![]()
ここでは、DOAの考え方を適用して構築するDOA型データ基盤と、DDDの考え方を適用して構築するDDD型データ基盤について次の順で解説します。
DOA型データ基盤と、DDD型データ基盤のイメージ図は次のようになります。
集中型と分散型
まず、DOA型データ基盤とDDD型データ基盤の根本的違いを知るためにネットワーク形態について説明します。
ネットワークの形態は、大きく、集中型と分散型に分けることができます。
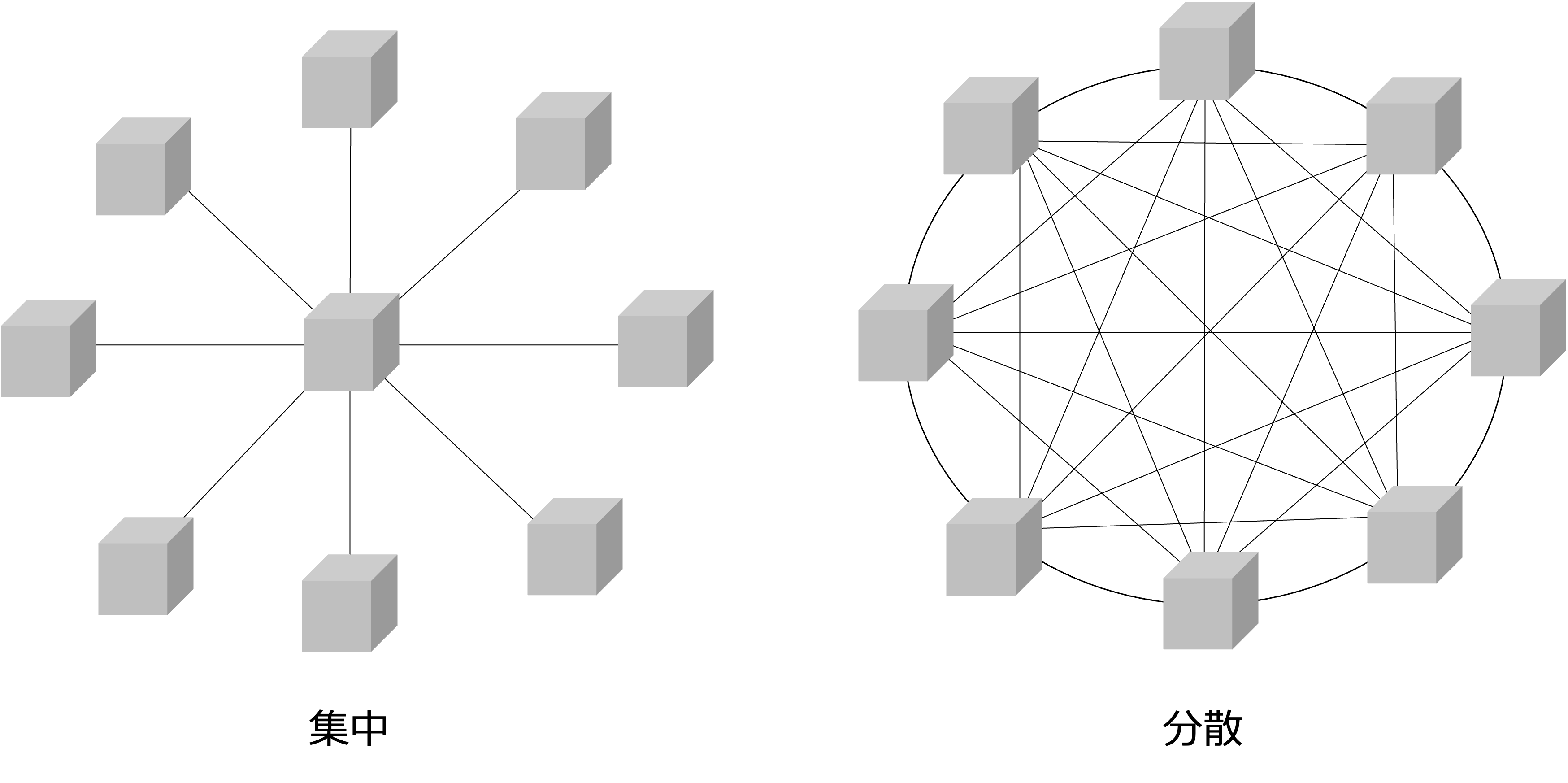
集中型は、ネットワークを構成する、あるノードを中心に他のノードが繋がっている形態で、分散型は、すべてのノードが相互に連携している形態です。
集中型の場合、中心となるノードに機能や負荷が集中するので、中心となるノードが単一障害点となり、それが機能しなくなるとネットワーク全体が機能しなくなる可能性が高くなりますが、中心となるノードだけを集中管理すればよいので管理コストやネットワークコスト(ネットワークの消費量)は比較的低くなります。
次に、分散型の場合、中心となるノードがなく、すべてのノードが相互に連携しているので機能や負荷が分散し、あるノードが機能しなくなるとネットワーク全体が機能しなくなる可能性は低いですが、すべてのノードと、それらの接続を管理する必要があるので管理コストやネットワークコストは比較的高くなります。

今回のテーマとして扱う、DOA型データ基盤は集中型になり、DDD型データ基盤は分散型になります。
なので、それぞれが、集中型、分散型のメリットとデメリットを継承します。
つまり、DOA型は、リスクは高く、コストは低い、DDD型は、リスクは低く、コストは高いということになります。
このように、集中型と分散型は、それぞれ、メリット、デメリットがあります。
ここでは、分散型のDDD型データ基盤の構築をお勧めしています。
時代は、集中と分散を繰り返します。
比較的安定した時代は、資源を集中するほうが効率がよいと思います。
しかし、昨今のように不透明で予測困難な時代は、機能を分散し、どのような事態になっても自在に形を変えられるようにしておくほうがより効果的だと思います。
また、複雑なP2P(PeerToPeer)接続にかかるコストをAIエージェントが解消すると考えられます。
DOA型データ基盤
まず、DOA型データ基盤から見ていきましょう。
データ中心アプローチ(DOA)とは
記事開発手法の変遷とドメイン駆動設計×マイクロサービスでも説明したように、データ中心アプローチ(DOA)は、処理からデータを完全に分離し、データを構造化するとともに全体で一元管理する手法です。
DOAのメリットは、データが構造化され全体で一元管理されるので、データの不整合が起こりにくいことです。
DOA型データ基盤とは
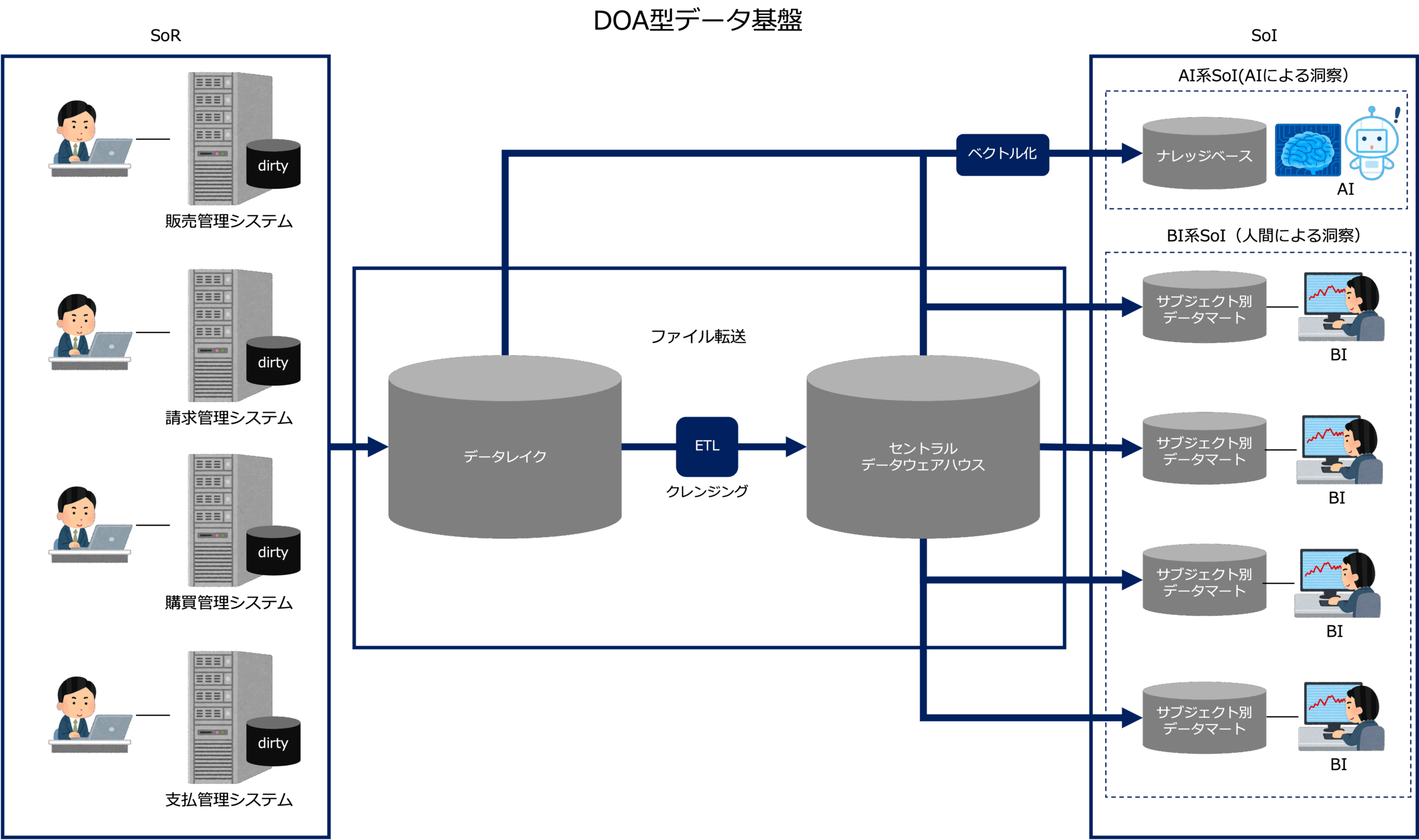
このデータを構造化して全体で一元管理するという思想に基づいて構築されるデータ基盤がDOA型データ基盤です。
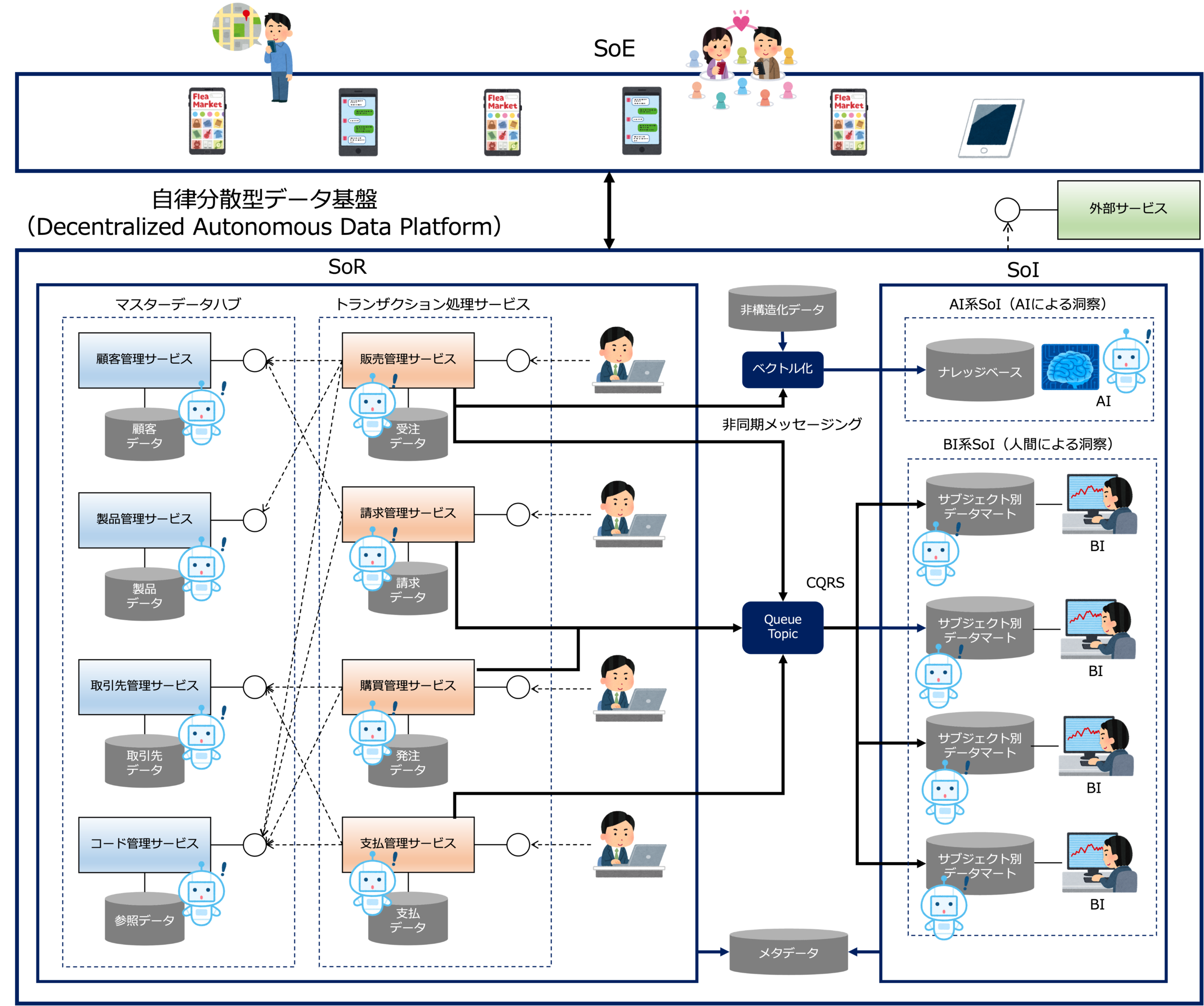
