![]()
ここでは、書籍「マイクロサービスアーキテクチャ」を参考にして、次の観点で、マイクロサービスについて整理します。
マイクロサービスアーキテクチャとは、ソフトウェアの開発とデプロイにおけるアプローチの一つで、システム全体を小さく独立したマイクロサービスに分割して構築する方法です。
マイクロサービスとは
マイクロサービスとは、2014年、マーチン・ファウラーとジェームス・ルイスが提唱した概念で、協調して動作する小規模で自律的なソフトウェア部品のことです。
書籍では、マイクロサービスの特徴を次の2つにまとめています。
- 小さく、かつ、一つの役割に専念
マイクロサービスは、単一責任の原則に従い「変更する理由が同じものは集める、変更する理由が違うものは分ける」ことでモジュールの凝集度を高く維持するようにします。
書籍では、マイクロサービスの規模を「2週間でコードが書き直せる」程度の大きさという例を出しています。 - 自律性
書籍では「マイクロサービスは、それぞれが独立に変更でき、相手のサービスを変更することなく単独でデプロイできなければならない」と説明されています。
つまり、マイクロサービスは、独自のOSプロセスであり、例えばPaaS(Platform as a Service)に単独でデプロイされる単位になります。
マイクロサービスは、互いの結合度を低く保つ必要があるのです。
このように、マイクロサービスの特徴は、凝集度が高く、互いの結合度が低いことです。
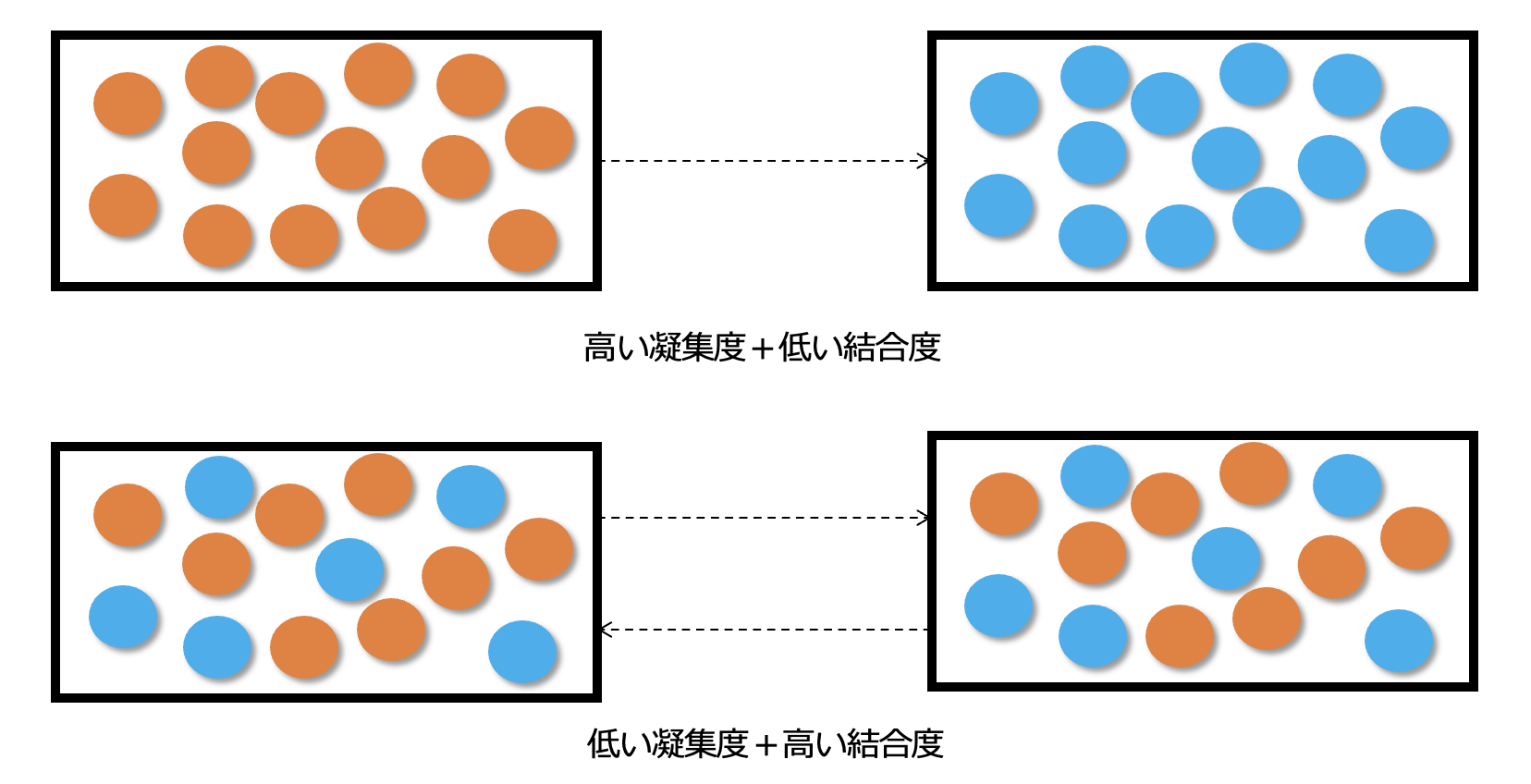
なので、一つひとつのマイクロサービスは、モジュール化されており、再利用性と交換可能性が高く、結果的に開発の生産性や保守性を高くします。
ここでは、マイクロサービスの特徴をもう少し細分化すると次のようになります。
- モジュール性
マイクロサービスには、それがモジュール化されており、再利用性と交換可能性が高いという特徴があります。 - 独立性
マイクロサービスには、各サービスを独立して展開、スケーリング、管理することができるという特徴があります。 - 分散性
マイクロサービスには、複数の小さなサービスにシステムを分割することで、分散システムを実現することができる特徴があります。 - デプロイの容易性
マイクロサービスには、それぞれが独立に変更でき、相手のサービスを変更することなく単独でデプロイすることができるという特徴があります。 - 障害耐性(フォールトトレランス)
マイクロサービスには、その独立性により、1つのサービスの障害が他のサービスに影響を与える可能性が低くなるという特徴があります。 - 技術異質性
マイクロサービスには、その独立性により、サービスごとに異なる技術(プログラム言語やデータベース)を採用することができるという特徴があります。
集中と分散
ネットワークの形態は、大きく、集中型と分散型に分けることができます。
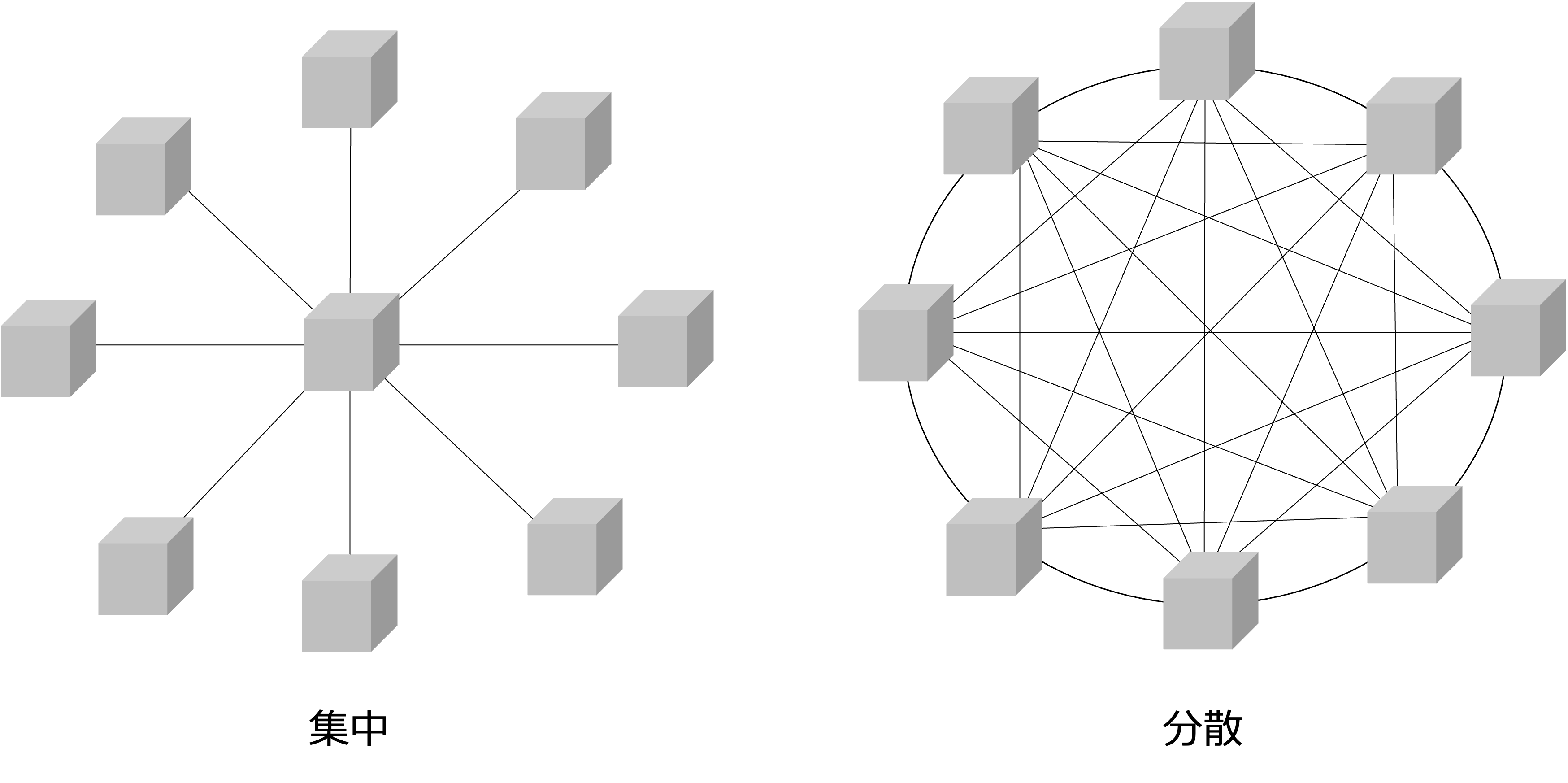
集中型は、ネットワークを構成する、あるノードを中心に他のノードが繋がっている形態で、分散型は、すべてのノードが相互に連携している形態です。
集中型の場合、中心となるノードに機能や負荷が集中するので、中心となるノードが単一障害点となり、それが機能しなくなるとネットワーク全体が機能しなくなる可能性が高くなりますが、中心となるノードだけを集中管理すればよいので管理コストやネットワークコスト(ネットワークの消費量)は比較的低くなります。
次に、分散型の場合、中心となるノードがなく、すべてのノードが相互に連携しているので機能や負荷が分散し、あるノードが機能しなくなるとネットワーク全体が機能しなくなる可能性は低いですが、すべてのノードと、それらの接続を管理する必要があるので管理コストやネットワークコストは比較的高くなります。

マイクロサービスは、分散型ネットワークを形成するので、ネットワークリスクは比較的低いですが、管理コストやネットワークコストは高くなります。
逆に、多くの業務パッケージのようにモノリシックな(機能が集中して一枚岩のような)システムは、集中型ネットワークを形成するので、管理コストやネットワークコストは比較的低いですが、ネットワークリスクは高くなります。
なので、マイクロサービスアーキテクチャを採用するときは、いかに管理コストやネットワークコストを下げるかを考慮する必要があります。
マイクロサービスのメリット
マイクロサービスのメリットをまとめると次のようになります。
保守性・生産性の向上
マイクロサービスを適用することで、それが持つモジュール性とデプロイの容易性という性質によってシステム全体の保守性と生産性を上げることができます。
- モジュール性
まず、マイクロサービスは、モジュール化されているので交換可能性と再利用性を上げ、結果的に、システム全体の保守性と生産性を上げることができます。
一方、業務パッケージのようなモノリシックなシステムの場合、複雑に絡み合った機能が一元的に管理されているので、カスタマイズの自由度が低く、変更に時間がかかってしまいます。 - デプロイの容易性
