![]()
ここでは、次の手法を組み込んで堅牢なアプリケーションを迅速に開発する方法について説明します。
- ユースケース駆動開発
- ドメイン駆動設計
- マイクロサービスアーキテクチャ
- ノーコード開発
次の手順に従って、法人顧客マスターデータを管理する法人顧客管理システムを具体的な例として説明します。
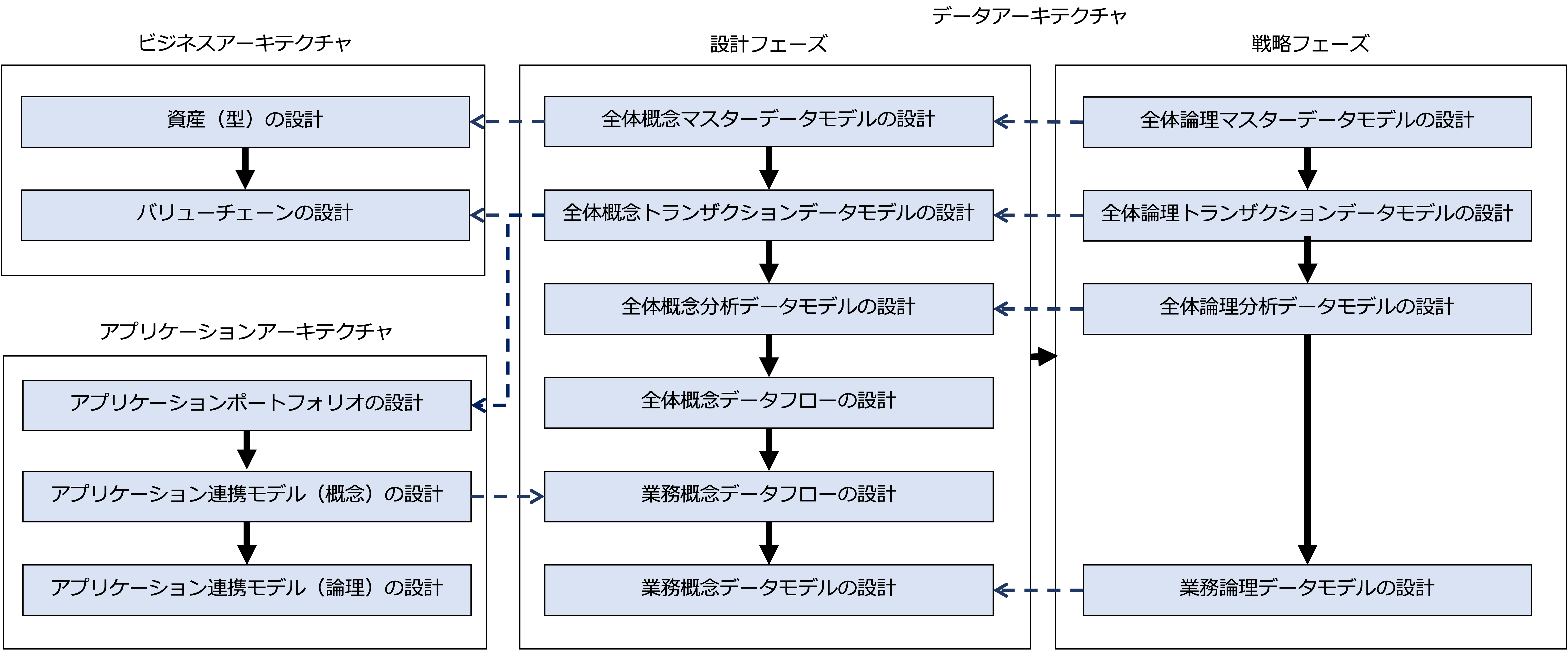
データアーキテクチャの設計
次の図は、データアーキテクチャを設計するプロセスを示しています。
全体概念マスターデータモデルの設計
顧客マスターデータの全体概念マスターデータモデルを次のように設計したとします。
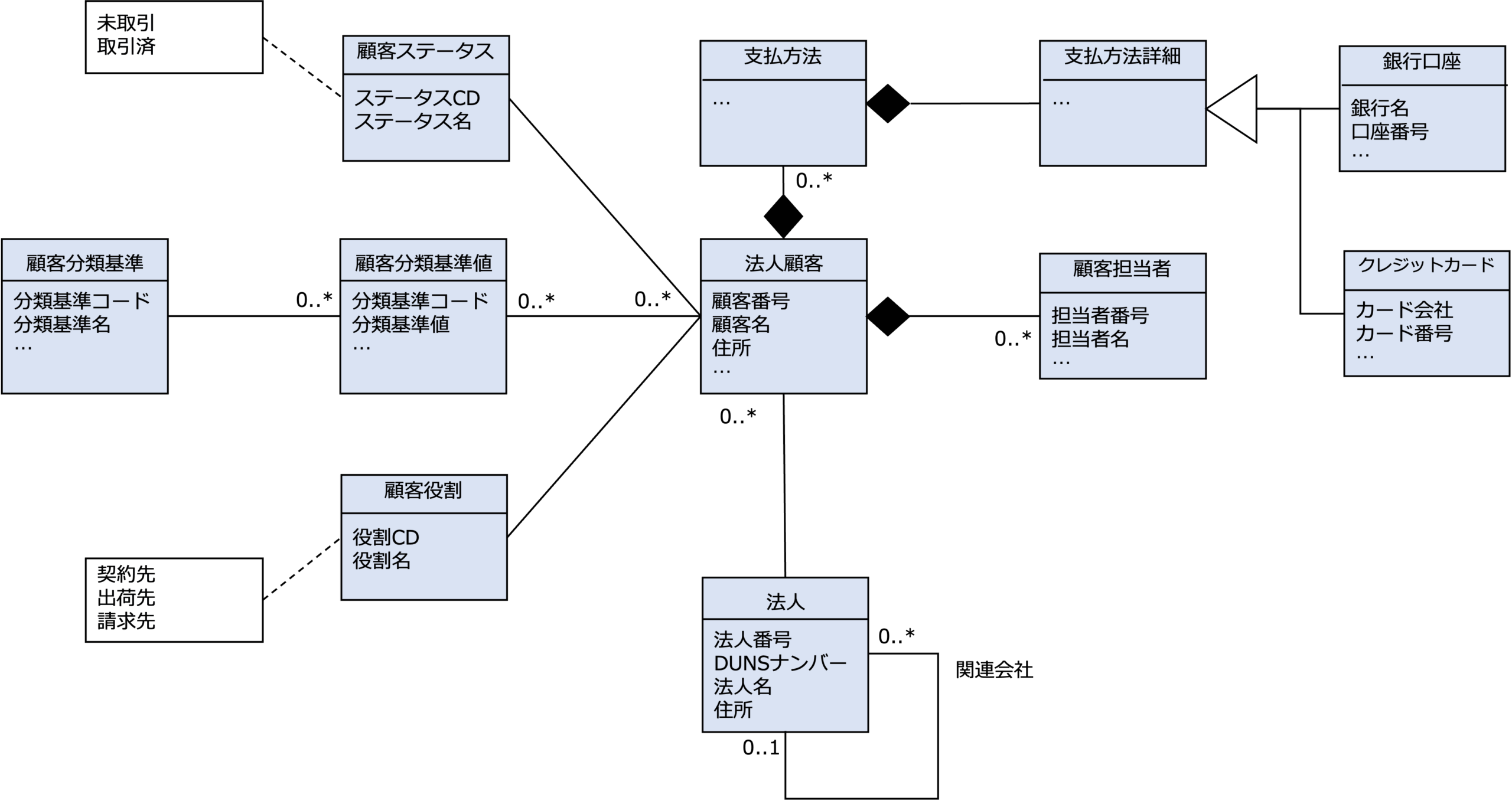
この概念データモデルを見ると、このビジネスでは、次のような観点で法人顧客を管理することがわかります。