記録システム(SoR)である基幹系システムのデータを一旦、中央のデータレイクに取り込み、そのデータに対してクレンジングも含めたETL(抽出・変換・読込)処理を行い中央のデータウェアハウス(データ倉庫)に格納します。
中央のデータウェアハウスのデータは、目的別のデータマートに分割されてデータ分析で利用されます。
それから、データレイクの非構造化データも含めてデータをベクトル化し、ナレッジベースを構築することで生成AIに利用しやすい形に変換します。
データを分析することによって得られる顧客やパートナー、従業員の隠れたニーズや深層心理、つまりインサイトを理解するためのシステムをSoI(System of Insight)といいますが、ここでは、SoIを、BI(ビジネスインテリジェンス)ツールを通して人が洞察を得るBI系SoIと、AIが洞察を得るAI系SoIに分けています。
DOA型データ基盤のメリット
さて、DOA型データ基盤のメリットの一つは、データが構造化され全体で一元管理されるので、データの不整合が起こりにくいことです。
また、DOA型データ基盤には、それが集中型なので、データ基盤を構築し管理するコストが比較的低いというもう一つのメリットがあります。
現在、多くの会社では、DOA型のデータ基盤を構築しているのではないでしょうか。
その背景には、これまでツギハギして改修してきた基幹システムのデータの品質が低下してダーティになっているという事実があります。
大本(おおもと)のデータがダーティでも、中央でクレンジングして利用すれば問題ないという裏事情が潜んでいるのです。
DOA型データ基盤のデメリット
それでは、DOA型データ基盤のデメリットは何でしょうか。
それは、データが中央で一元管理されているので、中央のデータ構造の変更による利用者に対する影響が大きい、結果的に、企業の業務とシステムを変化に弱い脆弱な構造にしてしまうということです。
これは、DOA型データ基盤が集中型である故に、どうしても免れないリスクになります。
先行き不透明で予測困難な昨今、変化に柔軟に対応できないシステムはビジネスの足かせになり、企業の競争優位性を阻害する恐れがあります。
DDD型データ基盤
ドメイン駆動設計(DDD)とは
ドメイン駆動設計(DDD)とは、ドメイン(開発対象となる業務領域)を中心に据えて、システムを設計・開発する手法です。
この手法により、業務の本質を表すドメインの構造や振る舞い(業務ルールや機能)を正確にモデル化できます。
また、DDDは、ドメインの機能やデータをオブジェクトとしてモジュール化し、オブジェクト同士のメッセージングによってシステムを構成するため、再利用性や拡張性が高く、変化に強い堅牢なシステムを構築することができます。
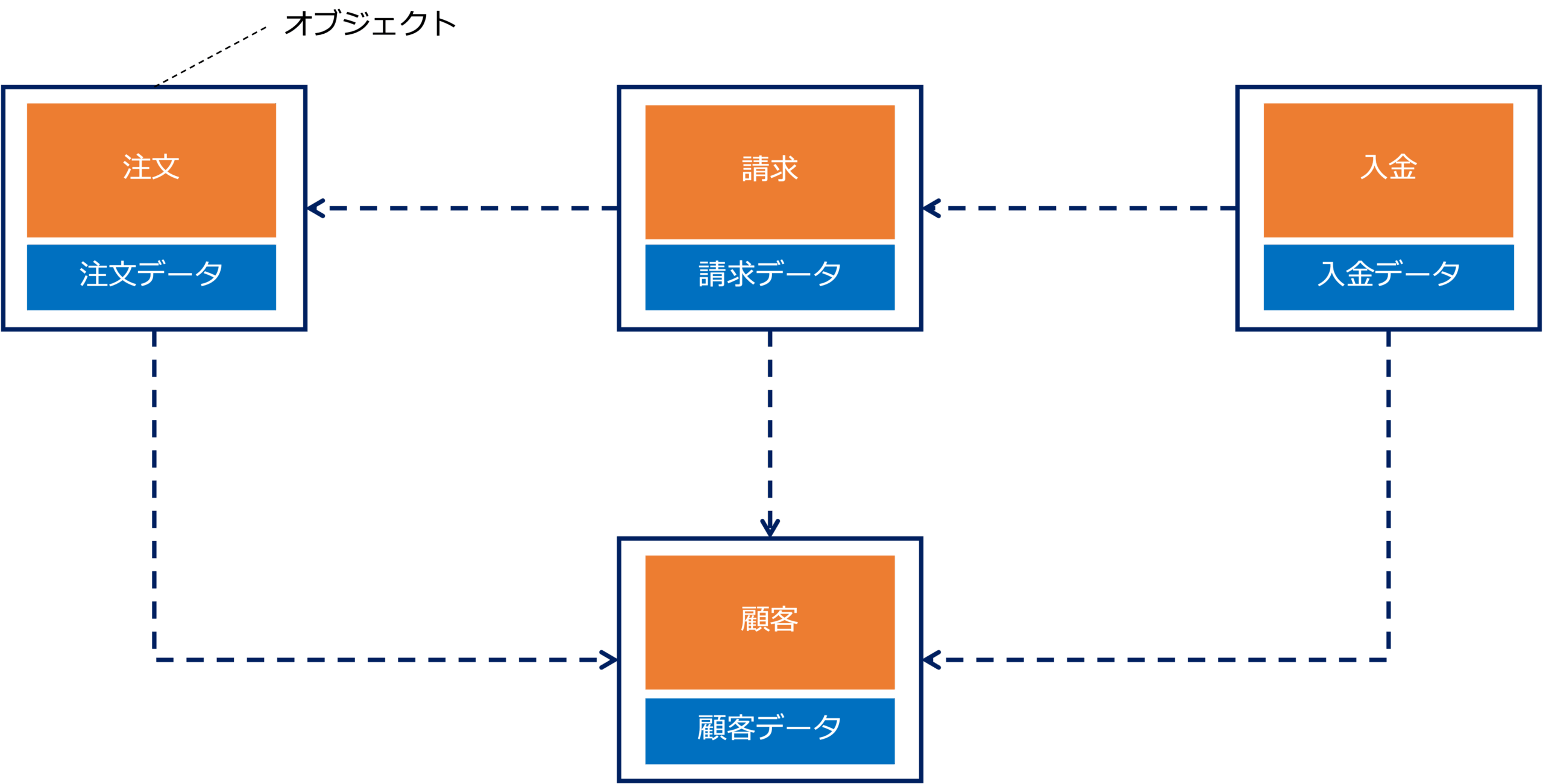
DDDの重要なポイントは、技術的な設計よりも、まず組織全体で適切な業務領域(ドメイン)をどのように定義し設計するかにあります。
すなわち、ドメイン駆動設計の本質は、究極的には業務の仕組みそのもの、すなわちビジネスアーキテクチャの設計にあるといえます。
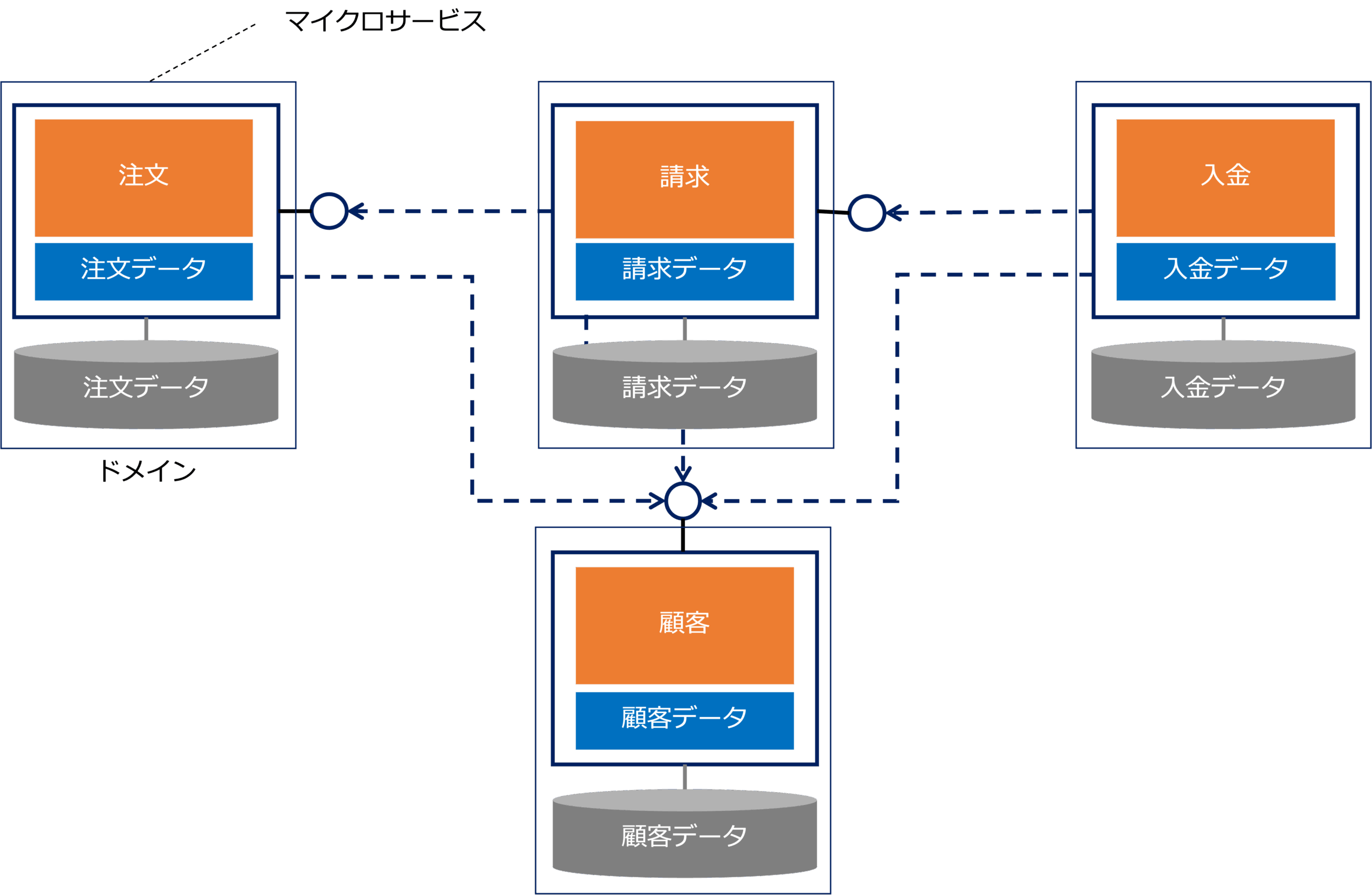
一方で、システムを構成する要素を、独立してデプロイ可能な小さなソフトウェア部品に分割し、それぞれが実現するサービスを他の部品に提供し合うことで全体のシステムを構成するという考え方が、マイクロサービスです。