ビジネスのコアとなる機能は、経営環境の変化に迅速に適応する必要があるため、それをシステムで支援する場合、業務パッケージのようなモノリシックなシステムではなく、機能ごとにモジュール化されたマイクロサービスを適用するほうが得策だと思います。
拡張性の向上
マイクロサービスを適用することで、それが持つ分散性と独立性という性質によってシステム全体をスケールしやすくします。
- 分散性
マイクロサービスの場合、独立した機能に限定されているため、安価なサーバーをたくさんつなげて並列処理させる(スケールアウトする)ことでパフォーマンスを向上させることができます。
一方、業務パッケージのようなモノリシックなシステムの場合、並列処理のために複数のサーバへデータを分散させてしまうと、全体の整合性を確保するのが難しくなります。
なので、モノリシックなシステムの場合、サーバーの数を増やすのではなく、サーバをより高性能なものに換える、あるいはメモリやプロセッサを増設する(スケールアップする)ことでサーバの性能を高める手法を使うのが一般的です。
このように、マイクロサービスの場合、比較的安価にシステムを拡張することができます。 - 独立性
ビジネスのコアとなる機能をシステムで支援する場合、事業の成長にともなってスケールできなければならないため、業務パッケージのようなモノリシックなシステムではなく、機能ごとにモジュール化されたマイクロサービスを適用するほうが得策だと思います。
可用性の向上
マイクロサービスを適用することで、それが持つ分散性と独立性、障害耐性という性質によってシステム全体の可用性を上げることができます。
- 分散性
マイクロサービスアーキテクチャは、複数の小さなサービスにシステムを分割することで、分散システムを実現します。
この分散性により、システム全体が単一の障害点に依存しないため、障害が発生した場合でも他のサービスが影響を受けにくくなります。 - 独立性
各マイクロサービスは独立して実行されるため、1つのサービスの障害が他のサービスに影響を与える可能性が低くなります。
サービス間の明確な境界が設定されているため、障害が発生しても影響が限定され、全体のシステムの機能が継続することが期待されます。 - 障害耐性
グレースフルデグレード(Graceful Degradation)は、システムが負荷や障害に対して柔軟に対応し、一部の機能が低下したり失われたりしても、全体としてシステムがまだ機能し続ける能力を指します。
マイクロサービスは、個々のサービスが独立してスケーリングできるため、負荷が増加した場合でも、システムが完全に停止せずに、一部の機能が制限された状態で稼働を継続する(優雅に劣化する)ことができます。
つまり、一部のサービスが負荷に耐え切れなくなっても、システム全体が停止することなく、他のサービスは引き続き稼働し、ユーザーエクスペリエンスが損なわれることがありません。
業務パッケージのようなモノリシックなシステムの場合、 多くの機能がそこに集中しているので、単一障害点になりやすく、機能の複雑性により障害回復も困難であるため可用性リスクが高くなります。
ビジネスのコアとなる機能をシステムで支援する場合、システムに対する高い可用性が求められるので、業務パッケージのようなモノリシックなシステムではなく、機能ごとにモジュール化されたマイクロサービスを適用するほうが得策だと思います。
効率性の向上
マイクロサービスは、技術異質性によって、比較的安価にシステム全体の効率性を上げることができます。
例えば、コマンド・クエリ責務分離(CQRS)パターンを適用する場合、コマンド処理のサービスと、クエリ処理のサービスを分離することで、システム全体の効率性を上げることができます。
書籍では、マイクロサービスのメリットを次の7つの要素で説明しています。
技術異質性
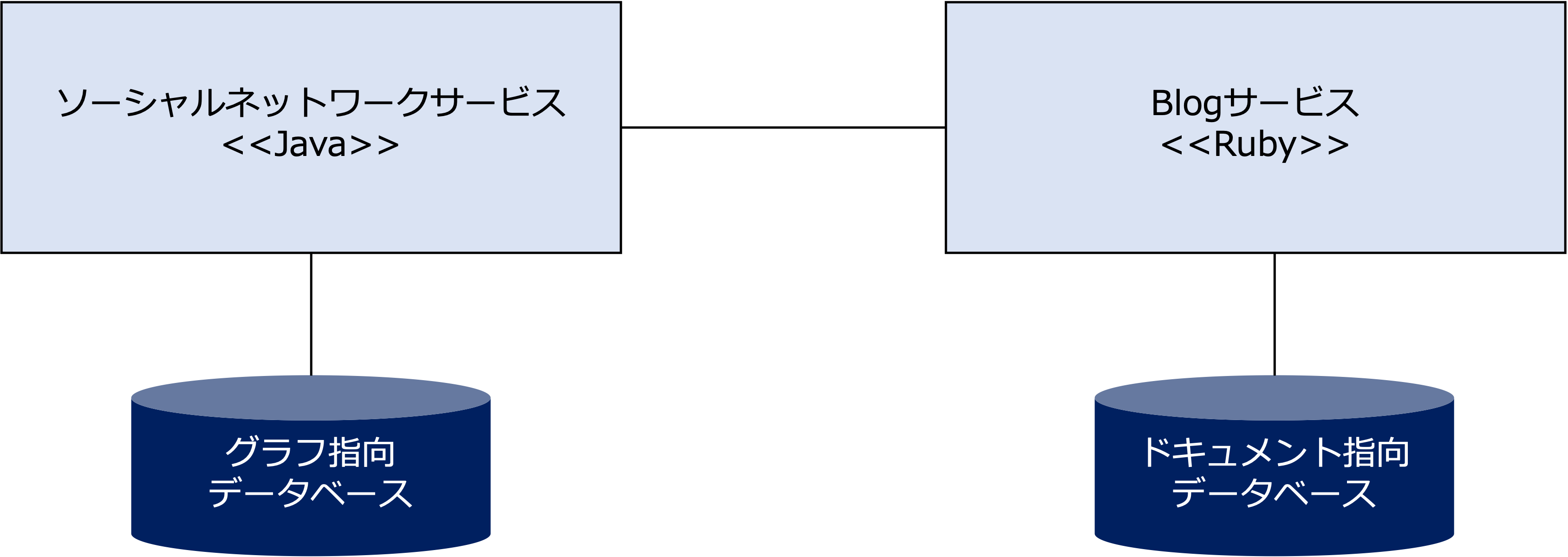
マイクロサービスは自律した機能単位なので、サービスごとに異なる技術(プログラム言語やデータベース)を採用することができます。
例えば、ソーシャルネットワークのようなサービスの場合、グラフ指向データベースを使い、ユーザーの文書を管理するサービスの場合、ドキュメント指向データベースを使うことができます。
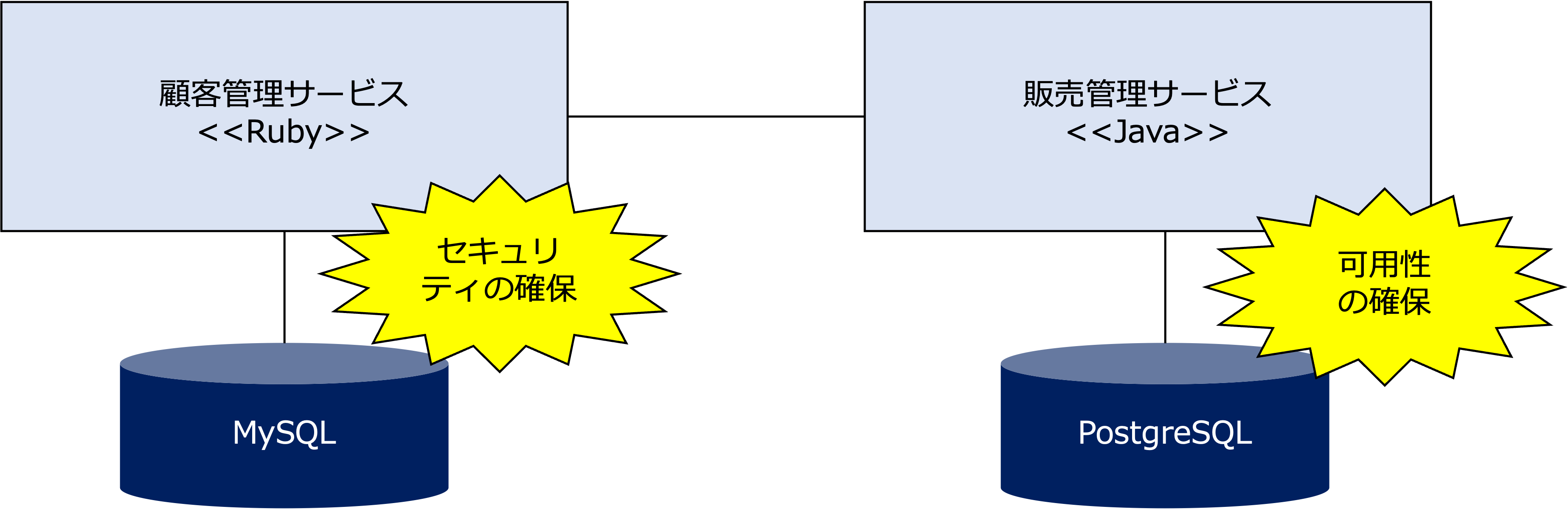
また、顧客管理のような機密性の高いデータを扱うサービスにはセキュリティを確保する技術を採用し、販売管理のような高い可用性を求められるサービスには、可用性を確保する技術を採用するなど、各サービスの特性に応じた技術を選択することができます。
回復性(レジリエンス)
マイクロサービスは、次のような理由でモノリシックなシステムに比べて回復性(レジリエンス)が高くなります。
- 分散システムの特性
マイクロサービスアーキテクチャは、複数の小さなサービスにシステムを分割することで、分散システムを実現します。
この分散性により、システム全体が単一の障害点に依存しないため、障害が発生した場合でも他のサービスが影響を受けにくくなります。 - 隔離性
各マイクロサービスは独立して実行されるため、1つのサービスの障害が他のサービスに影響を与える可能性が低くなります。
