブルとして定義します。
例えば、次の論理データモデルの受注ステータスエンティティを一つのコードテーブルとして定義します。

- 共有コードテーブルを定義する
個別のコードテーブルが管理できないほど多数になる場合、一つの共有コードテーブルとして定義することができます。

- オブジェクトコードに埋め込んで定義する
値オブジェクトをテーブルの中に埋め込んで定義します。
次の例は、受注ステータスを値オブジェクトとして受注エンティティに埋め込んで定義しています。
サロゲートキーの割り当て
DBMOKでは、
自然キーのサイズが大きかったり、
複合キーであったり、
その属性に、時間と共に変化する可能性のある値が割り当てれている場合、
サロゲートキーを定義すると説明しています。
非正規化
非正規化とは、非機能要件である効率性(パフォーマンス)や安全性(セキュリティ)を上げる目的で、正規化済みの論理データモデルのエンティティを、冗長性や重複したデータ構造を持った物理テーブルに変換することです。
DMBOKでは、次のような例を挙げています。
- コストがかかる実効時のテーブル結合を避けるため、複数のテーブル内にあるデータをあらかじめ結合しておく。
- 大規模なテーブルにおいて、コストがかかる実行時の計算やテーブルスキャンを削除するために、事前にフィルタリングされた小さなコピーを作る。
- 実行時にシステムリソースが圧迫されないように、高コストのデータ計算を事前に済ませておき、結果を保持する。
※第一正規形で排除された導出属性を戻す場合も含む。 - セキュリティを強化するため、アクセス要求に応じてデータを複数のビューやテーブルのコピーに分離する。
ただし、非正規化は、重複によるデータ品質の低下を招くため、ビュー定義やパーティション分割では効率性が十分確保できない場合に行います。
非正規化が選択されるときはデータのコピーが正しく格納されるよう、データ品質をチェックするロジックを実装するようにします。
記録システムのリレーショナルデータベースとは別に、クエリや分析用にデータレークやデータウェアハウスを構築する場合もあります。
テーブルの定義
リレーショナルスキームの場合、選択したデータベース製品の仕様に合わせて、エンティティをテーブル、属性をデータ項目(列)として定義します。
テーブル定義の例
出所:厚生労働省
インデックスの定義
効率性(パフォーマンス)の向上を目的としてインデックスを定義します。
インデックスとは、目的のレコードを効率よく取得するための「索引」のことです。
テーブル内の特定の列を識別できる値(キー値)と、キー値によって特定された列のデータが格納されている位置を示すポインタで構成されています。
インデックスを参照することで目的のデータが格納されている位置に直接アクセスすることができ、検索を高速化することができます。
ただし、テーブルとは別にデータを独自に保持しますので、テーブルにデータを追加するとインデックスの方にもデータが追加されます。
また並び替えなどを行っている場合は、データを追加するごとに並び替えも再度行われます。
結果としてデータを追加するときの処理が遅くなります。
格納されているデータが少ないテーブルでインデックスを作成したり、格納されるデータの種類が少ないカラムでインデックスを作成しても効果はそれほど期待できません。
また、データの検索がそもそもあまり行われないカラムでインデックスを作成しても意味がありません。
なので、データ量が多い大きなテーブルに対して、頻繁に参照される列(主キー、代替キー、外部キー)を使用して、最も頻繁に行われるクエリを効率化する場合にインデックスを定義するようにします。
パーティション化
パーティション化とは、検索パフォーマンスを向上させるためにテーブルを分割することです。
DMBOKでは次の方法を紹介しています。
- 垂直分割
クエリ対象を減らすために、一部の列を含むテーブルのサブセットを作成します。
例
クエリに含まれるフィールドの更新頻度が多いか少ないか(ロードやインデックスパフォーマンスに影響する)
使用頻度が多いか少ないか(テーブルスキャンのパフォーマンスに影響する)
などに基づいて顧客テーブルを二つに分割する。 - 水平分割
クエリ対象を減らすために、列の値に基づいて行を分割しテーブルのサブセットを作成します。
例
特定の地域の顧客のみを含む地域別顧客テーブルを作成する。
ビューの定義
ビューとは仮想テーブルのことです。
ビューは実際の属性値を含んだり参照したりすることにより一つ以上のテーブルからデータを表示する手段となります。
標準的なビューにおいては、ビュー内の属性が要求された時に初めてデータ検索のSQLが実行されます。
インスタンス化されたマテリアライズドビューでは、所定の時間にSQLが実行されます。
ビューは、非正規化による冗長化や参照整合性を犠牲にすることなく、問合せを簡素化したり、データアクセスを制御したり、列の名前を変更したりするために使用されます。
ビューを定義することで、特定のデータエレメントへのアクセスを制御したり、共通の結合条件やフィルタを埋めこんだ共通オブジェクトやクエリを標準化することができます。
【関連動画】
=============
Udemy研修のご紹介
クラス図とER図で根本的に学ぶデータモデリング
本研修では、
- UMLのクラス図を描くことができるようになること
- IE表記法とIDEF1X表記法を使ってER図を描くことができるようになること
- ビジネスの仕組を構成する実体の構造を表す概念データモデルが描けるようになること
- システムの機能要件やデータの品質要件を満たす論理データモデルが描けるようになること
- 論理データモデルを物理データモデルに展開するときのポイントが理解できていること
を学習目標に、データモデリングを根本から学ぶことができます。
- 企業のDX担当者の方
- ITエンジニアに必要なスキルの一環としてデータモデリングスキルを身につけたい方
- データサイエンティストに必要なスキルの一環としてデータモデリングスキルを身につけたい方
- データマネジメントの基礎スキルとしてデータモデリングスキルを身につけたい方
ぜひ、ご受講ください。


