
5Gが普及すると、ますます、IoTなどにより発生するビッグデータを、AIを活用してビジネスに活かすことが当たり前になってきます。
データは21世紀の石油と言われています。
「稼ぐ力を持つ資産としてのデータをどう利活用するか」ということが、会社を発展させるための重要な課題になってきました。
今回は、
- データサイエンスの全体像について知りたいという方
- データサイエンス、人工知能、機械学習や深層学習、統計学の違いについて知りたいという方
- DXを推進する一環としてデータサイエンスを学びたいという方
を対象に、データサイエンスについて以下の観点で解説します。
データサイエンスとは
まず、データサイエンスですが、これは、
データを用いて新たな科学および社会に有益な知見を引き出そうとする科学的アプローチ
のことです。
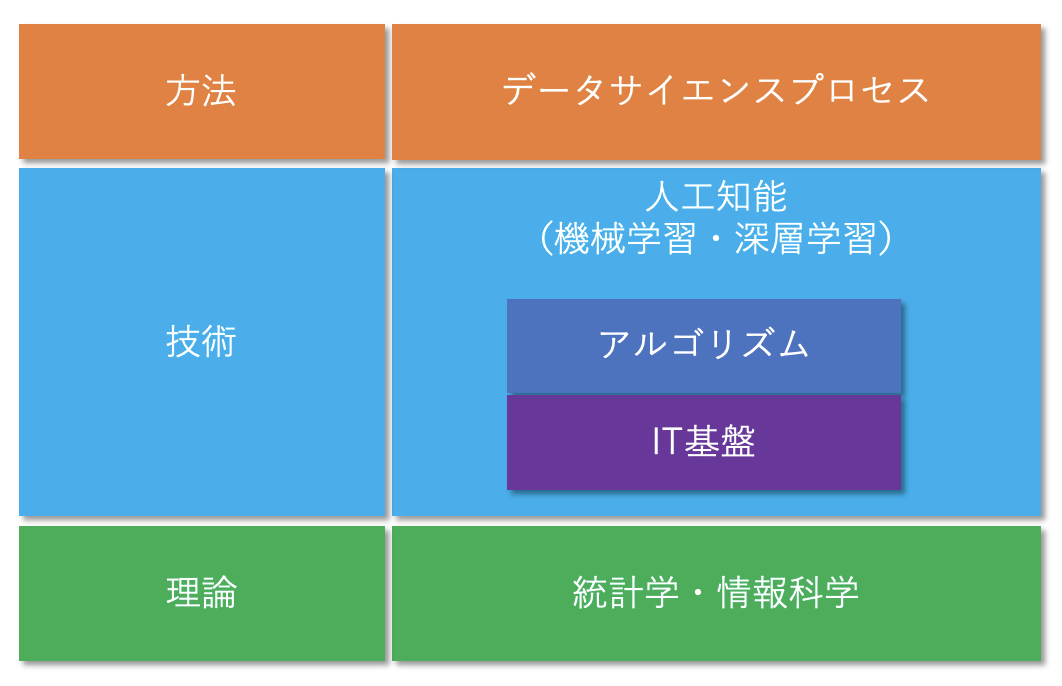
これだけでは、抽象的過ぎるので、ここでは、データサイエンスを
- 方法
- 技術
- 理論
に分けて整理したいと思います。
データサイエンスの方法
まず、データサイエンスの方法ですが、これは、データサイエンスをどう進めるのか、そのプロセスです。
データサイエンスの技術
次に、データサイエンスに必要な技術ですが、これは、機械学習や深層学習による人工知能です。
人工知能とは、手順(アルゴリズム)とデータを準備することで、人間の行う知的行為(認識、推論、表現、創造など)を機械に行わせること、および、その機械のことです。
人工知能を作る方法として機械学習や、その一種である深層学習があります。
機械学習とは、機械に学習させることで、人間の行う知的行為を行う人工知能のモデル(機械学習モデル)を構築させる手法のことです。
ここでは、データサイエンスの技術を、さらに、
アルゴリズムと
それを機能させるIT基盤
に分けて整理します。
※ここでは、それまで未知だったデータの特徴を発見する「データマイニング」も機械学習のための手法として考えます。
データサイエンスの理論
最後に、データサイエンスのベースとなる理論ですが、これは統計学と情報科学です。
統計とは、観察や実験の結果を数量データで表し、そこから法則性を導き出すこと、統計学とは、統計の方法に関する理論を研究する学問のことです。
統計学は、帰納法による科学的推論ための論理体系になります。
次に、情報科学ですが、これは、コンピュータ科学ともいい、情報と計算の理論的基礎、及びそのコンピュータ上への実装と応用に関する研究分野のことです。
DMBOKにおけるデータサイエンスの位置付
ここで、データマネジメント知識体系(DMBOK)におけるデータサイエンスの位置付けについて説明します。
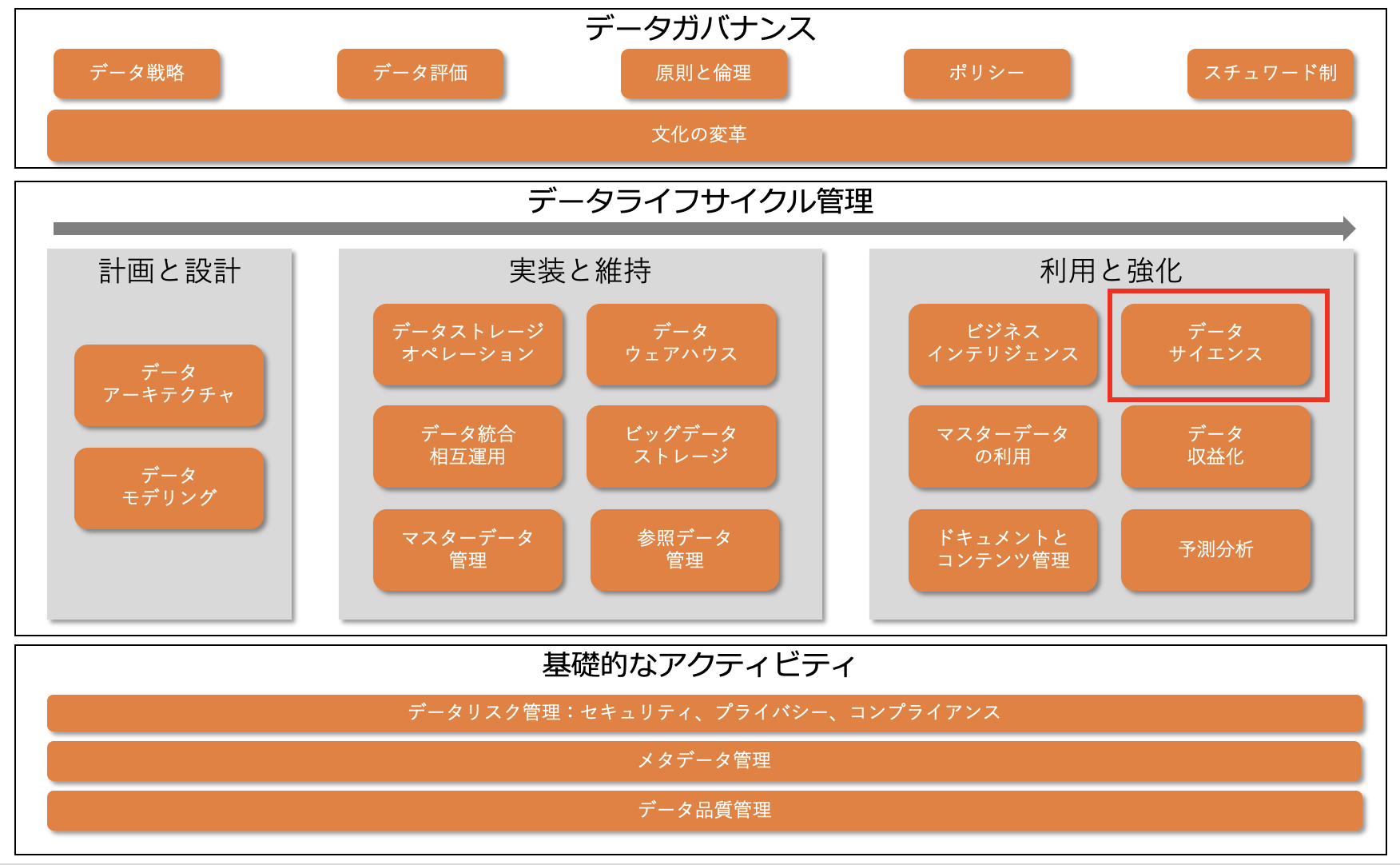
これは、DMBOKで説明しているデータマネジメントの機能フレームワークです。
これを見ると、データサイエンスは、データライフサイクル管理の中の「利用と強化」に位置付けられていることがわかります。
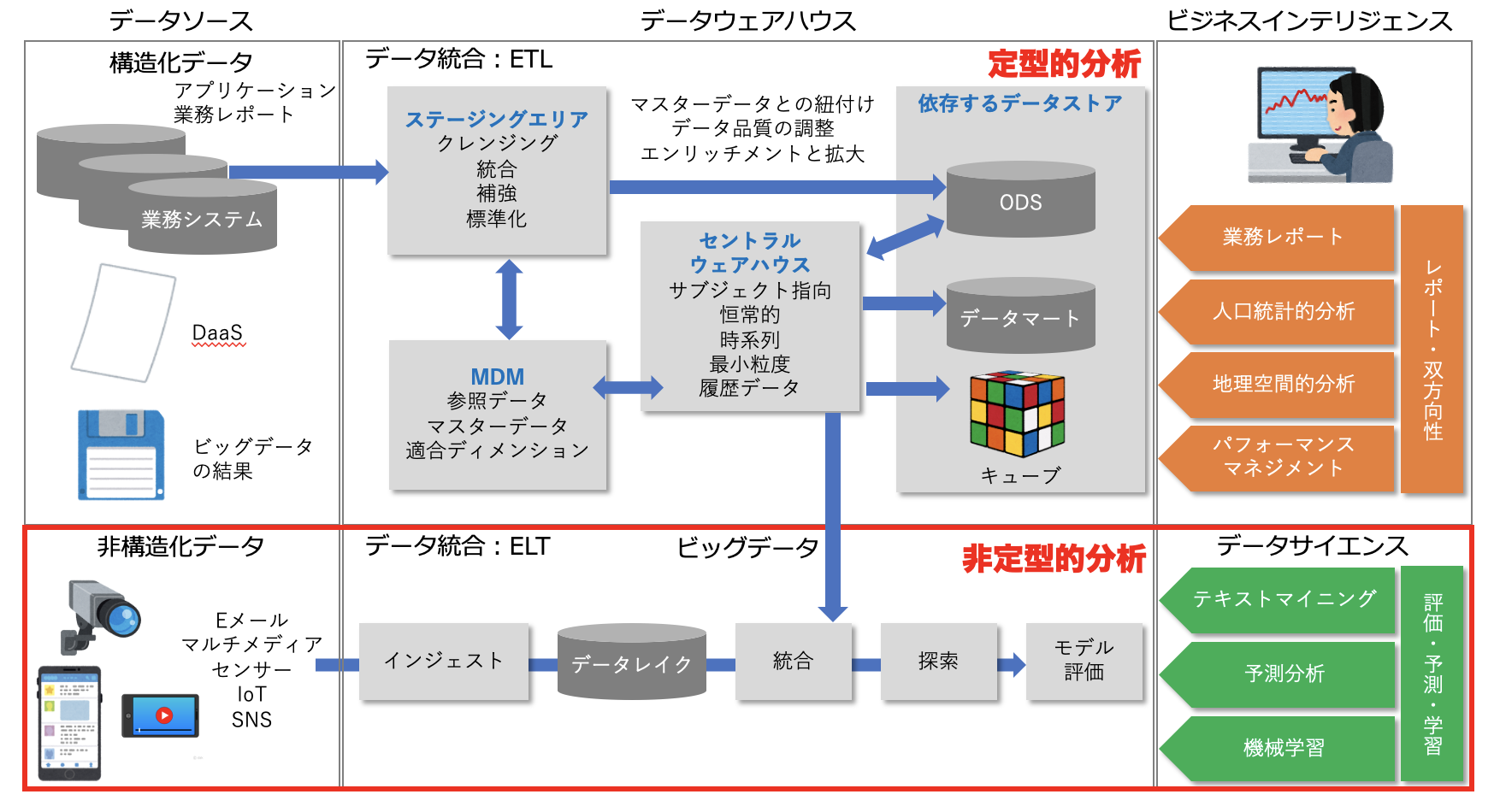
図:データウェアハウスとビッグデータのアーキテクチャ 出典:データマネジメント知識体系 第二版
また、これは、DMBOKで説明しているデータウェアハウス・ビジネスインテリジェンスとビッグデータのアーキテクチャを示した図です。
これを見ると、データサイエンスは、下段のビッグデータを扱う非定型的なデータ分析として位置付けられていることがわかります。
DXにおけるデータサイエンスの位置付
続いて、DXにおけるデータサイエンスの位置付けについて見てみましょう。
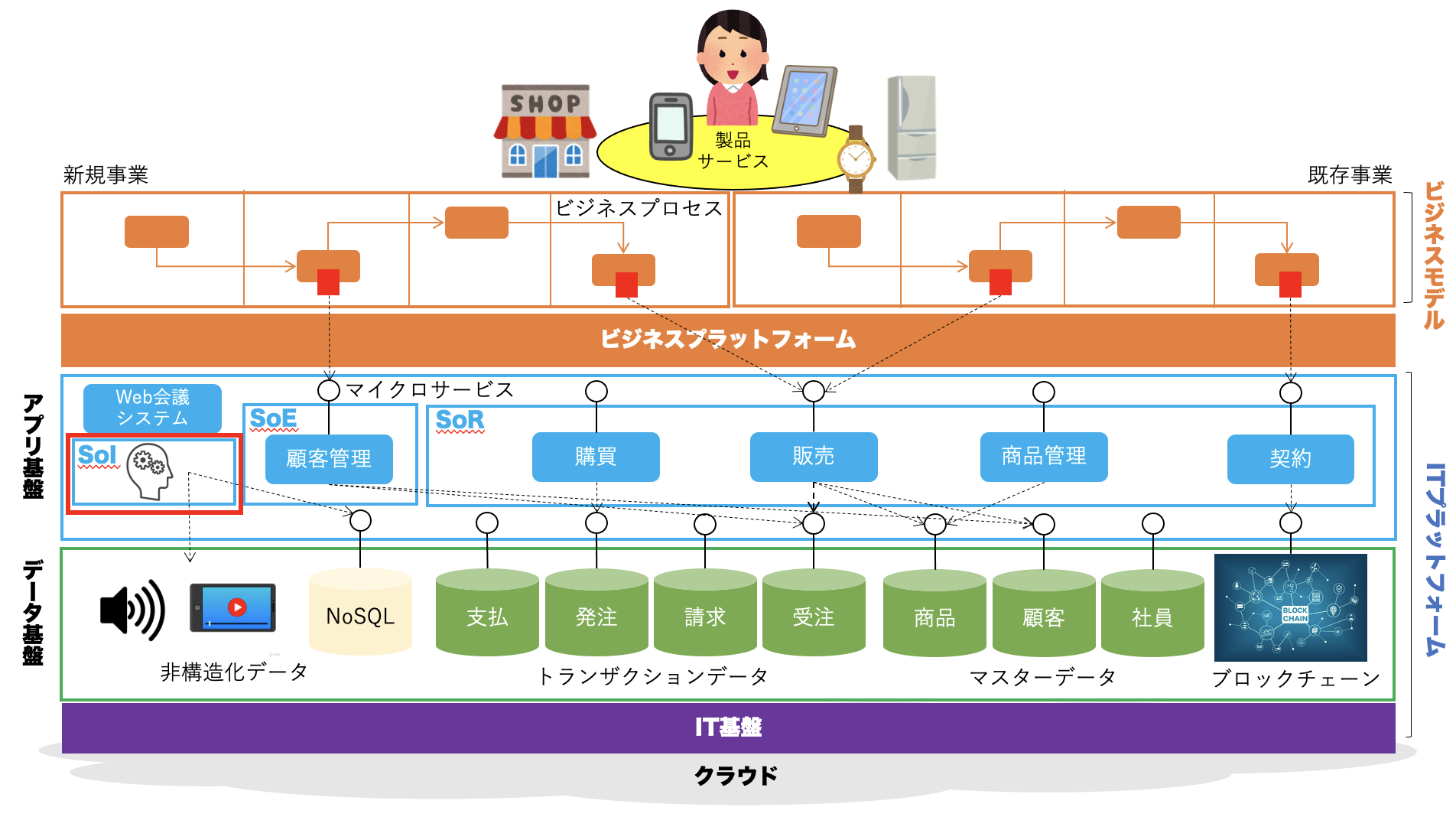
これは、DXによって会社が目指すべき姿を表した図です。
これを見ると、データサイエンスは、アプリケーション基盤のSoI(System of Insight)、つまり、AIや機械学習の技術を利用してデータを分析し顧客の欲求や行動心理を洞察するためのシステム群、として位置付けられていることがわかります。