一つのマイクロサービスは、そのサービスを実現するために必要なデータベースも内包します。
したがって、マイクロサービスはデータベースを含めて処理とデータをカプセル化した自律したソフトウェア部品となります。
このように、ドメイン駆動設計によって設計されたドメインごとにマイクロサービスを構築し、それらを疎結合で連携させることで、ビジネスとITが一体となり、環境の変化に柔軟に適応できる「変化に強いシステム」を実現することができます。
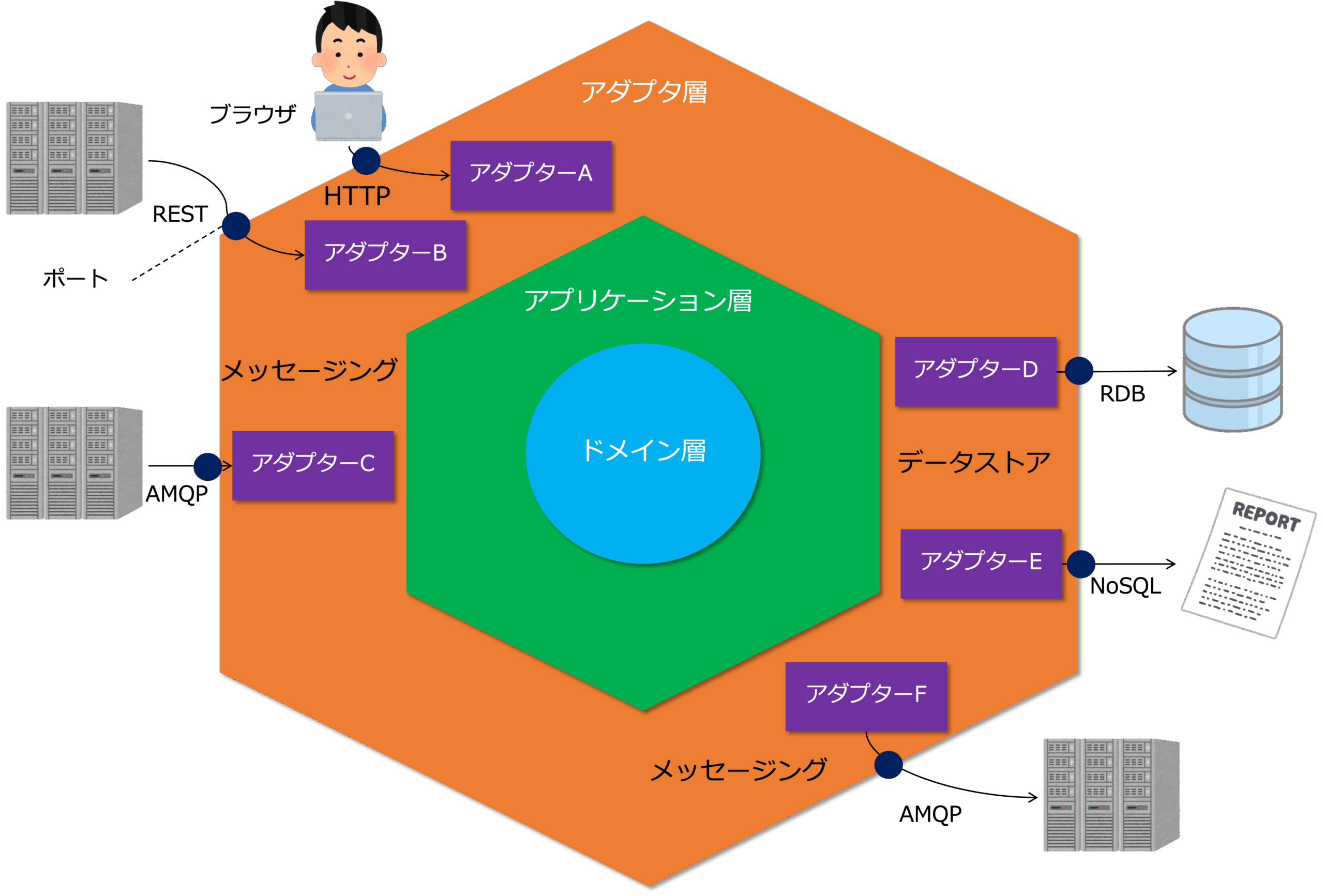
DDD型データ基盤とは
ドメイン駆動設計によって設計された業務ドメインごとにマイクロサービスを構築し、そこにデータをカプセル化することで構築するデータ基盤がDDD型データ基盤です。
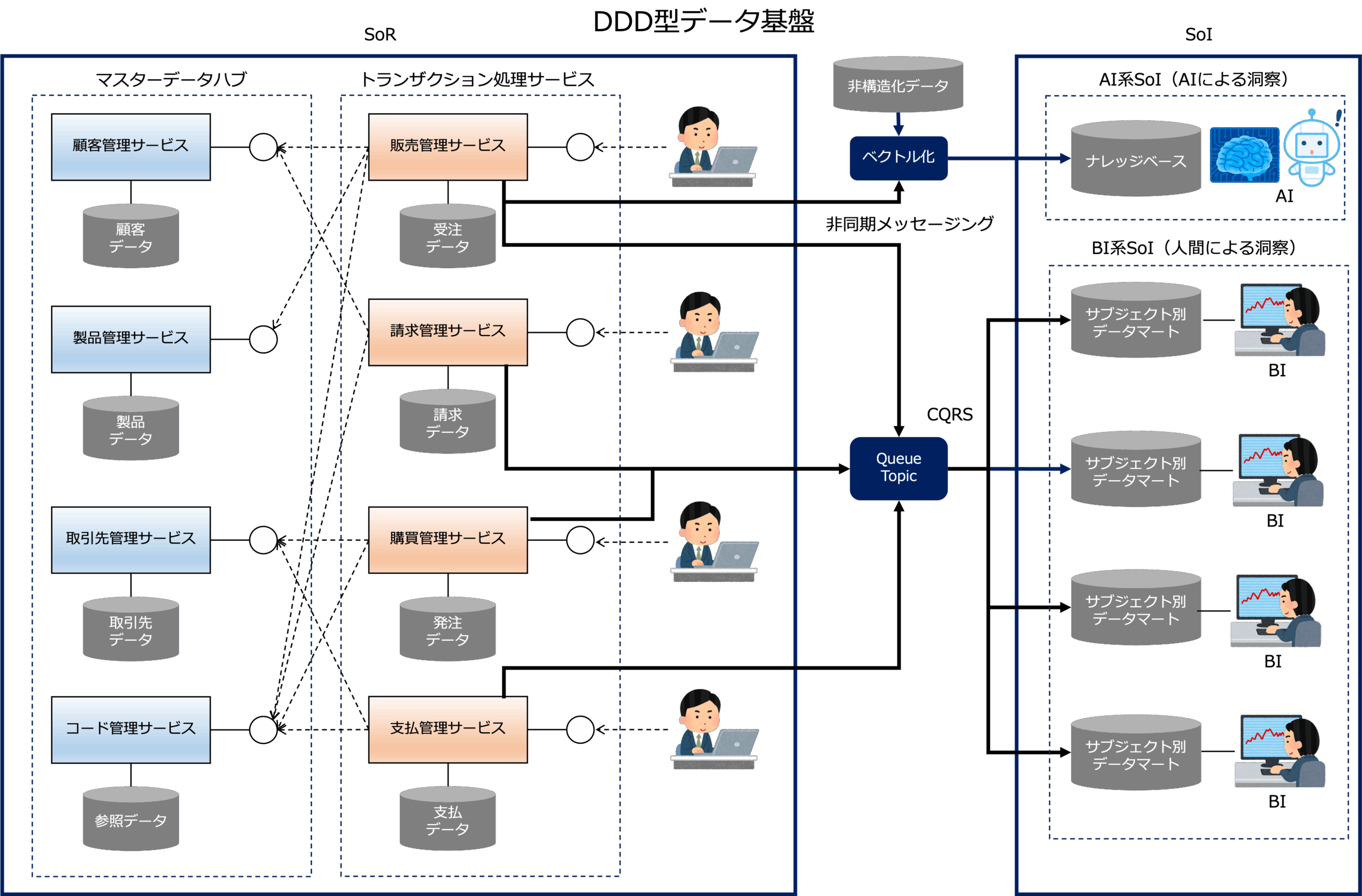
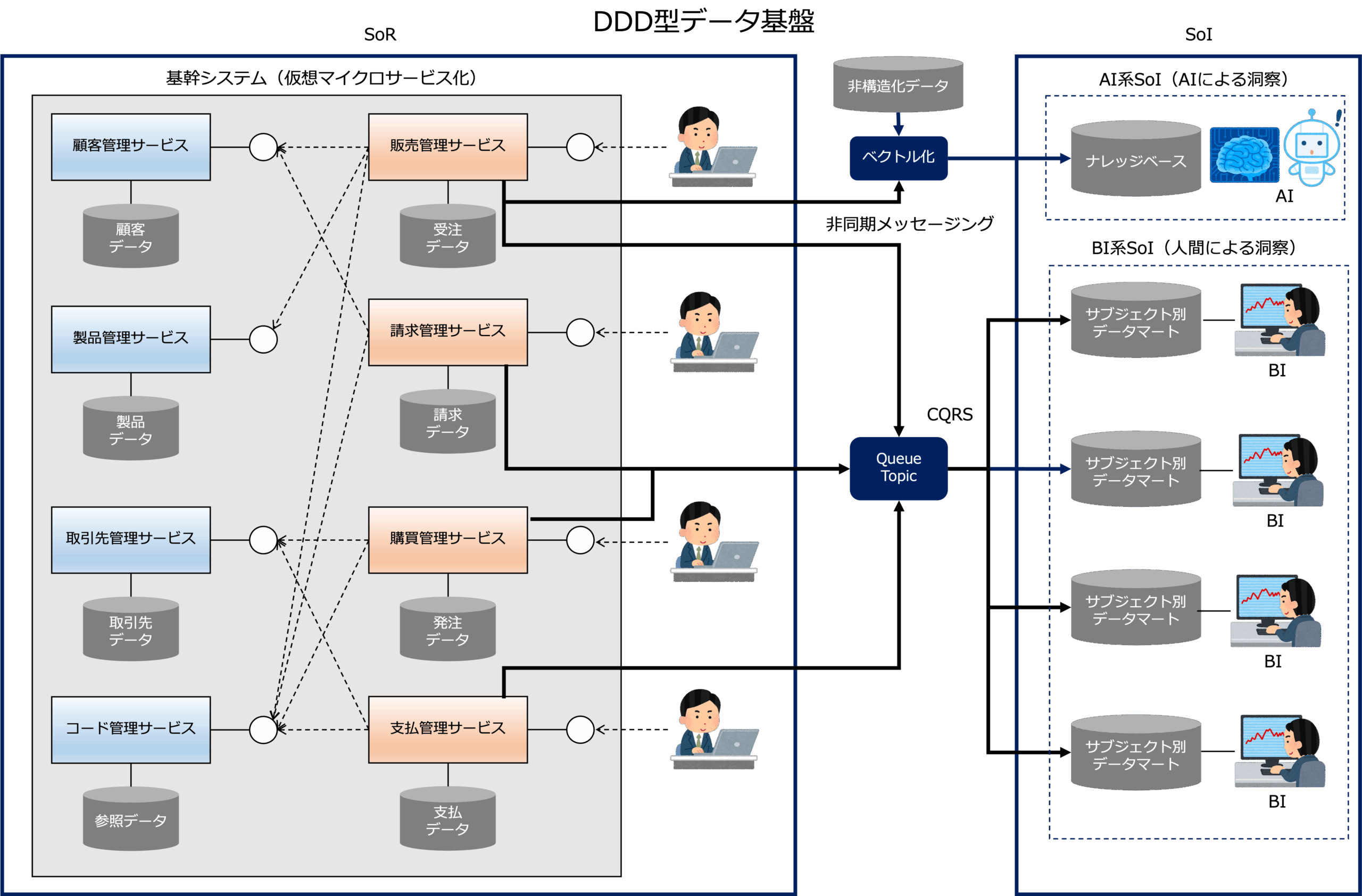
下図は、DDD型データ基盤のイメージです。
DDD型データ基盤の場合、記録システム(SoR)が、マスターデータを管理するマイクロサービスから構成されるマスターデータハブと、トランザクション処理アプリケーションから構成されています。
トランザクション処理アプリケーションは、マイクロサービスと業務パッケージから構成されます。
それから、DDD型データ基盤の場合、SoIもマイクロサービスを使って構築します。
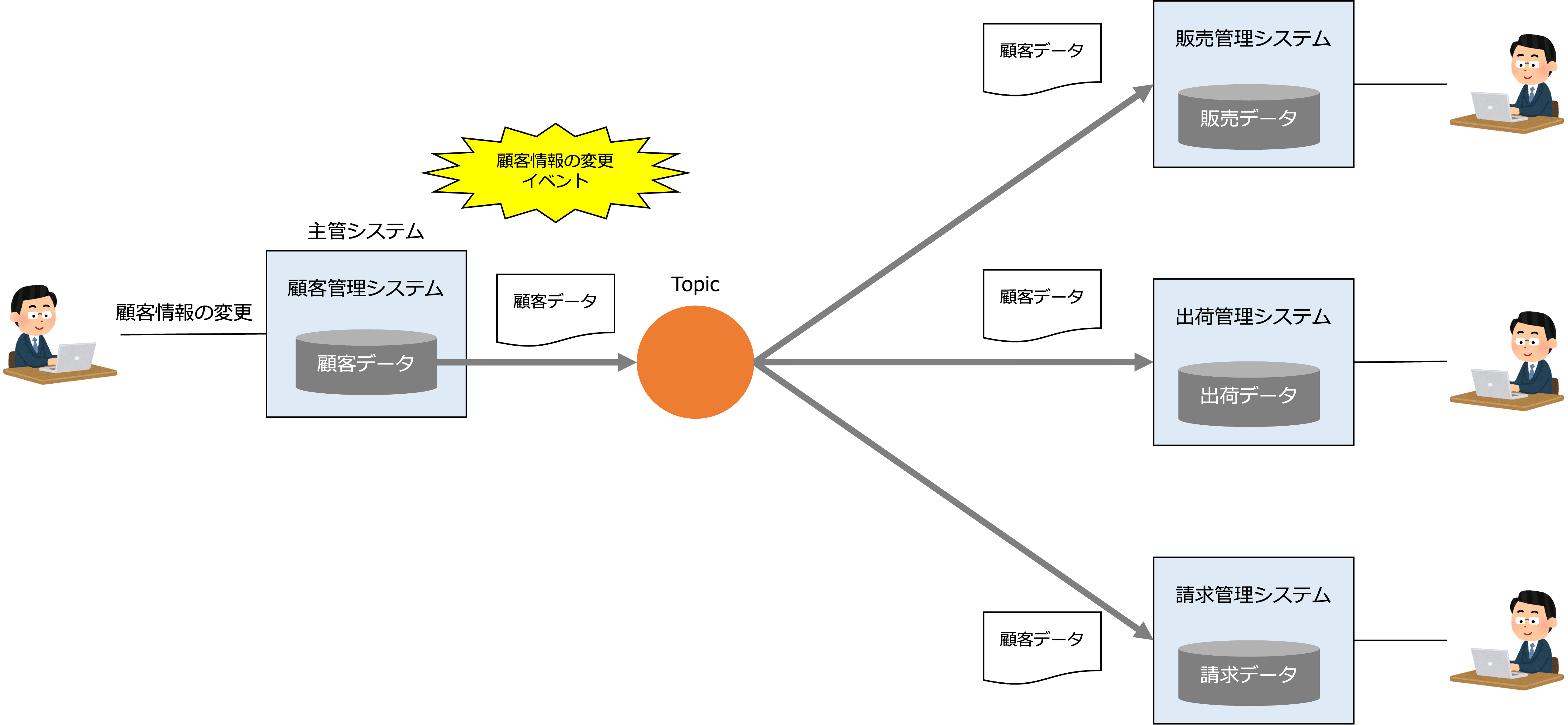
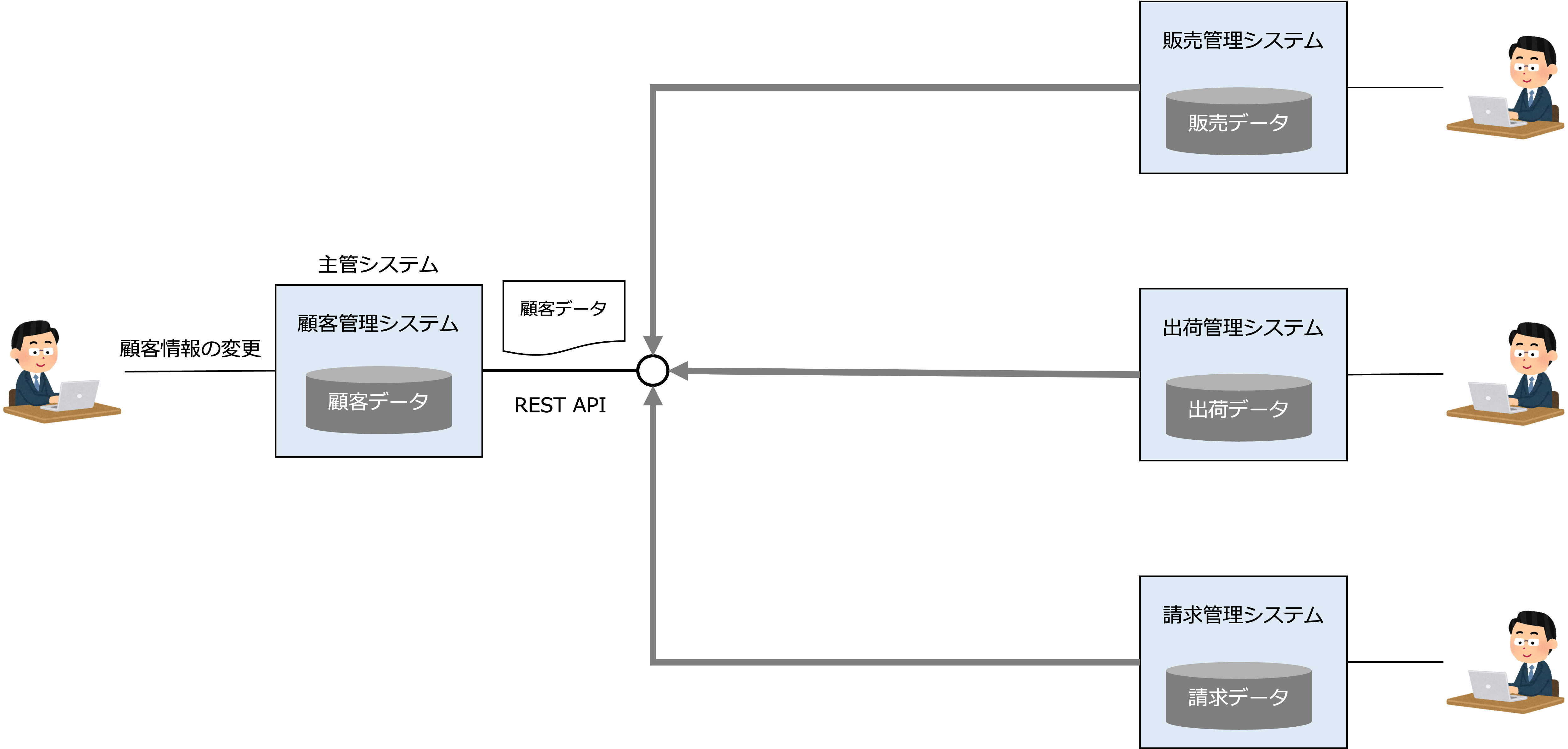
さて、DOA型データ基盤の場合、通常、ファイル転送によって一括でSoRのデータを中央で管理されるデータストアに格納します。
一方、DDD型データ基盤の場合、SoRのデータが更新される都度、非同期メッセージングによってSoRののデータがサブジェクト別データマートに送信され、更新系データと参照系データの同期を取ります。
このデータ連携モデルは、コマンドクエリ分離パターンというアーキテクチャパターンで、DDD型データ基盤の大きな特徴です。
DDD型データ基盤のメリット
DDD型データ基盤の最大のメリットは、
- DDDによって業務の仕組にしたがって業務ドメインが設計されていること
- 業務ドメインごとにマイクロサービスを構築し、そこに処理とデータがカプセル化されており、それらが疎結合することでシステム全体を構成すること
によって、ビジネスとシステムが連動し、企業の業務とシステム変化に強い堅牢な構造にすることができることです。
例えば、処理の内容やデータ構造が変わった場合も、相手に対するI/Fを変えないことで相手に対する影響を防ぐことができます。
また、新しい処理やデータ構造に対応した新しいI/Fを設け相手に利用の機会とタイミングを任せることで変更による影響を抑えることができます。
つまり、マイクロサービスに処理とデータをカプセル化することで、機能やデータ構造の変更によるリスクを局所化することができるのです。