サービス間の明確な境界が設定されているため、障害が発生しても影響が限定され、全体のシステムの機能が継続することが期待されます。 - 自動化されたスケーリングとデプロイメント
マイクロサービスアーキテクチャでは、各サービスを個別にスケーリングやデプロイメントできるため、負荷や障害に応じて迅速に対応できます。
自動化されたスケーリングとデプロイメントにより、システム全体の回復性が向上します。 - フォールトトレランスの実装
マイクロサービスはフォールトトレランスを考慮して設計されることが一般的です。
各サービスが障害を検知し、障害が発生してもシステムが継続して適切に動作するようにリカバリーや再試行を行うことが期待されます。
マイクロサービスにフォールトトレランスを適用する具体例は次のようになります。
- サーキットブレーカー
サーキットブレーカーパターンは、外部サービスや依存関係が応答しない場合に、そのサービスへのリクエストを短期間中断することで、システム全体のパフォーマンスを維持する手法です。
一定の閾値を超えるエラー率が検出された場合にサーキットが開放され、リクエストがバックエンドサービスに到達するようになります。 - タイムアウト処理
リクエストが外部サービスや依存関係からの応答を受け取らない場合に、タイムアウト処理を実装してタイムアウトエラーを返すことがあります。
これにより、システムが外部リソースからの遅延によってブロックされることを防ぎ、リソースの効率的な利用が可能になります。 - ヘルスチェックと自己修復
マイクロサービスは、定期的なヘルスチェックを行い、自身の健全性を確認します。
もしサービスが異常を検知した場合、自己修復メカニズムを起動して、問題を解決しようと試みます。たとえば、一時的なエラーが発生した場合に、自動的にリトライするなどの処理が行われます。 - フォールバック(縮退運転)
外部サービスや依存関係からの応答が遅延したりエラーが発生したりした場合、フォールバックを提供することがあります。
フォールバックは、代替のデータやデフォルトの動作を提供し、システムが停止することなく適切に応答することができます。 - イベントドリブンアーキテクチャ
イベントドリブンアーキテクチャを使用して、イベント駆動による非同期メッセージングを実装することができます。
リアルタイムによる同期通信だと相手に対する依存度が高く密結合になるため、障害の影響が大きいですが、イベント駆動による非同期メッセージングだと、相手に対する依存度が低く疎結合になるので、障害の影響を抑えることができるので、相手に影響を与えず回復することができます。
サーキットブレーカーやタイムアウト処理は、外部サービスやネットワークが応答しない場合に、そのサービスへのリクエストを早期に中断することで、システム全体の浪費を防ぎシステム全体のパフォーマンスを維持することができるとともに、いち早く回復処理を進めることができるようにします。
フォールバックは、フェールソフト(Fail-Soft)の一種で、システムが予期せぬ状況やエラーに遭遇した場合に、代替の処理やデータを提供する仕組みです。
主な目的は、システムの可用性や信頼性を向上させ、ユーザーエクスペリエンスを損なうことなくサービスの提供を継続することです。
以下に、フォールバックの主な特徴と実装方法をいくつか挙げます。
- デフォルト値の使用
フォールバックの一般的な方法は、システムがエラーに遭遇した場合に代替のデフォルト値やデータを提供することです。たとえば、外部サービスからのレスポンスが遅延したりエラーが発生したりした場合、システムはデフォルトのキャッシュされたデータを使用してユーザーに応答します。 - 代替の処理経路
システムがエラーに遭遇した場合に、代替の処理経路を利用することができます。たとえば、外部サービスへのリクエストがタイムアウトした場合、システムは代替のサービスやデータソースに対してリクエストを送信し、適切なレスポンスを取得します。 - キャッシュの活用
システムは、フォールバックの一環として、キャッシュされたデータを活用することができます。外部サービスからのデータ取得に失敗した場合、システムは最後に取得したキャッシュされたデータを使用してユーザーに応答します。これにより、システムの可用性が向上し、ユーザーエクスペリエンスが維持されます。 - 通知やログの記録
フォールバックが起動された場合、システムは適切な通知やログを生成し、管理者や開発者にエラーの発生を通知します。これにより、問題の追跡や解決が迅速に行われることが保証されます。
スケーリング
スケーリングとは、システムやサービスのキャパシティ(処理能力)を拡張することです。
マイクロサービスがスケーリングの点で有利な理由は次のようになります。
- 独立性と分離性
マイクロサービスアーキテクチャでは、各サービスが独立して展開、スケーリング、管理されます。
この独立性により、特定の機能やコンポーネントのみを必要に応じてスケーリングすることができます。
例えば、特定のサービスがトラフィックの増加により負荷が増大した場合、そのサービスだけをスケールアウトすることで、システム全体のパフォーマンスを向上させることができます。