[…] ここでは、データアーキテクチャとして物理データモデルを設計します。 全社レベルのデータアーキテクチャがある場合、それを踏襲します。 なお、物理データモデルに関しては、記事データモデリング・物理データモデリングを参照してください。 […]
[…] 概念データモデル 最後に、マスターデータと、トランザクションデータを考慮して、ビジネスプロセス別の概念データモデルを設計します。 概念データモデルは、システム開発の際、アプリケーション単位のドメインモデル、論理データモデルのインプットになります。 […]
[…] から構成されます。 図:エンタープライズデータモデル 出典:データマネジメント知識体系 第二版 次の図は、スコープ(縦軸)とレベル(横軸)でエンタープライズデータモデルを分けたマトリクスです。 一方、データフローですが、EDM同様、スコープ(縦軸)とレベル(横軸)で分解すると次の図のようになります。 なお、なお、ビジネスプロセスの業務概念データモデルや業務論理データモデルをつくるときは、企業全体の活動領域(DMBOKのサブジェクトエリアと同義)を明確にします。 そして、そして、各活動領域に対応するビジネスプロセスを定義したうえで、ビジネスプロセス単位に業務概念データモデルや業務論理データモデルを作成します。 それから、エンタープライズアーキテクチャ(EA)におけるデータアーキテクチャ(DA)の位置づけは次のようになります。 概念データモデルは、データモデルのスキームや技術、製品に依存しない本質的なデータモデルなので、データモデルのスキームに依存しないUMLのクラス図で記述します。 一方、論理データモデルは、データモデルのスキームによって表現が異なります。 リレーショナルスキームの場合、論理データモデルはER図で記述します。 なので、リレーショナルスキームの場合、論理データモデルは、概念データモデルをER図に変換したものになります。 また、概念データフローは、技術や製品に依存したい本質的なアプリケーションタイプ間のデータの流れを表した図になります。 また、概念データフローには、データ統合の方針に合わせてバッチによる統合、イベント駆動による統合、リアルタイムの統合の違いが示されています。 論理データフローは、アプリケーションやデータ管理基盤の製品が反映されたものになります。 エンタープライズアーキテクチャ(EA)でいうと、概念レベルのEDMとデータフローは、EAの設計レベル、論理レベルのEDMとデータフローは、EAの戦略レベル、物理レベルのEDMとデータフローは、EAの実例レベルのデータアーキテクチャとして設計します。 図:エンタープライズアーキテクチャの構成 また、データマネジメント導入プロセスでいうと、概念レベルのEDMとデータフローは、データマネジメントモデルの設計、論理レベルのEDMとデータフローは、データマネジメント戦略の策定、物理レベルのEDMとデータフローは、データマネジメントシステムの構築のときに設計します。 […]
[…] ※エンティティ(実体)と{… […]
[…] 非正規化データ(生データ) 企業の記録システム(SoR)のデータは、正規化されています。 データが正規化されると効率的に更新することができますが、データがばらばらになっているため検索にコストがかかります。 データを分析するときは様々な視点でデータを検索します。 データを非正規化することで、効率的に検索できるようにしたデータを、非正規化データ(生データ)といいます。 非正規化データ(生データ)は、更新されることがなく、データウェアハウス(データの倉庫)に蓄積されていきます。 また、非正規化データ(生データ)は、ブロックチェーンで管理される場合もあります。 […]
[…] ; MDAの考え方を踏まえて3つのデータモデルの違いについて説明しますz […]
[…] ータの有効性に関する制約です。 データの有効性とは、データがどの程度、データドメイン(データの範囲)に準拠しているかを表すものです。 例えば、顧客を分類する分類基準や分類 […]