これは、ソフトウェア設計原則の一つ、「ソフトウェアは拡張に開かれ、修正に閉じられているべき」という開放/閉鎖の原則(Open/Closed Principle)に則った考え方です。
また、一つの業務ドメインに関する知識(処理やデータ構造)が一つのマイクロサービスに凝縮して閉じ込められていることで、業務の内容が変更されても、それに対応したマイクロサービスだけを変えればよく、業務の変更に対する耐性が高くなります。
逆に、ある業務に関係する処理やデータがあちこちに散在していると、それだけ業務内容の変更によるリスクとコストが高くなり、業務の変更に対する柔軟性が失われてしまいます。
これは、単一責任の原則(Single Responsibility Principle)というソフトウェア設計原則に則った考え方です。
DDD型データ基盤のデメリット
一方、DDD型データ基盤のデメリットは、分散型であるが故にコストが高いことです。
個々のマイクロサービスの更新系データが更新される都度、サブジェクト別データマートの参照系データが更新されるというCQRSアーキテクチャは、定期的に一括で更新されるファイル転送に比べて、ネットワークコストが高くつきます。
ではなぜ、DDD型データ基盤は、非同期メッセージングによるイベントドリブンアーキテクチャを採用するのか、その理由は2つあります。
それは、
- データの適時性を確保すること
- 非同期通信によってノード間を疎結合にすること
です。
一つひとつ見ていきましょう。
データの適時性を確保すること
1日に1回、1時間に1回という定期的な一括ファイル転送の場合、次の2つの問題が発生します。
一つは、トランザクションを考慮して、あるタイミングから次のタイミングまでに蓄積されたデータを抽出するのが困難というデータ抽出の問題です。
もう一つは、レイテンシ(遅延)の問題です。
ソースシステムでデータが生成されてからターゲットシステムでデータが利用可能になるまでの時間差のことをレイテンシといいます。
データの品質を測る指標の一つのデータの適時性があり、レイテンシをどの程度許容できるか、つまり遅延許容度で測ることができます。
データの適時性が重視されない場合は、定期的な一括ファイル転送で問題ないですが、適時性が求められる業務の場合、定期的な一括ファイル転送がシステム全体のボトルネックになる可能性があります。
実際に、これまでの成功体験の延長で一括ファイル転送を採用したためレイテンシの問題が発生し、データの適時性という非機能要件が満たせないという事例をいくつか見たことがあります。
その点、非同期メッセージングは、非同期なのでAPI連携のように完全リアルタイムではないですがレイテンシが低く、遅延による問題はほぼ発生しません。
なお、非同期メッセージングの実装ですが、JMSのようなJavaのフレームワークなど、非同期メッセージングを実現する各種フレームワークが充実しているので技術的はハードルも高くありません。
非同期通信によってノード間を疎結合にすること
非同期メッセージングによるイベントドリブンアーキテクチャは、イベントドリブンで、ノードからノードへメッセージをQueueやTopicを介して送信します。
その際、送信側は、メッセージを通知するだけで、受信側の処理もレスポンスも待ちません。
これが非同期通信です。