一方、モノリシックなシステムでは、ある機能のみ性能に問題がある場合でも、すべてを一緒にスケールさせる必要があるのでリスクもコストも高くなります。 - グレースフルデグレード
グレースフルデグレード(Graceful Degradation)は、システムが負荷や障害に対して柔軟に対応し、一部の機能が低下したり失われたりしても、全体としてシステムがまだ機能し続ける能力を指します。
マイクロサービスは、個々のサービスが独立してスケーリングできるため、負荷が増加した場合でも、システムが完全に停止せずに、一部の機能が制限された状態で稼働を継続する(優雅に劣化する)ことができます。
つまり、一部のサービスが負荷に耐え切れなくなっても、システム全体が停止することなく、他のサービスは引き続き稼働し、ユーザーエクスペリエンスが損なわれることがありません。 - 技術スタックの柔軟性
マイクロサービスアーキテクチャでは、各サービスが独自の技術スタックやプログラミング言語を使用することができます。これにより、最適な技術やツールを選択して、特定の要件やニーズに応じて各サービスをスケーリングすることができます。たとえば、データ処理が大量に発生するサービスには、高速な言語やフレームワークを選択することができます。 - 分散処理の活用
マイクロサービスアーキテクチャでは、複数のサービスが分散環境で動作します。これにより、処理を分散して並列処理を行うことができ、スケーラビリティを向上させることができます。
また、クラウドプロバイダーが提供するオートスケーリング機能(システムやアプリケーションの負荷に応じて自動的にリソースの拡張や縮小を行う機能)を活用して、負荷に応じて自動的にリソースを拡張することも可能です。
デプロイの容易性
マイクロサービスは、それぞれが独立に変更でき、相手のサービスを変更することなく単独でデプロイすることができます。
書籍では、マイクロサービスのデプロイの容易性について次のように説明しています。
百万行のモノリシックアプリケーションを1行変更すると、その変更をリリースするためにアプリケーション全体をデプロイしなくてはいけません。
このようなデプロイは、影響が大きくリスクが高くなる可能性があります。
実際には、影響が大きくリスクの高いデプロイは、当然ながら懸念があるために結局は頻繁に行われることはありません。
残念ながら、これは、変更がリリース間に積み上がり、本番環境にデプロイされるアプリケーションの新バージョンに多くの変更が含まれることになります。
リリース間の差分が大きいいほど、問題が起こるリスクが高くなります。
マイクロサービスでは、1つのサービスに変更を加えて、残りのシステムとは独立してデプロイできます。
そのため、コードを迅速にデプロイできます。
問題が生じた場合は、問題の原因である個別のサービスを迅速に特定でき、迅速なロールバックを簡単に実現します。
また、これは新機能を迅速に顧客に提供できることも意味しています。
これは、AmazonやNetflixといった組織が、このアーキテクチャを利用する主な理由の1つです。
日本では、ファーストリテイリング社(ユニクロ運営会社)が、2015年からECサイトのアプリケーションやスマートフォンアプリ「ユニクロ・アプリ」などにマイクロサービスを適用しはじめ、商品管理や在庫管理など従来パッケージ製品を適用していた基幹システムの領域までマイクロサービス化しているようです。
パッケージ製品は、カスタマイズの自由度が低く、変更に時間が掛かるため、基幹業務システムで、会社のコアのナレッジがたまっている部分は、パッケージを使うのではなく、今後は自分たちで作るべきだと判断したようです。
組織面の一致
ソフトウェア開発の法則の一つに、
組織のコミュニケーション構造は、組織内のシステムの設計に直接的に反映される
というコンウェイの法則があります。
これは、巨大なヒエラルキーを持つ垂直統合型組織であれば、その構造を反映したシステムアーキテクチャ(上位のモジュールが下位のモジュールに指示を出すなど)になりやすく、水平分散型組織であれば、その構造を反映したシステムアーキテクチャ(分散されたモジュール化によるマイクロサービスアーキテクチャのような形)になりやすいということです。
なので、システムの設計や開発プロセスを改善する際に、組織内のコミュニケーションや組織構造にも注意を払う必要があります。
これを逆に考えた場合、多くの基幹システムのようにモノリシックな(機能が集中して一枚岩のような)システムは、多くのメンバーが参画する大きな組織が対応するかたちになります。
大きな組織は、統制が難しく、意思決定のスピードが遅くなります。
さらに、機能ごとに分割された小規模な組織を組み合わせてモノリシックなシステムを開発、維持管理すると、オーバヘッドが積み重なり、さらに問題を大きくします。
マイクロサービスは、アーキテクチャを機能ごとに分割された小規模な組織に、よりよく一致させることができます。
小規模コードベースで作業する小規模チームの方が生産性が高い傾向にあることが知られています。
マイクロサービスでは、1つのコードベースで作業する人数を最小化し、チームの大きさと生産性を最適にます。