データサイエンスのプロセス
ここから、データサイエンスの中身について一つ一つ見ていきましょう。
まず、データサイエンスのプロセスからです。
データサイエンスのプロセスで有名なのが、CRISP-DM(CRoss-Industry Standard Process for Data Mining)です。
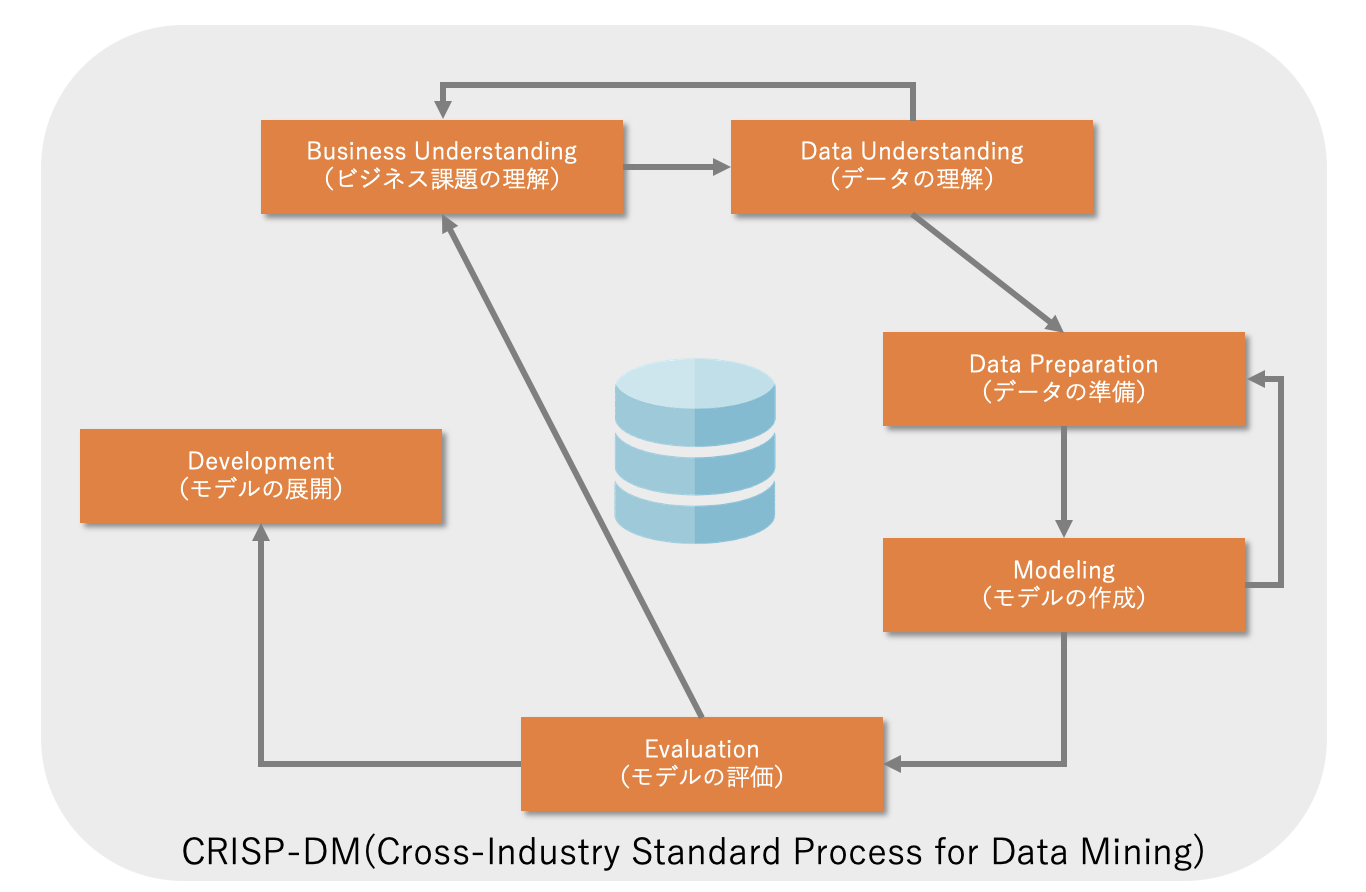
CRISP-DMでは、データサイエンスのプロセスを以下の6つの活動に分けています。
- ビジネス課題の理解
- データの理解
- データの準備
- モデルの作成
- モデルの評価
- モデルの展開
一つ一つ見ていきましょう。
ビジネス課題の理解
まず、データを利活用して解決すべきビジネス課題を明確にします。
※CRISP-DMでは、データサイエンスを適用する問題領域(ドメイン)をビジネスとして考えています。
いくら性能、精度の高い機械学習モデルを作っても、何の課題も解決しないのであれば「役に立たないモデル」ということになります。
なので、まず、ビジネス課題を分解、構造化し、機械学習モデルを構築して解決することができる小さな課題(タスク)として再定義します。
人工知能の技術や理論と、それによって解決できる小さなタスクには以下のようなものがあります。
- 分類(classification)
タスクの例
商品を買ってくれるのはどの顧客か明確にする。 - 回帰(regression)
タスクの例
ある顧客がどれだけ商品を買ってくれるか明確にする。 - 類似性マッチング(similarity matching)
タスクの例
優良顧客と類似する顧客は誰か明確にする。 - クラスタリング(clustering)
タスクの例
特定の目的を持たせずに顧客の母集団をグルーピングする。 - 共起グルーピング(co-occurrence grouping)
タスクの例
どの商品とどの商品が一緒に購入されるか明確にする。 - プロファイリング(profiling)
タスクの例
ある顧客の母集団における典型的な振る舞いは何か明確にする。 - リンク予測(link prediction)
タスクの例
顧客同士のつながりの有無や程度はどうなっているか明確にする。 - データ削除(data reduction)
タスクの例
大量のデータから余分なデータを削ぎ落とし、重要な情報を含んだ小さなデータセットに変換する。 - 因果モデリング(causal modeling)
タスクの例
何が顧客の購買行動の原因になっているのか明確にする。
ここで、ビジネス課題を、ビジネス全体の中で考えてみましょう。
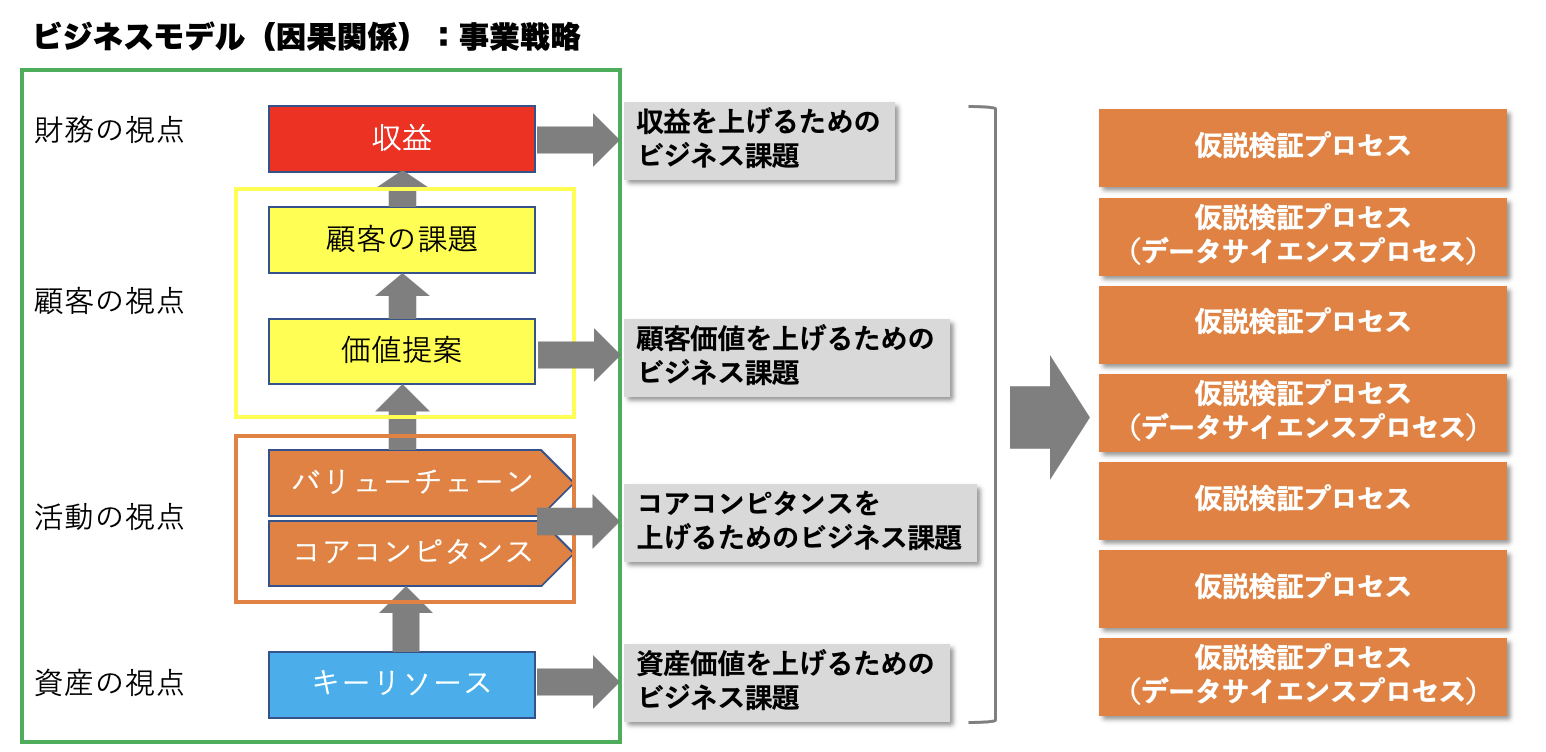
まず、ビジネスには、ビジネス課題の因果関係として表される事業戦略があります。
ビジネスは、営利活動なので、最終的には収益を上げる必要がありますが、
そのめには顧客に対して、顧客の持つ課題を解決す顧客価値を提供する必要があります。
また、顧客価値をどのように届けるのかバリューチェーンを設計し、それを構成する各活動を遂行するために必要なコアコンピタンス、つまり、他社が真似できない会社の中核的能力を上げる必要があります。
そして、コアコンピタンスを担う企業の重要な資産(人、もの、金、情報)は何か定義し、その資産価値を高めいく必要があります。
なので、一般的に企業には以下のような課題があります。
- 収益を上げるためのビジネス課題
- 顧客価値を上げるためのビジネス課題
- コアコンピタンスを上げるためのビジネス課題
- 資産価値を上げるためのビジネス課題
このようなビジネス課題を解決するために、仮説検証プロセス(科学的アプローチ)を繰り返し実行するのですが、その解決方法の一つとしてデータサイエンスがあるのです。
データの理解
さて、データを利活用して解決すべきビジネス課題が明確になったら、次に、ビジネス課題を解決するために必要なデータの有無、場所、品質について調査します。
データの有無