API連携のような同期通信の場合、もし、送信側に不具合が生じた場合、受信側の処理が続行できなくなりますが、非同期通信の場合、そのようなことはありません。
それは、QueueやTopicを管理するメッセージングサーバーが、相手が受信可能な状況のときメッセージを通知してくれるからです。
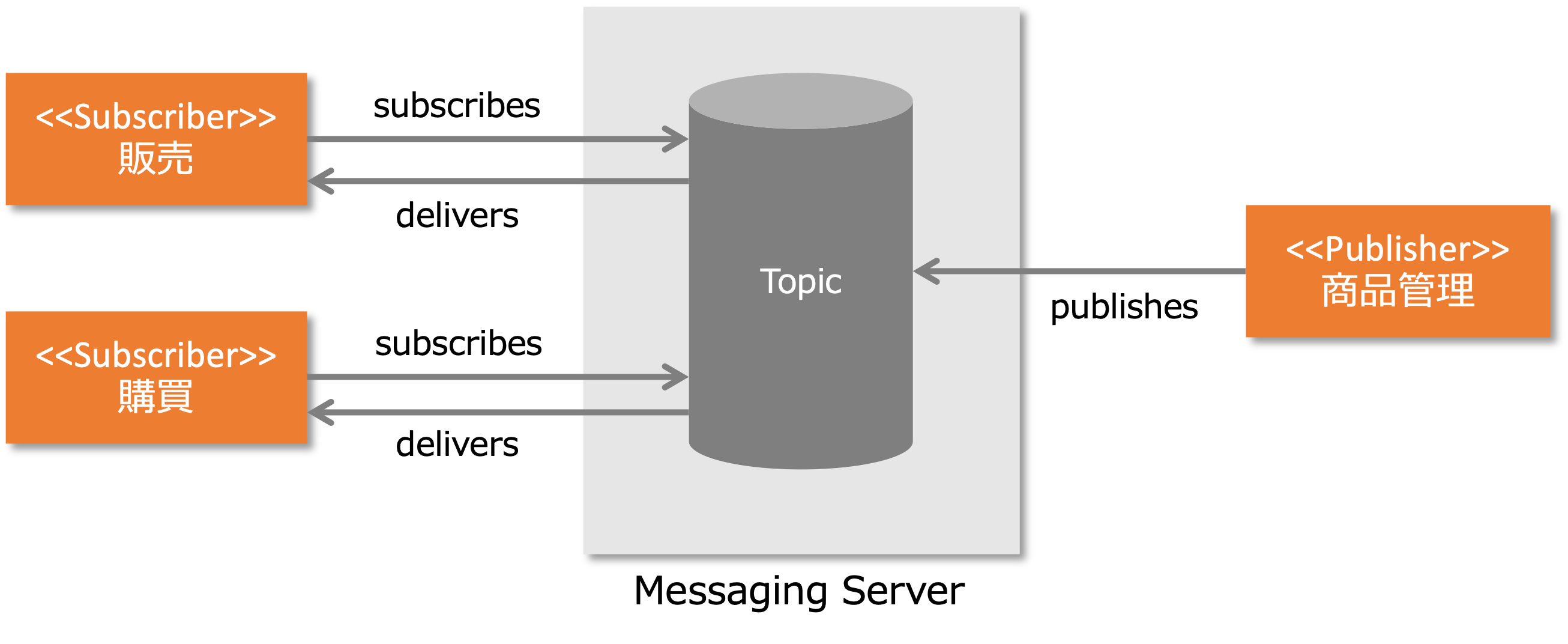
この仕組によって、非同期メッセージングによるイベントドリブンは、相手に対する依存度が低く、ネットワークを疎結合にします。
特に、マイクロサービスのように、ノード同士が独立している場合、相手に依存せず疎結合するというのは重要なポイントです。
以上のように、DDD型データ基盤の場合、ネットワークコストが高くなりますが、構築コストも高くなります。
DDD型データ基盤を構築する場合、SoRを業務ドメインごとに分けて、マイクロサービス化します。
その際、各マイクロサービスで管理するデータの品質やセキュリティを担保できるように再設計します。
つまり、それまで、ツギハギだらけで汚くなってきた機能とデータを、もう一度、クリーンアップするわけです。
なので、既存のSoRをそのまま利用するDOA型データ基盤に比べて、SoRの再構築が必要な分、コストがかかります。
DDD型データ基盤の構築方法
以上のように、既に基幹システムを構築している企業にとって、DDD型データ基盤を構築するためには、基幹システムを見直すためのコストがかかります。
しかし、
- これから基幹システムを構築する企業
- 基幹システムを再構築してモダナイズしようと考えている企業
の場合、DDD型データ基盤を構築する機会になります。
経済産業省のDX推進システムガイドラインでは、レガシー刷新後のシステムについて次のように言及しています。
《レガシー刷新後のシステム:変化への追従力》
レガシー刷新後のシステムには、新たなデジタル技術が導入され、ビジネス・モデルの変化に迅速に追従できるようになっているか。
(失敗ケース)刷新後のシステムは継続してスピーディーに機能追加できるものとするとの明確な目的設定をせずに、レガシー刷新自体が自己目的化すると、DXにつながらないシステムになってしまう(再レガシー化)
(先行事例)ビジネス上頻繁に更新することが求められるものについては、マイクロサービス化によって細分化しながらアジャイル開発により刷新していくアプローチもある。これにより、リスクが軽減される可能性もある。
これから基幹システムを構築する企業がDDD型データ基盤を構築する場合、記事モデルドリブン開発を参考にしてください。
また、基幹システムを再構築してモダナイズしようと考えている企業の場合、基幹システムを一度にマイクロサービス化するのではなく、段階的にマイクロサービス化する方法としてストラングラーアプリケーションパターンがあるので参考にしてください。
最後に、基幹システムを物理的に置き換えるのは厳しいと考える企業には、仮想MS化をお勧めします。
これは、論理的に業務ドメインで機能とデータを分割して、それぞれ、最適なAPIを設計、構築するという方法です。
DDD型データ基盤の将来(自律分散型データ基盤)