独立した小規模のチームにマイクロサービスの所有権を移転することで、そのチームを同じ場所(空間)に配置することができ、生産性を上げることができます。
合成可能性
モジュール化されたマイクロサービスは、再利用性が高くなります。
例えば、新しいシステムを開発するときは、顧客管理サービスなど既存のマイクロサービスを合成してつくることができます。
UIをPCからモバイルデバイスやウェアラブルデバイスに拡張する場合も、PCのマイクロサービスを再利用することができます。
このように、適切に機能分割されたマイクロサービスは合成可能性を高くします。
交換可能にするための最適化
モジュール化されたマイクロサービスは、APIを公開し、実装をカプセル化するので、交換可能性を高くします。
適切に機能分割されたマイクロサービスは、新しい技術で実装部分を置き換えて、サービス(機能単位)を進化させることができます。
モノリシックなシステムも、一部の機能を置き換ることができますが、全体をデプロイする必要があり、マイクロサービスのように機敏に対応することはできません。
マイクロサービスのデメリット
前述したように、マイクロサービスのデメリットは、その分散性により、管理コストやネットワークコストが高くなることです。
ここでは、マイクロサービスのデメリットである管理コストやネットワークコストの増大に対する解決策の例を次のようにまとめます。
- サービスサイズの最適化
単一責任の原則を守りつつサービスのサイズが細かくなりすぎないように設計します。 - 継続的デリバリ
継続的デリバリを適用したテストやデプロイの自動化は、分散した多数のマイクロサービスを管理するコストを低減します。
さらに、Dockerなど仮想コンテナ技術を適用して、開発環境、本番環境のイメージを作成し、イミュータブル(変更不可)な環境をアプリケーションから切り離して展開することで、環境構築のプロビジョニングコストが激減し、デプロイを効率化することができます。 - コンシューマ駆動契約(Consumer-Driven Contracts、CDC)
CDCは、マイクロサービスアーキテクチャにおいて、サービス間のインターフェースやデータ交換に関する契約を定義し、検証するための手法です。
CDCでは、コンシューマサービス(利用側)がプロバイダーサービスから期待するデータ構造や操作を定義し、プロバイダーサービス(利用される側)は、コンシューマの期待に基づいて自身のインターフェースを構築します。
そして、契約の変更やバージョンアップ時に自動的にテストを実行して、コンシューマとプロバイダーの間で互換性が維持されていることを確認します。
このように、CDCを適用することで、変更管理のコストを下げることができます。 - 非同期通信の活用
リアルタイムでないデータの処理には、非同期通信メカニズム(例:Apache Kafka、RabbitMQ)を活用します。
これにより、リクエストとレスポンスが直列に処理される必要がなくなり、システム全体のレスポンスタイムとスループットが改善されます。 - データのキャッシング
頻繁にアクセスされるデータや重要な計算結果をキャッシュすることで、同じリクエストに対して何度も同じ計算を行う必要がなくなります。
マイクロサービスの原則
最後にマイクロサービスアーキテクチャを適用するときの原則について説明します。
書籍では、マイクロサービスアーキテクチャを適用するときの原則を次のようにまとめています。
自動化の文化の採用
集中と分散の箇所で、マイクロサービスアーキテクチャを採用するときは、いかに管理コストやネットワークコストを下げるかを考慮する必要があると説明しました。
継続的デリバリを適用したテストやデプロイの自動化は、分散した多数のマイクロサービスを管理するコストを低減します。
さらに、Dockerなど仮想コンテナ技術を適用して、開発環境、本番環境のイメージを作成し、イミュータブル(変更不可)な環境をアプリケーションから切り離して展開することで、環境構築のプロビジョニングコストが激減し、デプロイを効率化することができます。
内部実装詳細の隠蔽
マイクロサービスを開発するときは、その自律性を担保するために、RESTなど技術非依存のAPIを相手に公開し、内部実装の詳細を隠蔽するようにします。
これによって、マイクロサービスがモジュール化され、再利用性と交換可能性を高くし、結果的に開発の生産性や保守性を高くします。
書籍では、マイクロサービスがデータベースを共有するのではなく、マイクロサービスごとにデータベースを持たせることを推奨しています。
マイクロサービスがデータベースを共有すると、複数のマイクロサービスが共通のデータベースに依存し、それだけマイクロサービスの自律性を下げることになります。
マイクロサービス間では、リアルタイムの同期通信やイベント駆動による非同期通信によってデータベースのデータを交換します。
REST(Representational State Transfer)を適用することで、JSONやXMLといった標準的な言語を使って、データベースのデータの状態をリソースとして再表現(representation)し、それを標準的なメソッド(POST、GET、PUT、DELETEなど)で操作する形で、マイクロサービス間を連携することができるので、マイクロサービス間を疎結合にし、結果的に、マイクロサービスの交換可能性や再利用性を高くすることができます。