ビジネス課題を分解、構造化し、機械学習モデルを構築して解決することができる小さなタスクとして再定義できていれば、それに必要なデータの見当をつけることができます。
必要なデータが社内にあるかないか調査する場合、メタデータが管理されていると便利です。
メタデータとは、データに関するデータのことで、主にデータの品質を管理する目的で収集、管理されます。
メタデータには、データの属性、保管場所、ライフサイクルなどがあります。
※メタデータについての詳細について知りたい方は、データマネジメント知識体系(DMBOK)をご覧ください。
データの場所
必要なデータが社内にある場合、どのシステムに保管されているかわかりますが、必要なデータが社内にない場合、それを外部から購入することを検討し、どの組織からデータを購入することができるか調査します。
データを外部から購入する場合、データという資産を入手するための投資として考え、必要な費用を明確にしておきます。
データの品質
たとえ必要なデータが社内にあっても、データの品質が低いと問題です。
DMBOKでは、品質の低いデータがもたらす事象の例として以下をあげています。
- 誤請求
- 顧客サービスコールの増加とそれを解決する能力の低下
- 事業機会の逸失による収益損失
- 合弁・買収の間に発生する業務統合の遅延
- 不正行為発覚の増加
- 不正なデータに起因する業務上の意思決定不備がもたらす損失
- 良好な信用力の欠如による事業の損失
データサイエンスの観点で考えた場合、上記3番や6番が該当します。
それでは、データ品質はどのように評価するのでしょうか。
DMBOKでは、代表的なデータ品質の評価軸について以下のように説明しています。
- 正確性
データが現実の実体を正しく表している程度を表す。 - 完全性
必要なデータが全て存在しているかどうか、その程度を表す。 - 一貫性
データが、特定のデータベースなどデータセット内で一貫して(正しいルールに貫かれて)表現されているか、あるいは、データセット間で一貫して関連付けられ、一貫して表現されているか、その程度を表す。
一貫性は、1レコード内にある属性値と別の属性値との間(レコードレベルの一貫性)、あるレコードの属性値と別のレコードの属性値の間(クロスレコードの一貫性)、あるレコードの属性値と異なる時点における同じレコードの属性値との間(経時的一貫性)において定義される。 - 一意性
同じ実体を表すデータが同じデータセット内に複数存在していないか、その程度を表す。 - 適時性
データが適切な時点のものであるか、その程度を表す。
品質の低いデータは、次のデータの準備段階で品質を上げる処理をする必要があります。
データの準備
ビジネス課題を解決するために必要なデータが明確になったら、それを準備する必要があります。
データの利活用に必要なデータは、ETLかELTによって統合されます。
ETLのEはExtract(抽出)、TはTransform(変換)、LはLoad(取込)を表しています。
ETLとELTは、アプリケーション間や組織間でデータをやり取りするときのプロセスです。
ETLやELTは、
定期的に予定が組まれたバッチ処理や
データが利用可能になった時点におけるイベント駆動処理やリアルタイム処理
で実行されます。
ETLかELTは、Transform(変換)機能の多さによって選択します。
より多くの変換機能がある場合は、一旦、取り込んだ後に変換するELTが選択されます。
次の図は、構造化データと非構造化データのデータ統合とデータ利活用を表したものです。
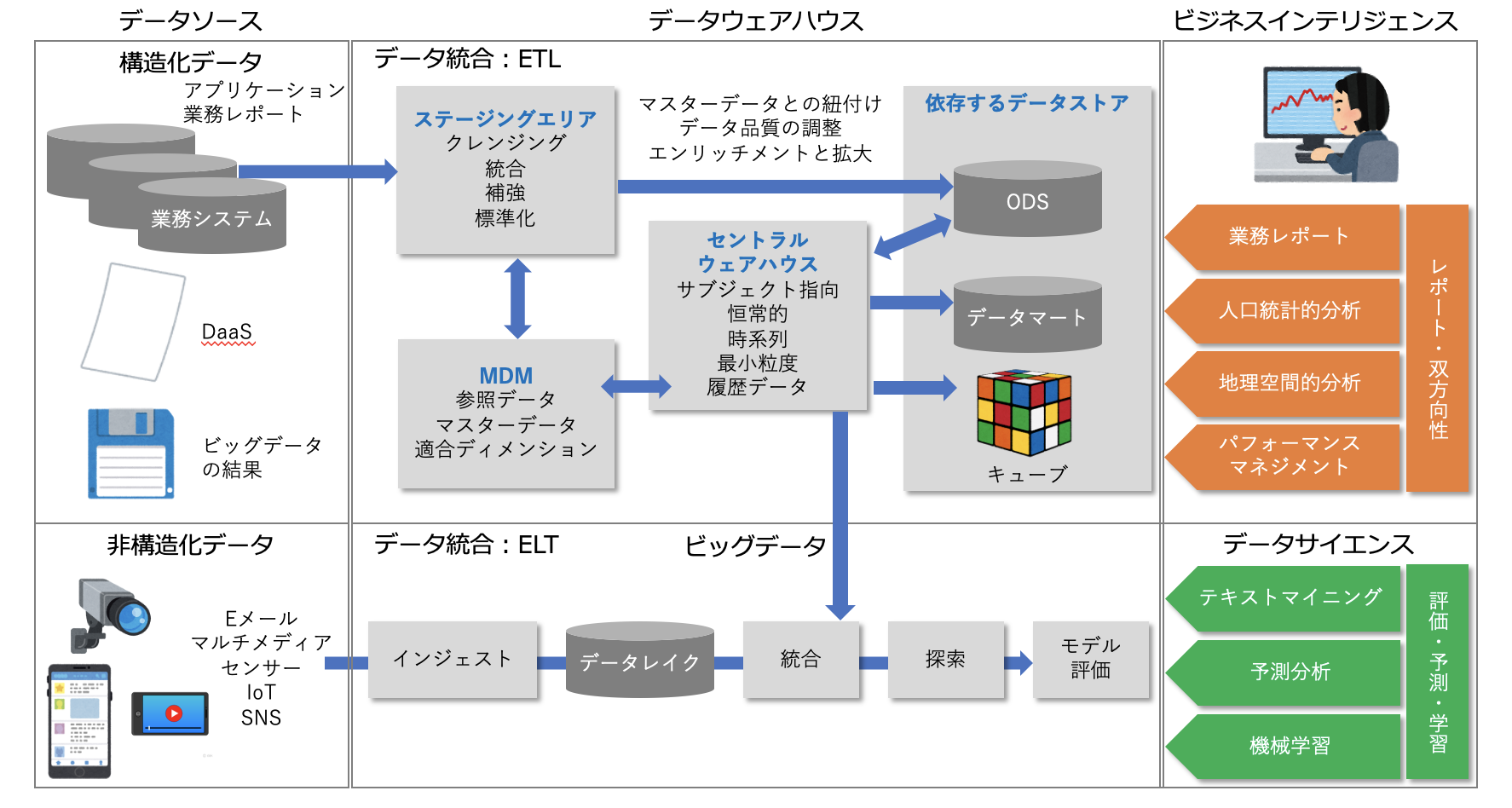
図:データウェアハウスとビッグデータのアーキテクチャ 出典:データマネジメント知識体系 第二版
この図の上段は、基幹システムの構造化データをデータウェアハウスにETLで取り込んで統合する例を示しています。
その際、リレーショナルモデルの構造化データは、ディメンショナルモデルの構造化データに変換されます。
下段は、IoTはSNSなどで発生する非構造化データをデータレイクに一旦取り込んだあと必要に応じて様々なデータセットに変換する例を示しています。