DDD型データ基盤は、業務ドメインごとにマイクロサービスを構築し、それらが疎結合することでシステム全体を構成します。
この構造は、従来のDOA型データ基盤(中央集権型のDWHを中心とする構成)と比較して、サービスごとの独立性や拡張性が高く、各サービス単位で段階的にAIエージェントを導入しやすいという特長があります。
具体的には、Anthropic社が提供する 大規模言語モデル(LLM)/AIアプリケーションと、外部データ・ツールとの接続を標準化するプロトコル、MCP(Model Context Protocol)を適用する例を考えることができます。
下図では、マイクロサービスのアダプタに、MCPでAIエージェントを接続しています。
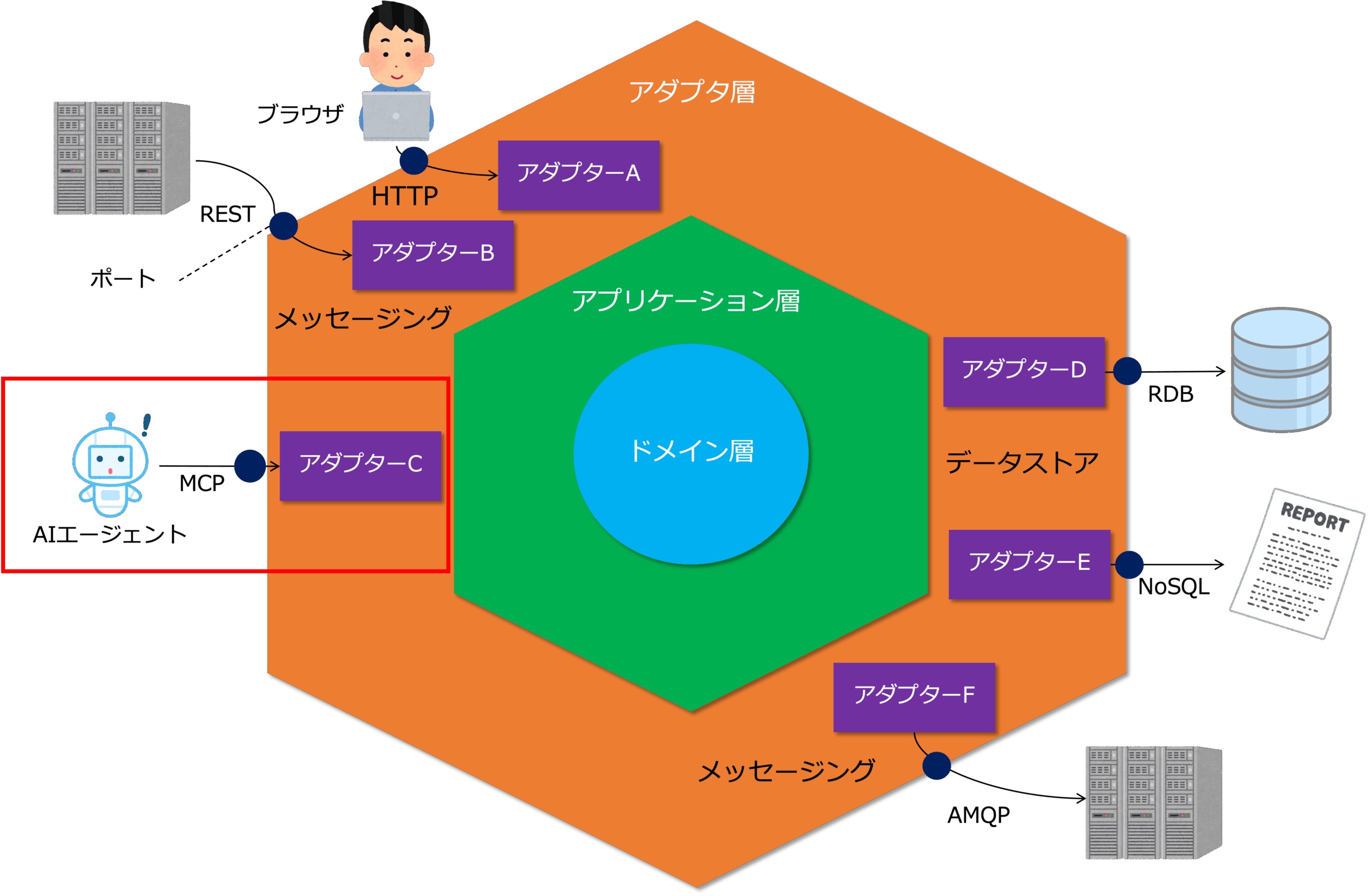
DDD型データ基盤では、アダプタ層が疎結合インターフェースとして機能しているため、AIエージェントの追加が容易です。
そして将来的には、すべてのマイクロサービスにAIエージェントを組み込むことで、それぞれのサービスが環境の変化をリアルタイムに察知し、自律的に会話・連携しながら、全体を最適化する、まるで生物のホメオスタシス(恒常性)のような仕組みを持つシステムを実現することが可能になります。
これを自律分散型データ基盤(Decentralized Autonomous Data Platform)と呼びます。
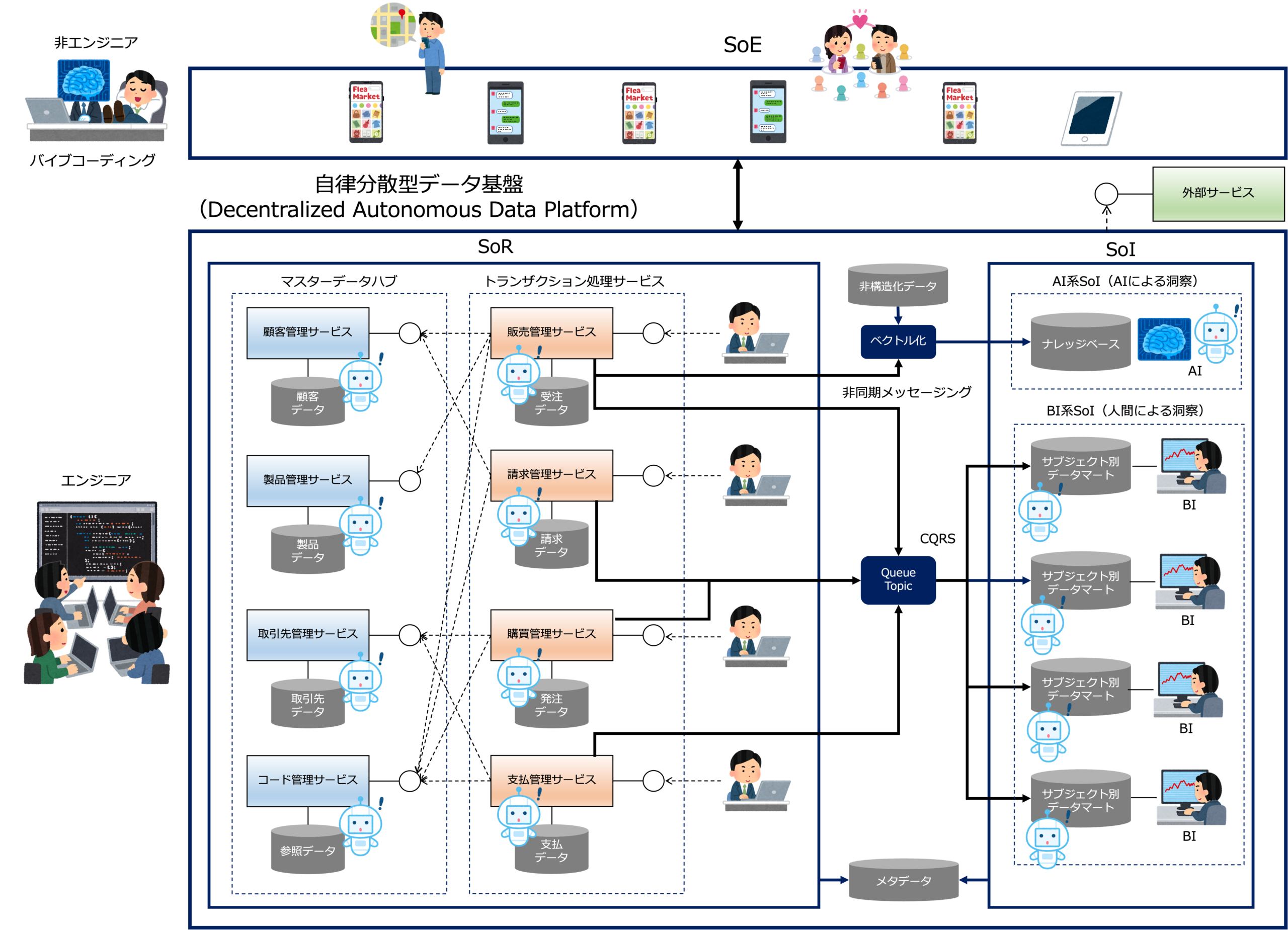
ちなみに、自律分散型データ基盤は、SoRとSoIによって構成されていますが、SoEはというと、自律分散型データ基盤にある安全で高品質なデータを活用して、業務にくわしい非エンジニアが開発します。
非エンジニアが自由にアプリをつくれるように、専門家としてのエンジニアがしっかりとしたデータ基盤を構築するのです。
AIエージェントをDDD型データ基盤に組み込むことで、次のような例を考えることができます。
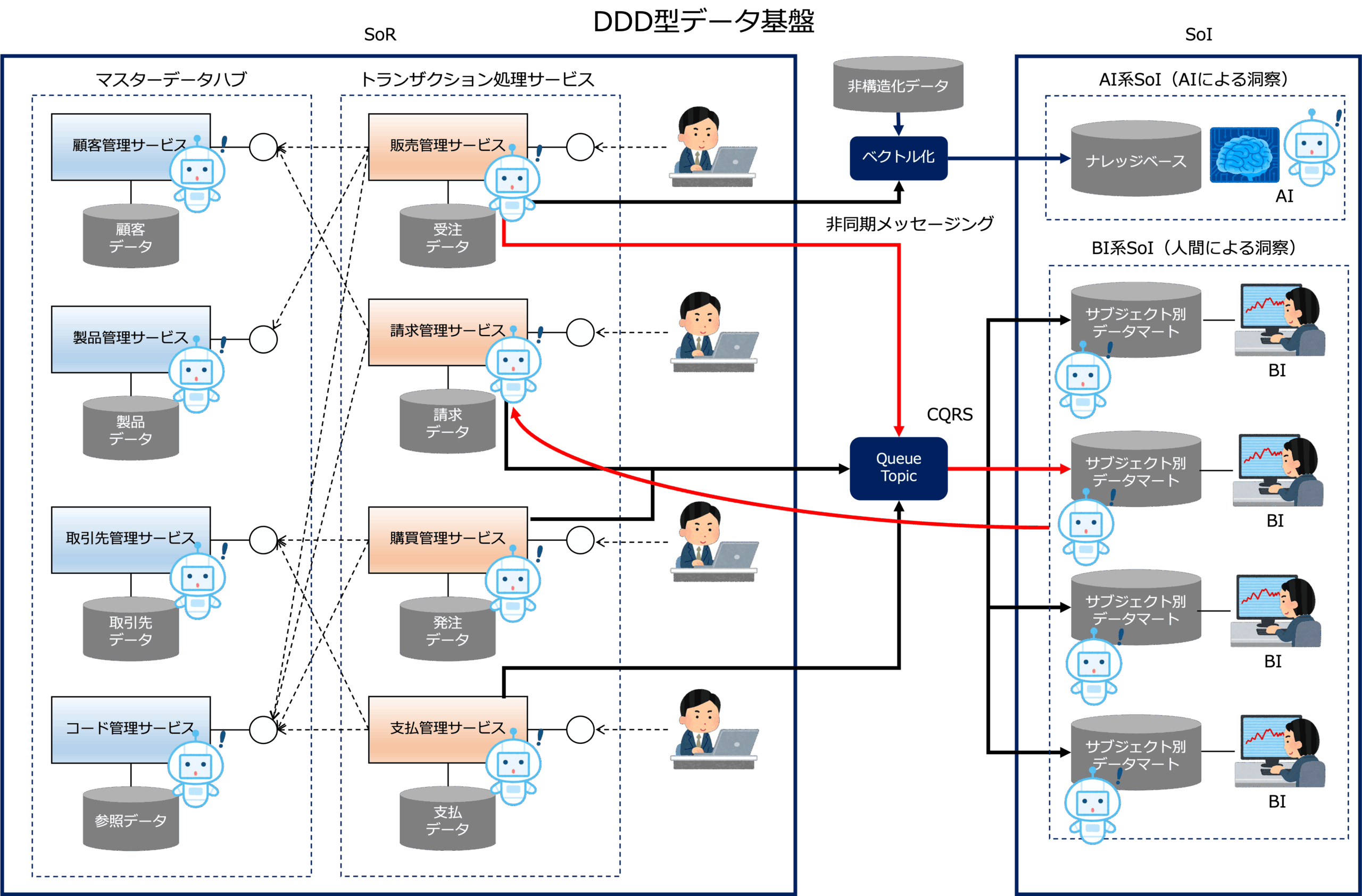
- 販売管理サービスが受注に対する出荷が行われたことを察知
- 販売管理サービスが出荷イベントを受けて、受注データを売上管理サービスに送信(非同期メッセージング)
- 売上管理サービスは、受注に対する売上データを作成
- 売上管理サービスは、非同期メッセージングで、売上管理エージェントに売上推移を分析するように依頼
- 売上管理エージェントは売上管理サービスを使って売上推移を分析し、売上低下を察知
- 売上管理エージェントは、購買管理エージェントに、購買の調整を依頼
- 購買管理エージェントは、購買管理サービスに1回で購入する購買量の調整を指示
また、次の図は、ある産業機械メーカーで、DDD型データ基盤にAIエージェントを組み込んだイメージです。
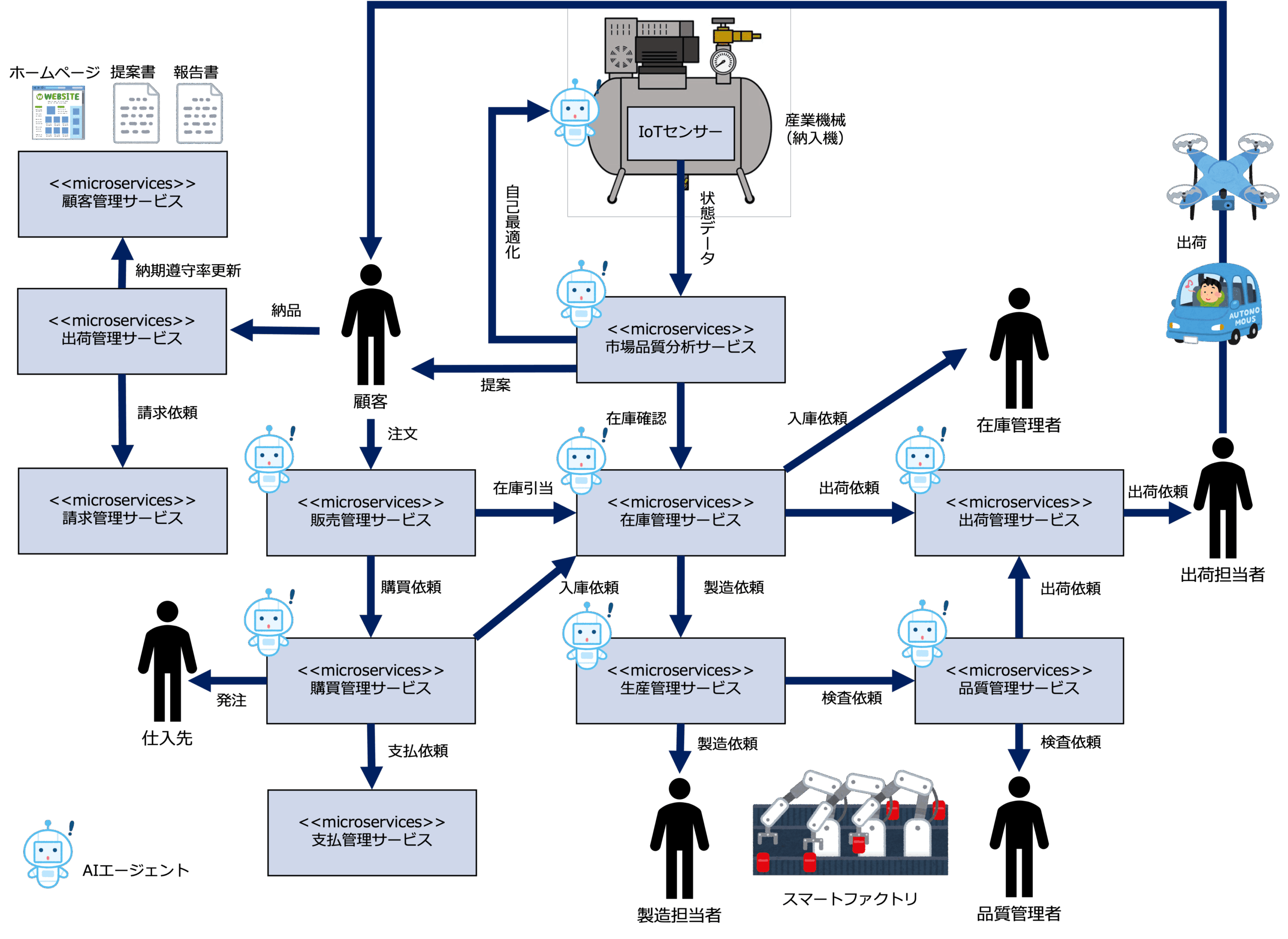
このモデルは、各マイクロサービスにAIエージェントが組み込まれているAIエージェントを前提とした(AIネイティブの)モデルで、次のようにオペレーションを自動化します。
- 市場品質分析サービスは、空気圧縮機の「稼働データ(温度・振動・圧力など)」と「状態情報」を受取り、その内容を解析し、故障兆候・異常がある場合、顧客にその旨を通知して保守サービスを促します。