さらに、HTTPメソッドのGET、PUT、DELETEは冪等性(idempotence)を持っているので、何度実行しても同じ結果が得られるため、安全で予測可能な操作が可能です。
冪等な操作は、同じリクエストを再送しても問題が生じないため、障害時の再試行が容易になり回復力を上げるとともに、テストとデバッグも容易になり保守性も上げます。
すべての分散化
書籍では、マイクロサービスに適した組織について次のように言及しています。
マイクロサービスが可能にする自律性を最大化するには、サービスを所有するチームに意思決定と制御を委譲する機会を常に追い求める必要があります。
これには、まず可能な限りセルフサービスを採用し、必要に応じてソフトウェアをデプロイできるようにし、開発とテストをできる限り容易にし、これらの作業を行うために別々のチームが必要ないようにします。
これは、マイクロサービスの単位で、開発と運用の連携を強化するDevOpsを実現することを意味しています。
独立したデプロイ
マイクロサービス単位の独立したデプロイは、ブルーグリーンデプロイメントやカナリアリリースを容易にします。
ブルーグリーンデプロイメントとは、ソフトウェアやアプリケーションの更新やリリースを行う際に、ダウンタイムを最小限に抑え、リスクを軽減するためのデプロイメント手法です。
ブルーグリーンデプロイメントの流れは次のようになります。
- 現在のプロダクション環境
既存のサービスは「ブルー」環境で稼働しています。 - 新しいリリースの準備
新しいコードや更新内容を「グリーン」環境にデプロイします。
これは、現在のプロダクション環境とは別に構築された環境です。 - テストと検証
グリーン環境で、新しいコードや機能の動作確認やテストを行います。 - 切り替え
テストが成功した場合、トラフィックをブルー環境からグリーン環境に切り替えます。
これにより、新しいリリースがプロダクション環境として動作します。 - フォールバック(オプション)
切り替えが成功した後、問題が発生した場合には、簡単にブルー環境に戻すことができます。
これは、デプロイメント中のリスクをさらに低減します。
カナリアリリース(Canary Release)とは、新しいコードを一度にすべてのユーザーに提供するのではなく、徐々に限定されたユーザーグループに展開し、問題がないことを確認してから全体に展開するデプロイメント手法です。
カナリアリリースの流れは次のようになります。
- 新しいリリースの準備
新しいコードや機能をプロダクション環境にデプロイします。
ただし、最初は一部のユーザーにのみ適用されるように設定します。 - 限定的なリリース
カナリアリリースでは、全ユーザーのうち特定の割合や特定のユーザーグループにのみ新しいリリースを提供します。
これは、ユーザーの行動やシステムの動作をモニタリングするためです。 - モニタリングと検証
限定的なユーザーグループからフィードバックを収集し、システムの安定性やパフォーマンスをモニタリングします。
この段階で問題が発生した場合、修正や調整が容易です。 - 段階的な展開
最初のカナリアグループで問題がないことを確認した後、徐々に他のユーザーグループに展開します。
リスクを最小限に抑えながら、システム全体へのリリースを進めます。
また、コンシューマ駆動契約(Consumer-Driven Contracts、以下、CDC)を適用することで、マイクロサービス単位の独立したデプロイを容易にします。
CDCは、マイクロサービスアーキテクチャにおいて、サービス間のインターフェースやデータ交換に関する契約を定義し、検証するための手法です。
CDCの主な特徴は次のようになります。
- コンシューマ主導
このアプローチでは、コンシューマサービス(利用する側のサービス)がプロバイダーサービス(利用される側のサービス)から期待するデータ構造や操作を定義します。
これにより、プロバイダーサービスは、コンシューマの期待に基づいて自身のインターフェースを構築することができます。 - 契約の自動テスト
CDCを使用すると、契約の変更やバージョンアップ時に自動的にテストを実行して、コンシューマとプロバイダーの間で互換性が維持されていることを確認できます。
これにより、デプロイや変更による不整合やバグを防ぐことができます。
PactやSpring Cloud Contractなどのツールを使うと、契約に基づいたテストケースの作成やテストを自動化することができます。
障害の分離
各マイクロサービスは独立して実行されるため、1つのサービスの障害が他のサービスに影響を与える可能性が低くなります。
サービス間の明確な境界が設定されているため、障害が発生しても影響が限定され、全体のシステムの機能が継続することが期待されます。
サーキットブレーカーやタイムアウトなどフォールトトレランスを考慮してマイクロサービスを設計することで、各サービスが障害を検知し、障害が発生してもシステムが継続して適切に動作するようすることで、障害に対する回復力を上げることができます。