データサイエンスの場合、この図の下段が該当しますが、機械学習モデルを構築する際、適用されるモデルによって必要となるデータセットの形式が異なるためELTが採用されています。
さて、データ統合によって必要なデータを準備することができますが、データに欠損がある、データが最新になっていないなど、データの品質に問題があるデータは使えません。その場合、欠陥のあるデータを除外する、あるいは、データの欠陥を補完するなどデータの品質を上げる処理(データのクレンジング)を行う必要があります。
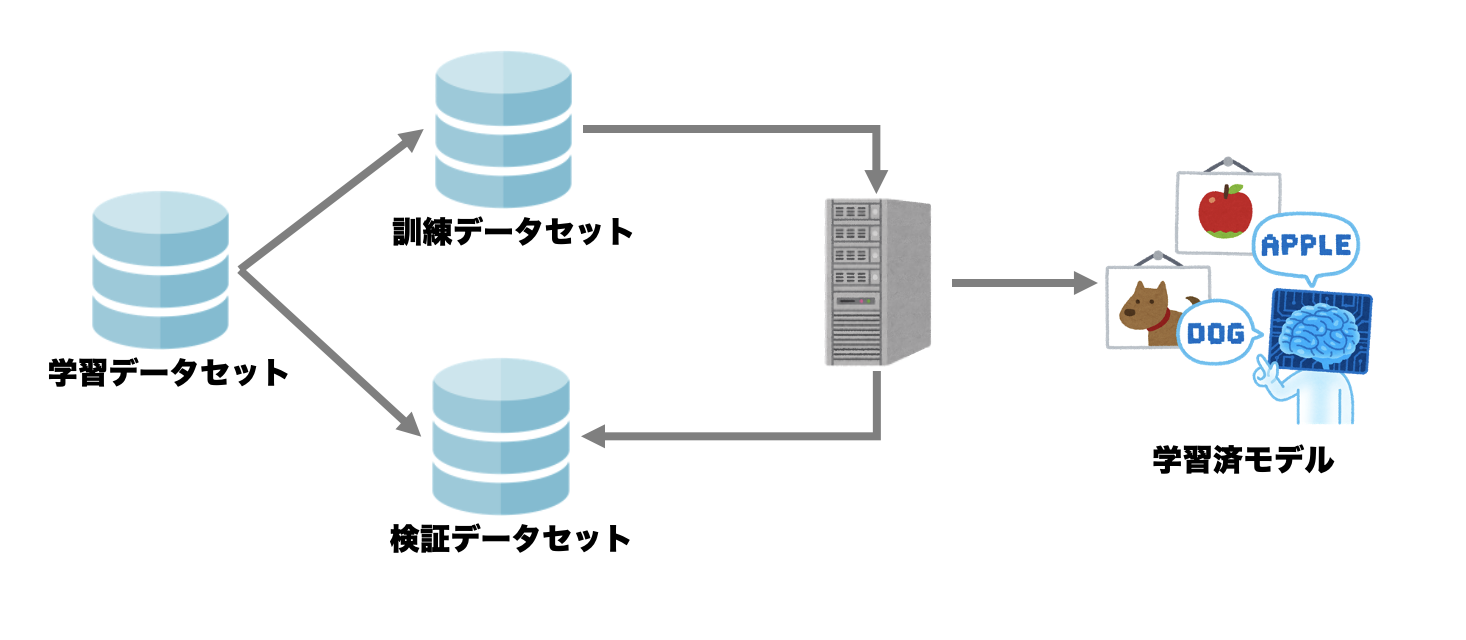
なお、機械学習で使うデータは大きく3種類に分けることができます。
- 訓練データ
機械に学習させて機械学習モデルを構築させるために与えるデータのことです。
訓練データの集合を訓練データセットといいます。 - 検証データ
CRISP-DMの「モデルの作成」で使う学習用データには、訓練用の訓練データと検証用の検証データがあります。
学習はあくまで訓練データを使って行いますので、学習で構築されるモデルは訓練データを推定するのに適したものになります。
しかし、それでは訓練データに入っていないデータに対して推定ができない(汎用性が低い)モデルになるので、汎用性を確認するために検証データを使います。
同じデータセットで何回も何回もトレーニングすると、そのデータセットだけに強いモデルになってしまい、それ以外のデータセットに対する認識率が下がってしまう(汎用性が低くなる)ことを過学習(オーバーフィッティング)といいます。
検証データの集合を検証データセットといいます。 - テストデータ
CRISP-DMの「モデルの評価」のときに使うのがテストデータです。
検証データで検証すれば汎用性は十分かと言うとそうとは言えません。
検証の結果、良い精度が出せなかった場合、検証データに対しても精度が上がるようにモデルをチューニングします。
そのため、最後に、学習用データとは別のテストデータ(訓練にも検証にも出てこなかったデータ)でモデルの最終評価を行う必要があります。
テストデータの集合をテストデータセットといいます。
モデルの作成
データの準備ができたら、訓練データを使って機械に学習をさせ、検証データを使って汎用性を確認しながら学習済の機械学習モデルを構築します。
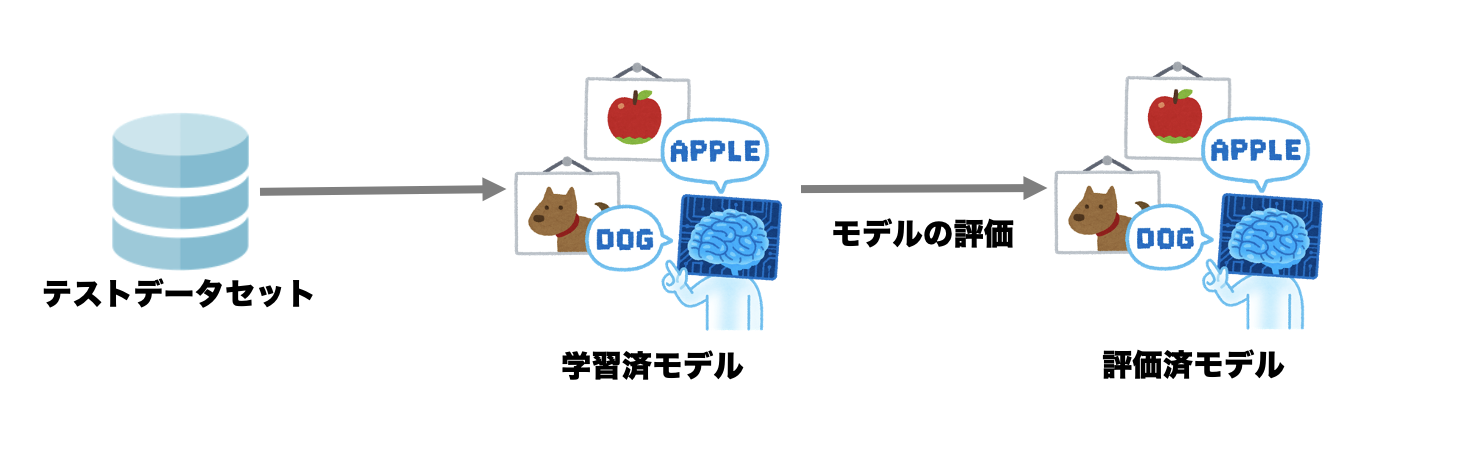
モデルの評価
学習済の機械学習モデルが構築できたら、以下のようは方法で、それを評価します。
- 精度の評価
- 期待値による評価
- 統計的な評価
精度の評価
学習用データとは別のテストデータ(訓練にも検証にも出てこなかったデータ)を使って、モデルの汎用性も含めて精度の最終評価をします。
例えば、分類(Classification)によって、オファーを出せば購入してくれる顧客を予測するモデルが次のように予測したとします。
※表の各セルは顧客数を表します。

ここで、実際に購入した顧客をy、実際には購入しなかった顧客をn、モデルによって購入すると予測された顧客をY、モデルによって購入しないと予測された顧客をNを表します。
すると、この予測モデルの精度は、
(56+42)/(56+5+7+42)=98/110≒0.89
で約89%ということになります。
期待値による評価
期待値は、機械学習モデルがビジネス課題をどの程度解決できるか、期待できる程度を表します。
例えば、機械学習モデルを適用することによって利益がどの程度上がるのかわかれば、それが期待値(期待利益)になります。
機械学習モデルを構築する最終目的はビジネス課題の解決です。
いくら精度の高い機械学習モデルを作っても、ビジネス課題を解決しないのであれば「役に立たないモデル」ということになります。
なので、モデルを適用することで、どの程度、ビジネス課題が解決されるかをもってモデルを評価することはとても意義があります。
期待値は、「事象の発生確率」と「事象による値」の積の総和になります。