- 市場品質分析サービスは、IoTセンサーなどから取得した空気圧縮機の稼働データ(温度、振動、電力、負荷、使用頻度など)をAIで分析し、製品(空気圧縮機)自体が動作を最適に調整するようフィードバックします(空気圧縮機の自己最適化)。
例- IoTセンサー → 市場品質分析サービス
圧縮機の状態(温度・圧力・稼働率・電力など)を常時送信 - 市場品質分析サービス(AI)
受信したデータをもとに、異常兆候を検知(予知保全)
個別環境における最適運転条件をリアルタイムで推定
同一型番でも、顧客の使い方に応じて個別最適化された制御ロジックを算出 - 圧縮機へのフィードバック(自己最適化)
AIが算出した最適化パラメータを圧縮機へ送信(例:クラウド経由またはエッジ経由)
圧縮機が以下を自律的に調整
モーター回転数(インバータ制御)
負荷制御アルゴリズム(ON/OFF間隔のチューニング)
熱効率のための冷却タイミング
自動スリープ・ウェイク機能の最適タイミング
エネルギー効率と寿命のバランス取り(たとえばピーク時は寿命より効率優先)
- IoTセンサー → 市場品質分析サービス
- 顧客からの製品の発注を受けた販売管理サービスは、在庫管理サービスに部品の引当を依頼し、在庫がない場合、購買管理サービスに部品の購買を依頼します。
- 部品が入荷されたら購買管理サービスは、在庫管理サービスに部品の入庫依頼をし、支払管理サービスに代金の支払を依頼します。
- 部品が入庫されたら、在庫管理サービスは、生産管理サービスに製品の製造依頼します。
- 工場は、スマートファクトリ化されており、製品の製造工程はすべてロボットが自動的に実行します。
- 製品ができたら生産管理サービスは、品質管理サービスに製品の検査依頼をします。
- 製品の検査依頼を受けた品質管理サービスは、品質管理者に製品の品質検査を促します。
- 製品の品質検査が終了すると、品質管理サービスは、出荷管理サービスに製品の出荷を依頼します。
- 出荷依頼を受けた出荷管理サービスは、出荷担当者に製品の出荷を依頼します。
- 出荷担当者は、ドローンや自動運転車で製品を出荷します。
- 顧客に製品が納品されると、顧客は出荷管理サービスに製品を受け取ったことを通知します。
- 出荷管理サービスは、それを受けて、請求管理サービスに代金の請求を依頼するとともに、顧客管理サービスに、戦略目標「製品/部品の安定供給」のKPI「製品納期遵守率」の更新を促します。
- 顧客管理サービスの「納期遵守率」はリアルタイムでホームページ上に表示されます。
次の図は、戦略マップを簡略化したものです。
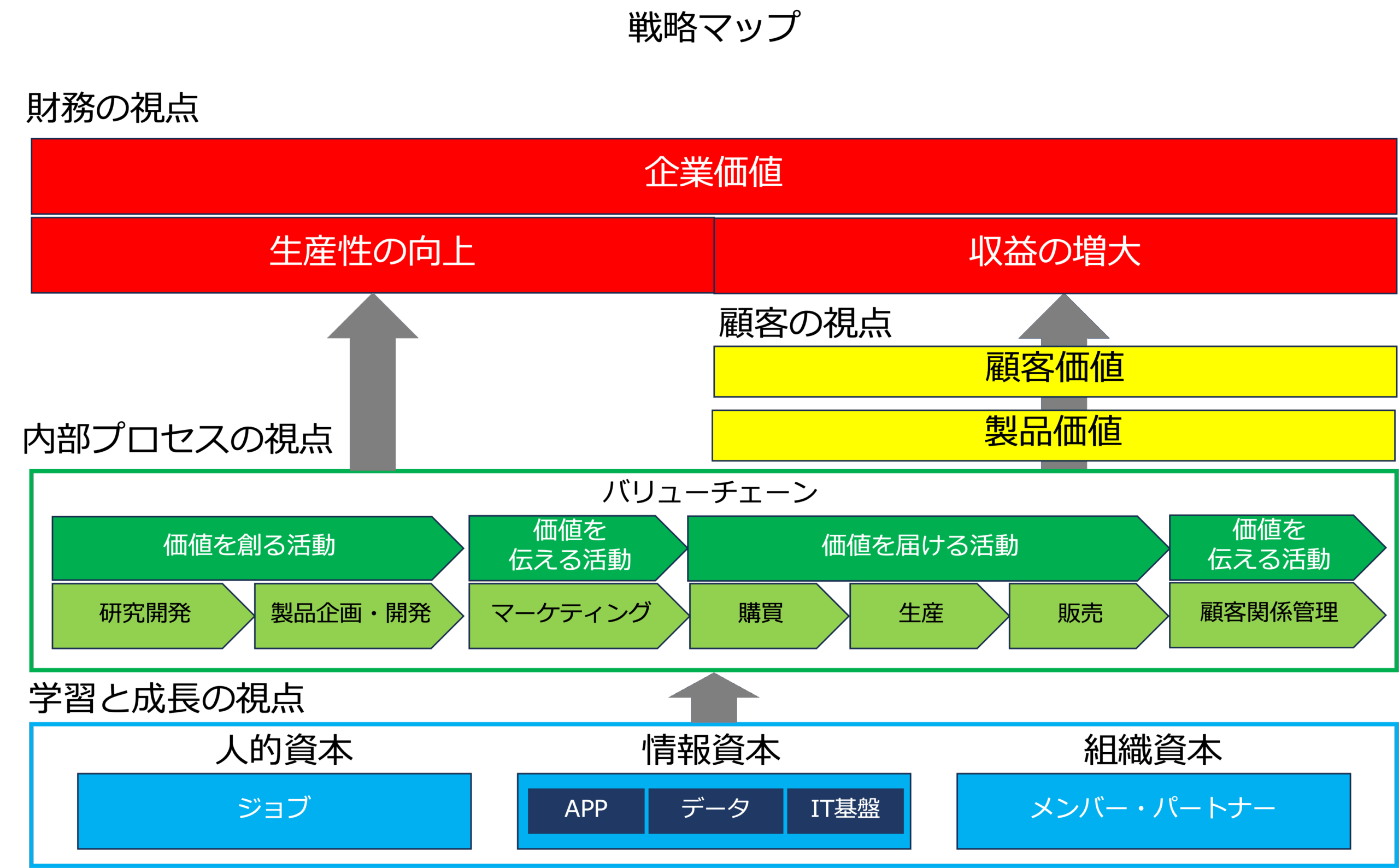
本図は、学習と成長の視点における人的資本・情報資本・組織資本といった無形資産が、内部プロセスの視点である価値創出活動(バリューチェーン)を実行することにより、顧客価値を提供し、収益の拡大や生産性の向上を通じて企業価値を最大化する因果関係を示しています。そして、企業価値は再び無形資産への投資として還元され、学習と成長が促進されることで、さらなる価値創出へとつながります。