高度な観測性
マイクロサービスアーキテクチャでは、複数のサービスが独立して展開されるため、個々のサービスのパフォーマンスや状態を監視し、全体的なシステムの健全性を確保することが重要です。
セマンティック監視を適用することにより、特定のサービスの障害が全体のシステムにどのような影響を与えるかを把握しやすくなります。
セマンティック監視(Semantic Monitoring)とは、個々のサービスの監視だけでなく、サービス間の依存関係や相互作用を理解し、システム全体の健全性やパフォーマンスに関する洞察を提供する手法です。
セマンティック監視を実現する手法には次のようなものがあります。
- 分散トレーシング
分散トレーシングは、マイクロサービスアーキテクチャでのリクエストの流れを追跡し、各サービスのパフォーマンスや相互作用を理解するための手法です。
各リクエストに一意のトレースIDを付与し、各サービスがこのIDを使用してトレース情報を共有することで、リクエストがどのようにサービス間を移動するかを追跡します。
これにより、サービス間の依存関係や相互作用を可視化し、システム全体のパフォーマンスや問題点を特定できます。 - 分散ログ集約
マイクロサービスアーキテクチャでは、各サービスが独自のログを生成します。
これらのログを中央の場所に集約し、統一された形式で保存および分析することで、システム全体の状態やパフォーマンスに関する洞察を得ることができます。
分散ログ集約システムを使用することで、サービス間の相互作用や問題点を特定しやすくなります。 - メトリクス監視
メトリクス監視は、各サービスのパフォーマンスや健全性を定期的に監視することで、システム全体の状態を把握する手法です。
メトリクス監視ツールを使用して、各サービスのリクエストレート、レイテンシ、エラーレートなどのメトリクスを収集し、監視ダッシュボードに表示することで、システム全体の健全性を把握できます。
なお、ログやメトリクスの内容や履歴は、オペレーショナルメタデータになります。
以上、見てきたように、全体をまとめると、モノリシックなシステムは、全体を一度に変化させる必要があるので対応が遅く、マイクロサービスはは個々のサービスが自律できるので、より俊敏(アジャイル)に環境の変化に適応できるということです。
最近、自社の基幹システムであるコア業務(SCM、PLM、CRM)に、業務パッケージを適用している事例が多く見受けられます。
しかも、カスタマイズによるコストを低減するために、できるだけ自社の業務を業務パッケージに合わせようとする風潮が高いようです。
安易にモノリシックな業務パッケージを適用すると、それに束縛され、雁字搦めになり環境の変化にアジャイルに適応する能力を失う可能性があります。
よく、業務パッケージを適用すると自動的に内部統制に対応できるからリスクを下げるという話を聞きます。
しかし、自動的に内部統制に対応できるということは、内部統制について思考停止になることでもあります。
スクラッチ開発の場合、内部統制を働かせるためにはどうすればよいか、専門家に意見を聞きながら、自分たちで考えてつくることになります。
急がば回れという言葉があるように、自分たちで考えながら進むほうが、結果的に早く理想郷にたどり着くかもしれません。
ファーストリテイリングは
パッケージ製品は、カスタマイズの自由度が低く、変更に時間が掛かるため、基幹業務システムで、会社のコアのナレッジがたまっている部分は、パッケージを使うのではなく、今後は自分たちで作るべきだ
という判断をしています。
基幹システムであるコア業務(SCM、PLM、CRM)は、自社のナレッジの宝庫です。
その業務を自分たちでシステム化するということは、自分たちのナレッジを言語化、体系化して資産にする過程でもあります。
最初はしんどいかもしれませんが、逃げずにそこをやりとげると、その後、企業が変化に強い構造になり持続的に飛躍できるようになるのではないでしょうか。

[…] マイクロサービスアーキテクチャ、MVCやヘキサゴナルアーキテクチャな […]
[…] 427;アプリケーションです。 マイクロサービスは、フロントエンドアプ} […]
[…] 992;性を上げることができる マイクロサービスは、大規模なシステムをë […]
[…] これを見ると、作業のムリ、ムダ、ムラをなくすといいうリーン生産方式、および、アジャイル開発の考え方が反映されていることがわかります。 バリューストリームとは、ビジネス上の仮説を立案してから、顧客に価値を送り届ける技術サービスを生み出すまでの間に必要なプロセスのことです。 バリューチェーンで言えば、主要活動の流れということになります。 また、上記プロセスの自動化には、テストからデプロイまでを自動化する継続的デリバリの考え方が反映されていますし、マイクロサービスアーキテ…を適用することで、バッチサイズを縮小することができます。 […]
[…] 変革アプリケーションは、データドリブン経営の過程で開発れます。 業務担当者が自分の業務の課題を解決する解決策の一つとして変革アプリケーションを開発します。 なお、変革アプリケーションのベースとなるSoRやSoIは、システムエンジニアが開発します。 SoRは、変革アプリケーションに活用されやすいようにマイクロサービスアーキテ…で実現します。 […]