期待値=Σ(事象の発生確率×事象による値)
事象の発生確率は、予測モデルが予測した値を使いますが、事象による値は、ビジネスの内容を考えて決めます。
ここで注意する必要があるのは
- 事象の種類
- 事象の割合
です。
例えば、正しいか誤りか判断する予測モデルがあるとしましょう。
この場合、予測の結果として考えられる事象の種類としては以下が考えられます。
- 真陽性(true positive)
実際に正しいものを予測モデルが正しいと判断する場合 - 偽陰性(false negative)
実際には正しいものを予測モデルが誤りと判断する場合 - 偽陽性(false positive)
実際には誤っているものを予測モデルが正しいと判断する場合 - 真陰性(true negative)
実際に誤っているものを予測モデルが誤りと判断する場合
また、それぞれの事象の種類によって、事象による値が異なる可能性があります。
例えば、真陽性の場合に発生する収益やコストと、偽陽性の場合に発生する収益やコストは違うかもしれません。
なので、それぞれの事象の発生確率で事象による値を重み付けして期待値を算定する必要があります。
もう一つ注意すべきは、事象の割合です。
上の例でいうと、母集団において、正しいものと誤っているものの割合はどうなっているのかということです。
正しいものと誤っているものが必ずしも半分半分になっているとは限りません。
二つの予測モデルがあり、それぞれ事象の発生確率の予測が異なる場合、テストデータセットにおける事象の割合が異なるとモデルの評価結果が異なってきます。
なので、期待値で評価する場合、事象の種類と事象の割合を考慮して期待値を算定する必要があります。
それから、外部機関からデータを購入するなど、資産としてのデータを獲得するに必要な費用が発生する場合、それと期待値によって投資対効果(ROI)を算定することができます。
ここで、もう少し具体的に考えてみましょう。
例えば、機械学習によって解決できる小さなタスクを、
分類(Classification)によって、オファーを出せば購入してくれる顧客を予測する
とします。
すると、機械学習モデルの予測結果として以下のような事象が考えられます。
- 真陽性(true positive)
実際にオファーを出せば購入してくれる顧客を「オファーを出せば購入してくれる顧客」と予測する場合 - 偽陰性(false negative)
実際にオファーを出せば購入してくれる顧客を「オファーを出しても購入してくれない顧客」と予測する場合 - 偽陽性(false positive)
実際にはオファーを出しても購入してくれない顧客を「オファーを出せば購入してくれる顧客」と予測する場合 - 真陰性(true negative)
実際にはオファーを出しても購入してくれない顧客を「オファーを出しても購入してくれない顧客」と予測する場合
ここで、実際の真をy、実際は偽をn、モデルによって予測された真をY、モデルによって予測された偽をNとし、モデルが予測する各事象の確率を以下のように表します。
- 真陽性(true positive)
p(y,Y) - 偽陰性(false negative)
p(y,N) - 偽陽性(false positive)
p(n,Y) - 真陰性(true negative)
p(n,N)
次に、オファーを出せば購入してくれる顧客が商品を購入した場合の利益を100ドル、オファーを出すためのコストが1ドルとします。
すると、各事象ごとの利益をbenefitのbで表すと以下のようになります。
- 真陽性(true positive)
顧客は商品を購入してくれるのでオファーを出すコストを考えると、
b(y,Y)=99 - 偽陰性(false negative)
モデルが顧客は商品を購入しないと予測し、オファーも出さないので
b(y,N)=0 - 偽陽性(false positive)
モデルが顧客は商品を購入すると予測し、オファーを出すが商品は購入されないので
b(n,Y)=-1 - 真陰性(true negative)