内部プロセスと財務の関係をみると、価値を届ける活動(Operation)の効率化は「生産性の向上」に直結し、一方で価値を創る活動(Creation)や価値を伝える活動(Communication)は製品価値や顧客価値の向上を通じて「収益の増大」に結びつきます。
さて、価値を創る活動(Creation)、価値を届ける活動(Operation)、価値を伝える活動(Communication)と付加価値の関係を図にすると次のようなスマイルカーブになります。
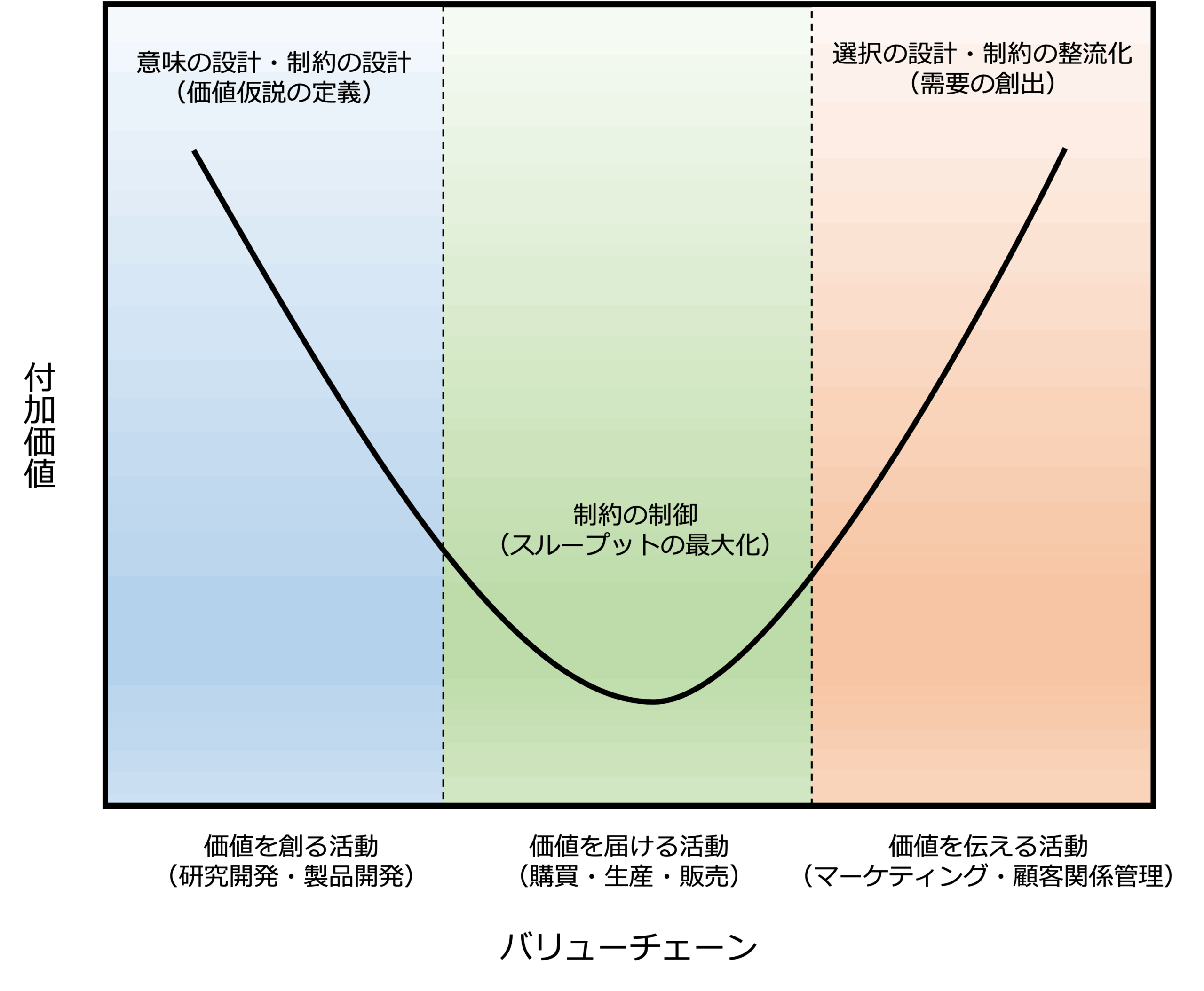
購買・生産・販売といった価値を届ける活動(Operation)に比べて、研究開発や製品開発といった価値を創る活動(Creation)や、マーケティングや顧客関係管理といった価値を伝える活動(Communication)は、相対的に高い付加価値を生み出すと考えられます。
上述したように、価値を届ける活動(Operation)は、AIエージェント前提でビジネスプロセスを再構築(BPR:Business Process Re-engineering)し、極限まで自動化すること(AIエージェントドリブンBPR)が可能です。
これにより、限られた人的リソースを価値を創る活動(Creation)や価値を伝える活動(Communication)といった高付加価値領域に再配分することで、組織全体の競争優位性を高めることができます。
さて、上述したように、DOA型データ基盤は、既存の基幹システムのデータを中央に集めてつくるため、比較的低コストで構築することができます。
しかし、その背後には、これまでツギハギして改修してきた基幹システム(SoR)のデータがダーティでも、中央でクレンジングして利用すれば問題ないという考え方があります。
記録システム(SoR)である基幹システムのデータは、業務で発生した事実(データ)の源泉です。
その大元のデータの品質が悪いという問題を横においたまま、とりあえずデータ基盤を構築するという場当たり的な対応は、データ品質に関する潜在的リスクの解消にはつながらず、むしろ将来的に業務の信頼性や意思決定の正確性を損なう危険性すら孕(はら)んでいます。
したがって、データ基盤の構築と並行して、SoR自体のデータ品質向上(例:入力ルールの見直し、業務プロセスの整備、マスタ整合性の確保)に継続的に取り組むことが不可欠です。
このような状況を踏まえると、DOA型データ基盤をすでに構築している企業であっても、業務とデータの構造を一致させ、SoRの段階から高品質なデータを生成できるよう設計されたDDD(ドメイン駆動設計)型データ基盤へと再構築することは、将来にわたるデータ活用の信頼性と柔軟性を高めるうえで、十分に合理的な判断といえるでしょう。
- ビジネス環境の変化が激しく、先行き不透明で予測困難な時代
- 来たるべきAIエージェンドリブンの世界
を考えると、DDD型データ基盤を構築することはDXの重要な課題だと考えることができます。



[…] DOA型(集中型)データ基盤からDDD型(分散型)データ基盤へ […]
[…] 会社のデータを中央のデータウェアハウスなどの管理基盤で一元的に集約・管理する集中型のデータ基盤ではなく、 データと、それを扱う業務機能をマイクロサービス単位でカプセル化し […]