[…] マイクロサービスアーキテクチャ […]
[…] 2395;し、業務ドメインごとにマイクロサービスを整備し、そこで、業務| […]
[…] システムの構成要素であるモジュールは、相手の要素にインターフェースだけを公開し、実装(実現)部分はブラックボックすることで、システムの構成要素をモジュール化することで、実装部分が自由に交換でき、保守性が向上するとともに、モジュールを再利用することによって生産性が向上します。 つまり、モジュール化の要は、 仕様と実現の分離 です。 ビジネスの場合、モジュールの仕様部分がジョブ(職務)になります。 ジョブはビジネス機能の仕様(型)で、それが遂行すべき複数のタスク(課業)を持ちます。 そして、ビジネス機能の仕様を実現するのがメンバー、パートナー、アプリケーション、財務資産(機械など)など能動的な資産になります。 例えば、アプリケーションをマイクロサービスとフロントエンドアプリケーションで実装し、ジョブを実現することができます。 […]
[…] 9640;いアプリケーションこそマイクロサービスを適用すべきだと考えま{ […]
[…] えます。 そして、この業務活動の規模が大きくて特殊性が高いアプリケーションこそマイクロサービスを適用すべきだと考えます。 なぜならば、ビジネスの根幹となる業務を支援するア […]
[…] このようなデータの散在や無駄な開発を防ぐ有効な手段がマイクロサービスです。 ビジネスロジックとデータをマイクロサービスとしてカプセル化することによって、信頼できるデータ […]
[…] データ構造の変更によるリスクを抑えるための方法の一つに、データにアクセスできるオブジェクトの範囲を限定するという考え方があります。 このオブジェクトの範囲、すなわちドメインを中心にシステムを設計する手法が、ドメイン駆動設計です。 ドメイン駆動設計(DDD)とは、ドメイン(開発対象となる業務領域)を中心に据えて、システムを設計・開発する手法です。 この手法により、業務の本質を表すドメインの構造や振る舞い(業務ルールや機能)を正確にモデル化でき、再利用性や拡張性が高く、変化に強い堅牢なシステムを構築することが可能になります。 DDDの重要なポイントは、技術的な設計よりも、まず組織全体で適切な業務領域(ドメイン)をどのように定義し設計するかにあります。 すなわち、ドメイン駆動設計の本質は、究極的には業務の仕組みそのもの、すなわちビジネスアーキテクチャの設計にあるといえます。 一方で、システムを構成する要素を、独立してデプロイ可能な小さなソフトウェア部品に分割し、それぞれが実現するサービスを他の部品に提供し合うことで全体のシステムを構成するという考え方が、マイクロサービスです。 一つのマイクロサービスは、そのサービスを実現するために必要なデータベースも内包します。 したがって、マイクロサービスはデータベースを含めて処理とデータをカプセル化した自律したソフトウェア部品となります。 このように、ドメイン駆動設計によって設計されたドメインごとにマイクロサービスを構築し、それらを疎結合で連携させることで、ビジネスとITが一体となり、環境の変化に柔軟に適応できる「変化に強いシステム」を実現することができます。 […]
[…] ドメイン駆動設計(DDD)とは、ドメイン(開発対象となる業務領域)を中心に据えて、システムを設計・開発する手法です。 この手法により、業務の本質を表すドメインの構造や振る舞い(業務ルールや機能)を正確にモデル化できます。 また、DDDは、ドメインの機能やデータをオブジェクトとしてモジュール化し、オブジェクト同士のメッセージングによってシステムを構成するため、再利用性や拡張性が高く、変化に強い堅牢なシステムを構築することができます。 DDDの重要なポイントは、技術的な設計よりも、まず組織全体で適切な業務領域(ドメイン)をどのように定義し設計するかにあります。 すなわち、ドメイン駆動設計の本質は、究極的には業務の仕組みそのもの、すなわちビジネスアーキテクチャの設計にあるといえます。 一方で、システムを構成する要素を、独立してデプロイ可能な小さなソフトウェア部品に分割し、それぞれが実現するサービスを他の部品に提供し合うことで全体のシステムを構成するという考え方が、マイクロサービスです。 一つのマイクロサービスは、そのサービスを実現するために必要なデータベースも内包します。 したがって、マイクロサービスはデータベースを含めて処理とデータをカプセル化した自律したソフトウェア部品となります。 このように、ドメイン駆動設計によって設計されたドメインごとにマイクロサービスを構築し、それらを疎結合で連携させることで、ビジネスとITが一体となり、環境の変化に柔軟に適応できる「変化に強いシステム」を実現することができます。 […]
[…] 「製品の出荷」プロセスのコラボレーション このジョブを支援する単位としてマイクロサービスを設計し、顧客に価値を生み出すコアプロセスを中心に統合します。 マイクロ […]