モデルが顧客は商品を購入しないと予測し、オファーも出さないので
b(n,N)=0
そうすると、期待利益は次のような式で算出することができます。
期待利益=p(y,Y)・b(y,Y)+p(y,N)・b(y,N)+p(n,Y)・b(n,Y)+p(n,N)・b(n,N)
ここで、母集団における事象の割合、p(y)とp(n)を考慮します。
すると、期待利益は次の式で表すことができます。
期待利益=p(y)・[p(Y|y)・b(y,Y)+p(N|y)・b(y,N)]+p(n)・[p(Y|n)・b(n,Y)+p(N|n)・b(n,N)]
※
例えば、p(Y|y)は、事象yが発生することを条件として事象Yが発生する条件付確率を表します。なので、p(y,Y)=p(y)・p(Y|y)です。
さて、事象の割合、p(y)とp(n)を考慮することによって、2つの予測モデルAとBがあり、Aがp(y):p(n)=5:5のテストデータセットで評価し、Bがp(y):p(n)=3:7のテストデータセットで評価しても、AとBでp(y)とp(n)を揃えて計算することで同じ条件で評価することができます。
つまり、事象の割合をくくり出すことで、その影響を分離することができるのです。
それでは、実際の数値を当てはめて考えてみましょう。
いま予測モデルが各事象の顧客数を次のように予測したとします。
すると、
p(y)=61/110=0.55
p(Y|y)=56/61=0.92
p(N|y)=5/61=0.08
p(n)=49/110=0.45
p(Y|n)=7/49=0.14
p(N|n)=42/49=0.86
期待利益=0.55・[0.92・99+0.08・0]+0.45・[0.14・-1+0.86・0]≒50.03
となり、このモデルを適用して「オファーを出せば購入してくれる顧客」にオファーを出すと、顧客1人当たり約50ドルの利益を期待できるということになります。
統計的な評価
これは、実際にビジネスが扱うデータに対して機械学習モデルを適用して、その効果を統計的に測定するということです。
例えば、実際にビジネスが扱う集団を、機械学習モデルを適用する処理群(treatment group)と、適用しない対照群(contrast group)に分けてビジネスを行った結果、統計的な有意差が出るか測定する仮設検定という方法があります。
モデルの展開
機械学習モデルの評価が終わり、それがビジネス課題を解決できると確認できたら、そのモデルを情報システムやビジネスプロセスに組み込み、実際のビジネスに展開します。
例えば、他社に乗り換える可能性の高い会員を予測するモデルの場合、そのモデルを会員管理システムに組み込み、乗り換える可能性の高い会員にスペシャルオファーを送る仕組みを構築します。
データサイエンスの技術
ここでは、データサイエンスの技術を、さらに、
機械学習のアルゴリズムと
それを機能させるIT基盤
に分けて整理します。
機械学習のアルゴリズム
機械学習のアルゴリズムを、機械学習の学習方法、機械学習の理論で分類すると以下のようになります。
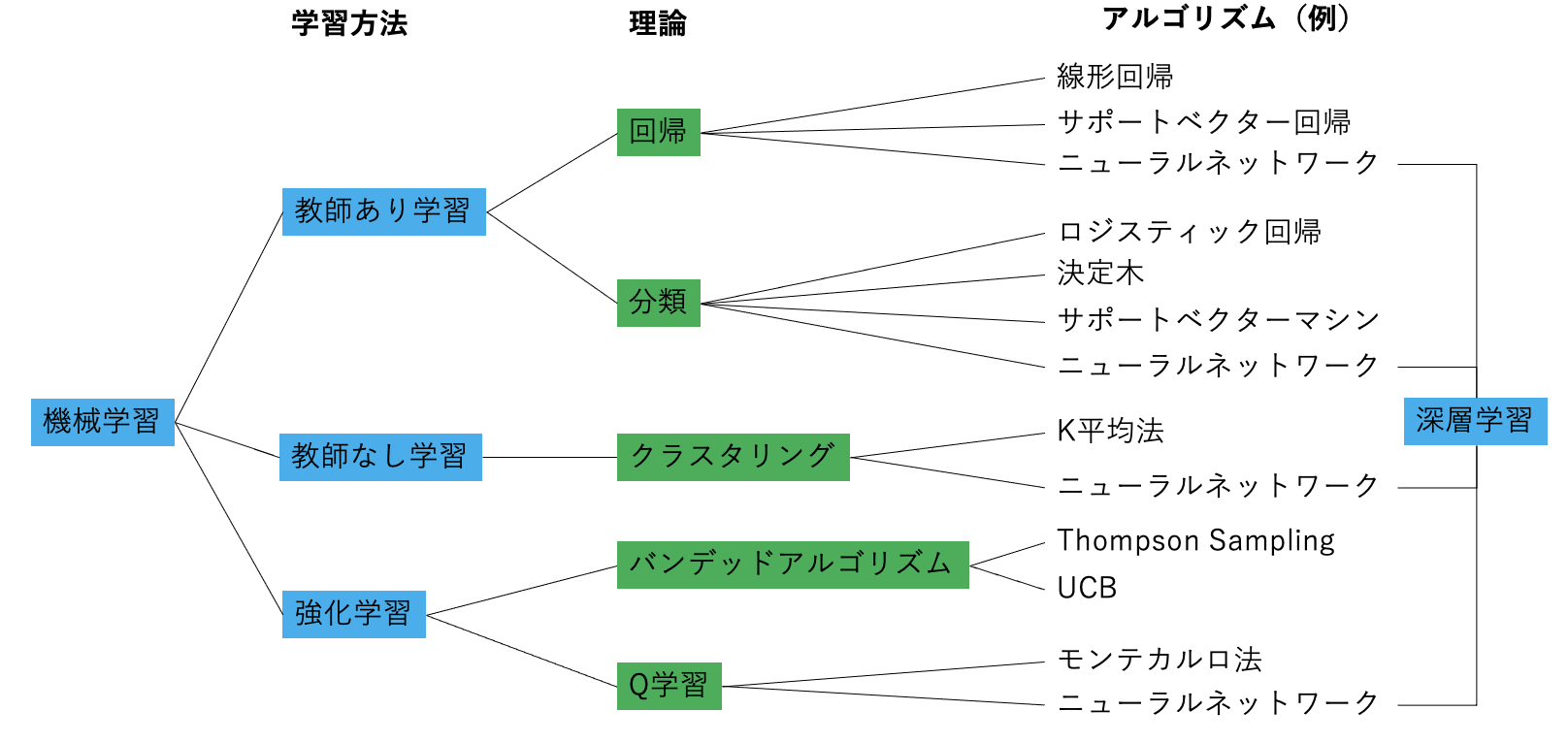
まず、機械学習の学習方法について説明します。
- 教師あり学習(Supervised Learning)
学習データに正解のラベルを付けて学習させる方法です。
値(データ)が独立的に変動する変数(属性)を説明変数(独立変数)とし、その値が決まると、それに対応して値が決まる変数を目的変数(従属変数)とすると、ラベルは目的変数に該当します。
なので、目的が明確な場合は、教師あり学習を行います。
上記、人工知能の技術や理論と、それによって解決できる小さなタスクの例でいうと、分類、回帰、因果モデリングは、一般的に教師あり学習を使います。 - 教師なし学習(Unsupervised Learning)
学習データに正解のラベルを付けずに学習させる方法です。
例えば、方向性や基準を持たず、ある集団を分類したいなど、目的が不明確な場合は、教師なし学習を行います。
上記、人工知能の技術や理論と、それによって解決できる小さなタスクの例でいうと、クラスタリング、共起グルーピング、プロファイリングは、一般的に教師なし学習を使います。 - 強化学習(Reinforcement Learning)
強化学習は、正解を与える代わりに将来の価値を最大化するように学習させる方法です。
例えば、機械が、ある環境内で現在の状態を観測し、取るべき行動を決定する場合を考えましょう。
機械は行動を選択することで環境から報酬を得るとすると、強化学習は一連の行動を通じて報酬が最も多く得られるような方策を学習します。
次に、分類基準の「理論」で示されている「分類」、「回帰」、「クラスタリング」の違いですが以下のようになります。
- 分類(Classification)
データがどのクラスに属するのか、という問題を扱うのが分類(Classification)です。
例えば、人の画像から男女を判別するように、0か1という質的データを扱います。
人工知能の技術や理論と、それによって解決できる小さなタスクの例でいうと、
商品を買ってくれるのはどの顧客か
というタスクになります。 - 回帰(Regression)
ある入力データから数値の予測を行うのが回帰(Regression)です。
例えば、人の画像から、その人の体重を予測するように、数値として意味のある量的データを扱います。
人工知能の技術や理論と、それによって解決できる小さなタスクの例でいうと、
ある顧客が「どれだけ」商品を買ってくれるか明確にする
というタスクになります。
ただし、0と1の間を確率という量的データで表すロジスティック回帰は「分類」の一種として扱います。
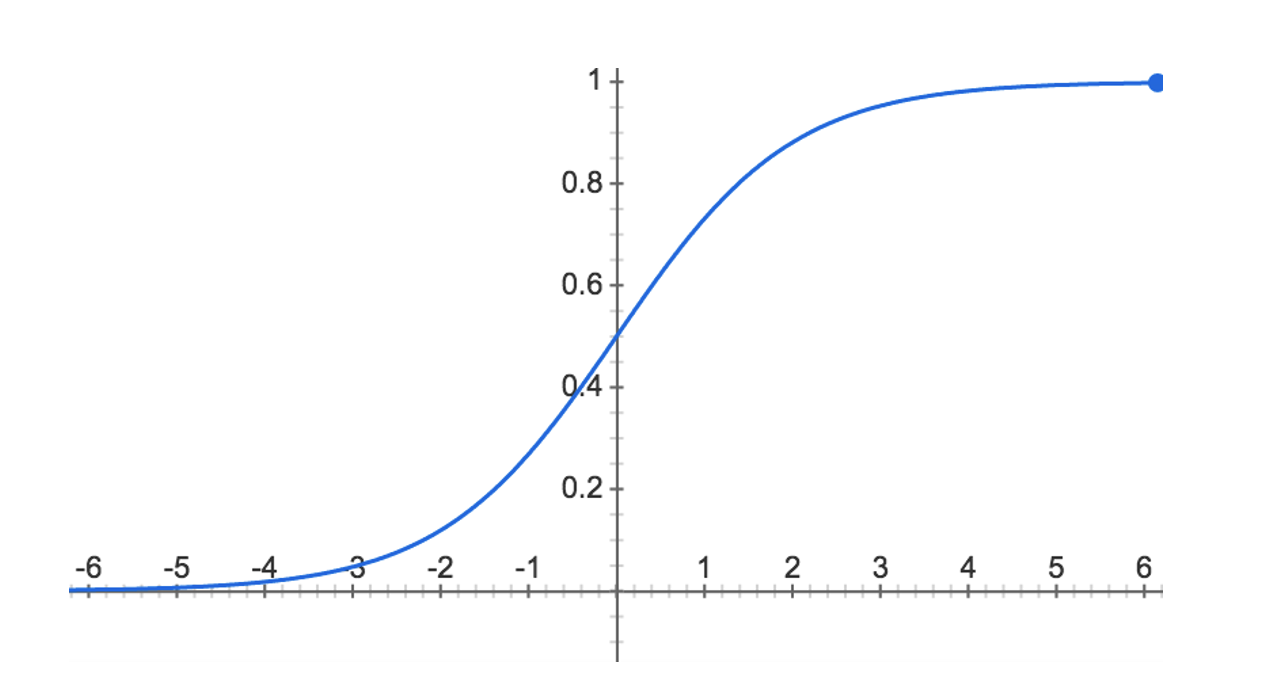
ロジスティック回帰の例 - クラスタリング(Clustering)
クラスターとは、集団やグループのことです。
なので、クラスタリングとは「様々な要素の中から似たもの同士集めてグループ化すること」です。
クラスタリングと上記「分類」は学習方法が違います。
分類(Classification)は教師あり学習ですが、クラスタリング(Clustering)は教師なし学習です。
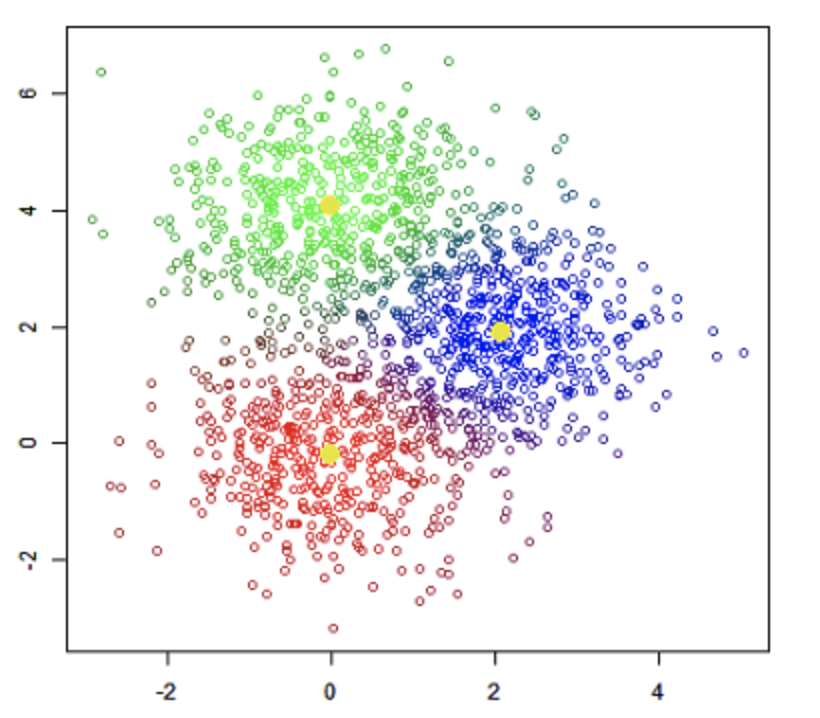
クラスタリングの例
さて、上の機械学習のアルゴリズムを分類した図を見ると、至る所にニューラルネットワークというアルゴリズムがあることがわかります。
このニューラルネットワークとは、
生物の神経ネットワークの構造と機能を模倣した学習アルゴリズム
のことです。
生物の脳はニューロンという神経細胞のネットワーク構造となっています。
ニューロンから別のニューロンにシグナルを伝達する接続部位のことをシナプスと言い、ニューロンはシナプスから電気や化学物質のシグナルを発信して情報をやり取りします。
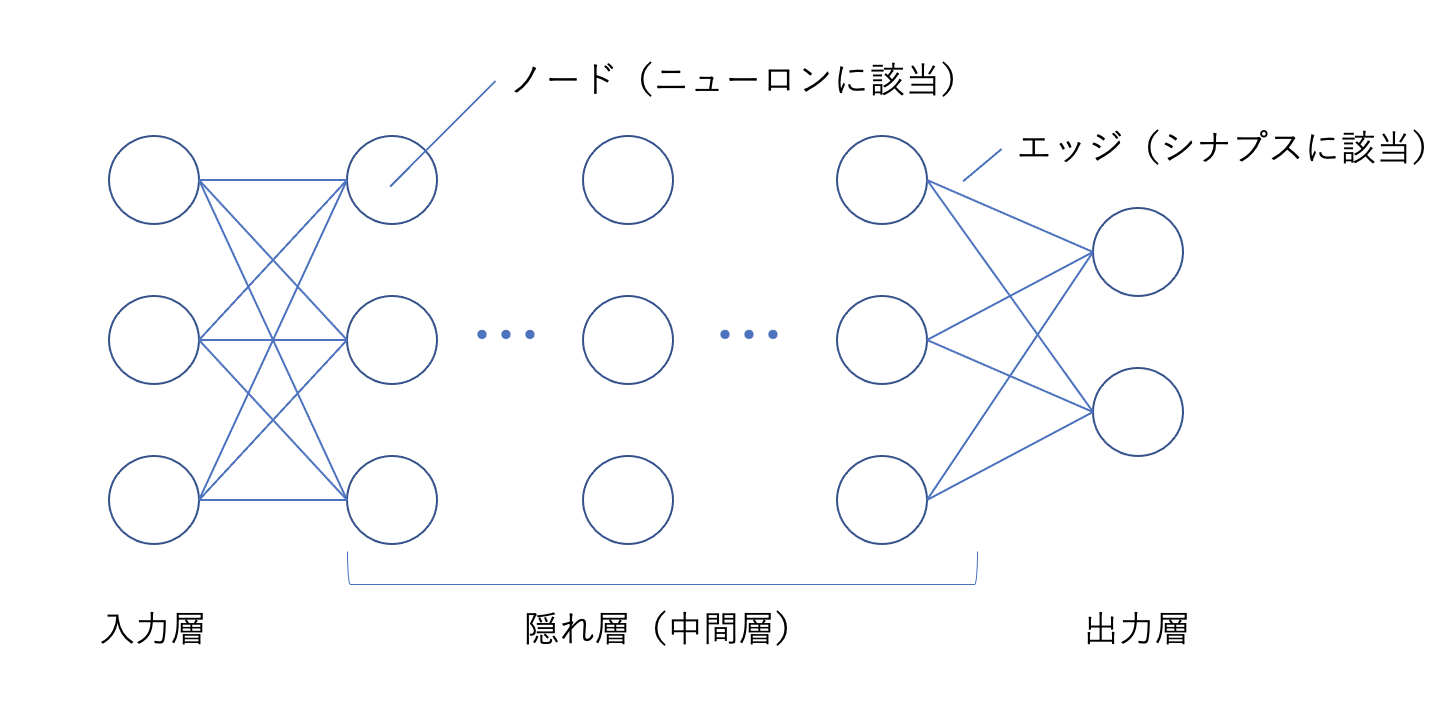
ニューラルネットワークは、入力層から入った信号が、エッジを介してノードに伝搬されて出力層に伝わる仕組みになっています。
これは、神経細胞のニューロンを通じて信号が伝搬する仕組みと同じです。
入力層と出力層の間の中間層を隠れ層といい、これが何層にも重なっているものが深層学習(ディープラーニング)です。
機械学習のIT基盤
ここでは、機械学習のIT基盤を
- ハードウェア
- 機械学習ライブラリ
- 機械学習プラットフォーム
という観点で説明します。
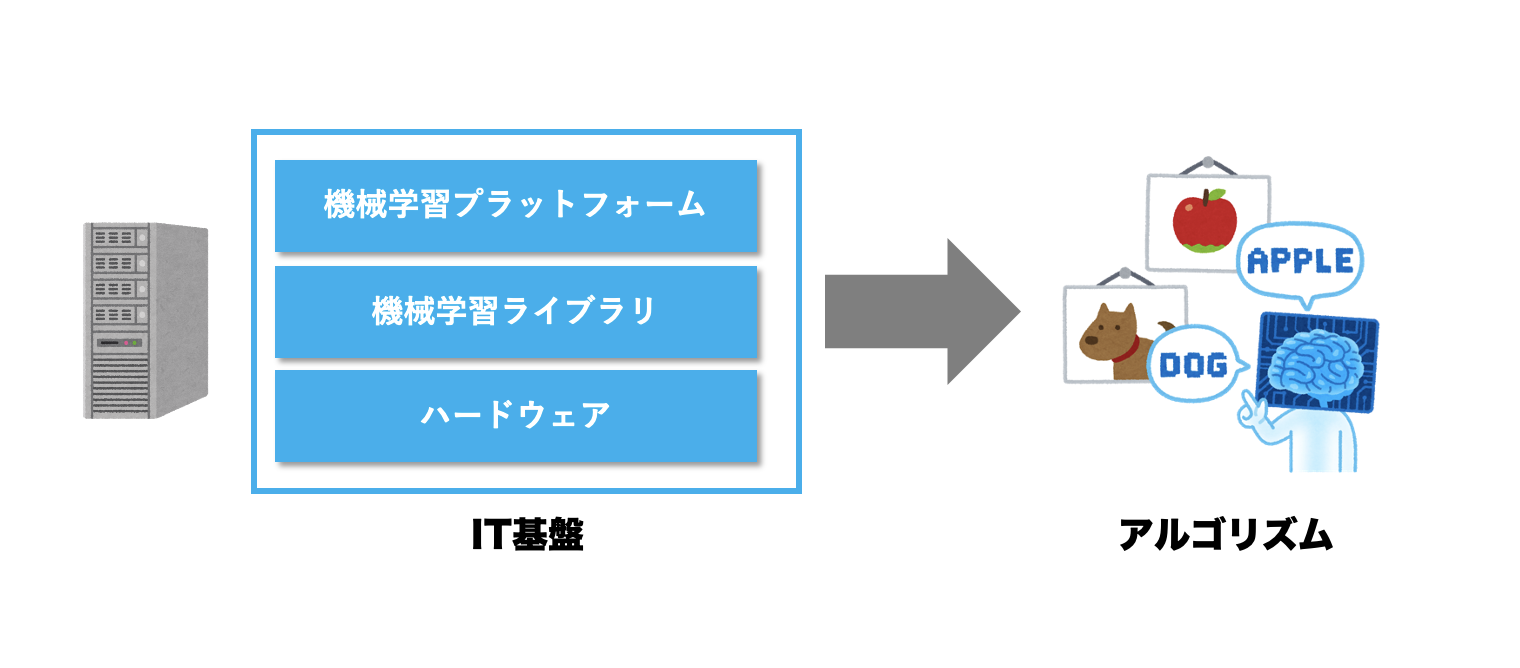
※なお、データベースや、ビッグデータを並列分散処理するHadoopは、機械学習に特化した技術ではないためここでは言及しません。
ハードウェア
例えば上記のニューラルネットワーク演算など、機械学習に求められる高速処理は、もはやCPUだけでは対応しきれないため、GPUやFPGA、ASICといった高速処理チップが使われています。
また、人工知能サービスの多くはクラウドコンピューティングで提供されていますが、IoTの普及とともに最近注目されているのがエッジコンピューティングです。
これは、ユーザーの近くにエッジサーバーを設置してその上で人工知能を働かせることにより、ネットワークコストを抑えて処理速度を上げるというものです。
機械学習ライブラリ
現在、さまざまな機関から、既にあるアルゴリズムを実装したプログラム機能が機械学習ライブラリとして提供されています。
エンジニアが機械学習モデルを構築するときは、ゼロからアルゴリズムを実装するわけではなく、機械学習ライブラリを利用して構築します。
例えば、有名な機械学習ライブラリに、GoogleのTensorFlowがあります。
機械学習プラットフォーム
上記機械学習ライブラリを使って画像認識や音声認識などの学習を行い、目的別にユーザーが利用しやすいサービスとして提供しているものが機械学習プラットフォームです。
ほとんどの機械学習プラットフォームはクラウドをベースとした有料サービスです。
例えばGoogle Cloud Machine Learningでは「画像認識」「動画分析」「音声認識」「機械翻訳」「自然言語理解」などの機械学習サービスを提供しています。
データサイエンスの理論
機械学習のベースとなる理論には大きく
- 統計学
- 情報科学
があります。
統計学
統計とは、観察や実験の結果を数量データで表し、そこから法則性を導き出すことで、統計学とは、統計の方法に関する理論を研究する学問のことです。
集団の一部を観察して、そこから確率理論による推測で全体の法則を把握することを統計的推測といいますが、機械学習の多くが、この統計的推測によって予測モデルを構築します。
例えば、上述した回帰(Regression)は、説明変数と目的変数の関係(回帰方程式)を定める方法ですが、これは、説明変数の変化を表す係数を、その誤差を最小にする(平均値に回帰する)論理で定めます。
この論理も、集団の一部を観察して、そこから確率理論による推測で全体の法則を把握する理論がベースになっています。
回帰方程式をグラフにしたものを回帰直線といいます。
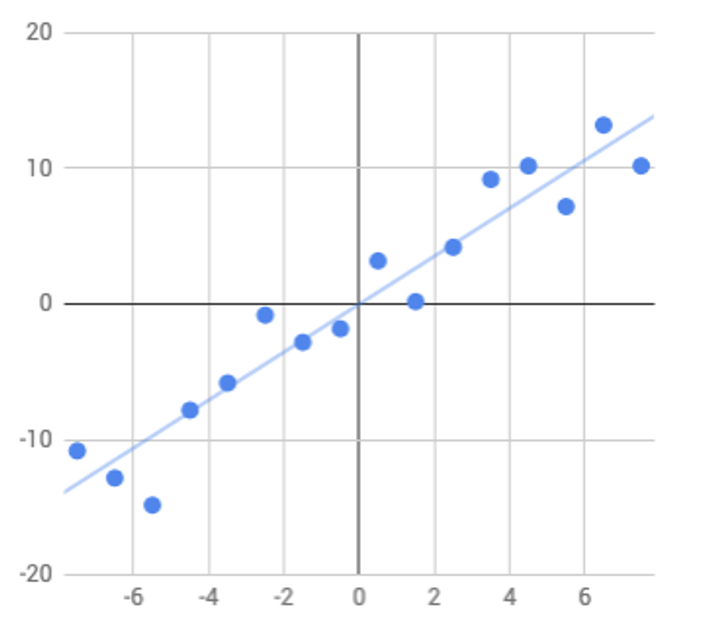
回帰直線の例
なお、例えば仮説検定など、統計は、データサイエンスのプロセスでも用いられます。
情報科学
次に、情報科学ですが、これは、コンピュータ科学ともいい、情報と計算の理論的基礎、及びそのコンピュータ上への実装と応用に関する研究分野のことです。
例えば、上述した分類(Classification)の一つ決定木(Decision tree)では、特徴の異なる要素が混じり合っている度合い(乱雑さ)を表す情報エントロピー(平均情報量)を最小にするように、分類基準となる属性(特徴)を選択(decision)します。
この情報エントロピーは、情報科学の理論になります。

決定木の例
以上、今回はデータサイエンスの全体像について説明しました。

[…] 検証プロセスがあります。 仮説検証プロセスの一つとして、データを有効活用する データサイエンス があります。 次に、ビジネスプラットフォームの上で実行する各事業をビジネスモ […]
[…] 説を検討します(改善)。 なお、データを有効活用して仮説を立案するアプローチがデータサイエンスです。 それでは、Pelotonの例で見ていきましょう。 Pelotonのバリューチェーンは主要 […]
[…] 的分析には機械学習やAIを活用します。 予測的分析、処方的分析の詳細については、データサイエンスを参照ください。 仮説立案にデータ分析を適用してみると、まず、問題を分析して […]
[…] 的分析には機械学習やAIを活用します。 予測的分析、処方的分析の詳細については、データサイエンスを参照ください。 仮説立案にデータ分析を適用してみると、まず、問題を分析して […]
[…] 以上の価値創出プロセスをまとめると次の図のようになります。 データサイエンスを適用することで、データ(事実)を活用して科学的に課題や解決策を考えることができます。 財務 […]
[…] データサイエンス データサイエンスは、データレイクに格納されたビ& […]