- 法人番号を持つ法人をベースに法人顧客を管理する。
国税庁が管理する13桁の法人番号や、全世界の企業を一意に識別できる9桁のDUNSナンバーを法人番号の候補として考えることができます。 - 法人は、関連会社の関係もわかるようにする。
- 法人顧客ごとに複数の顧客担当者を定義できるようにする。
- 法人顧客ごとに複数、支払手段を設定できるようにする。
- 同じ法人顧客でも、契約先、出荷先、請求先など役割の違いが識別できるようにする。
- すでに取引がある顧客かまだ取引がない潜在的な顧客か識別できるようにする。
- 例えば、業種、規模、地域など様々な切り口で法人顧客を分類できるようにする。
全体概念データフローの設計
また、顧客マスターデータが更新されるときの全体概念データフローを次のように設計したとします。
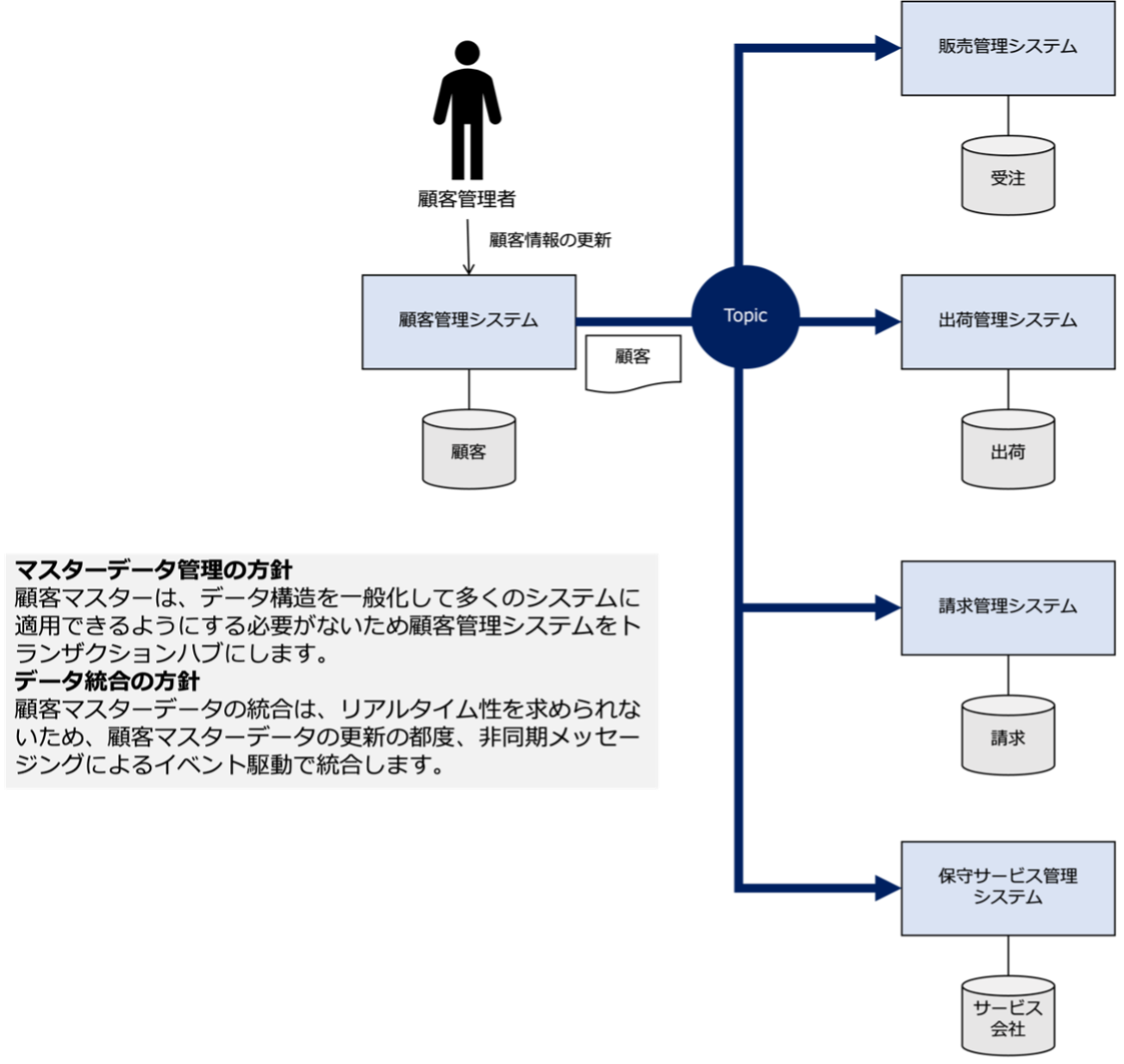
これを見ると、マスターデータ管理の方針として、顧客マスターは、データの構造を一般化して多くのシステムに適用にする必要がないため、顧客マスターの主管システムである顧客管理システムをトランザクションハブにしていることがわかります。
また、データ統合の方針として、顧客マスターデータの統合は、リアルタイム性を求められないため、顧客マスターデータの更新の都度、非同期メッセージングによるイベント駆動で統合していることがわかります。
この全体概念データフローは、トランザクションハブである顧客管理システムの顧客データが更新される都度、顧客データを必要とするシステムにTopicを介して配布(ブロードキャスト)するというイベント駆動統合の仕組を表しています。
顧客データを必要とするシステムは、顧客管理システムから送られていくる最新の顧客データで、自身の持つ顧客データを更新します。
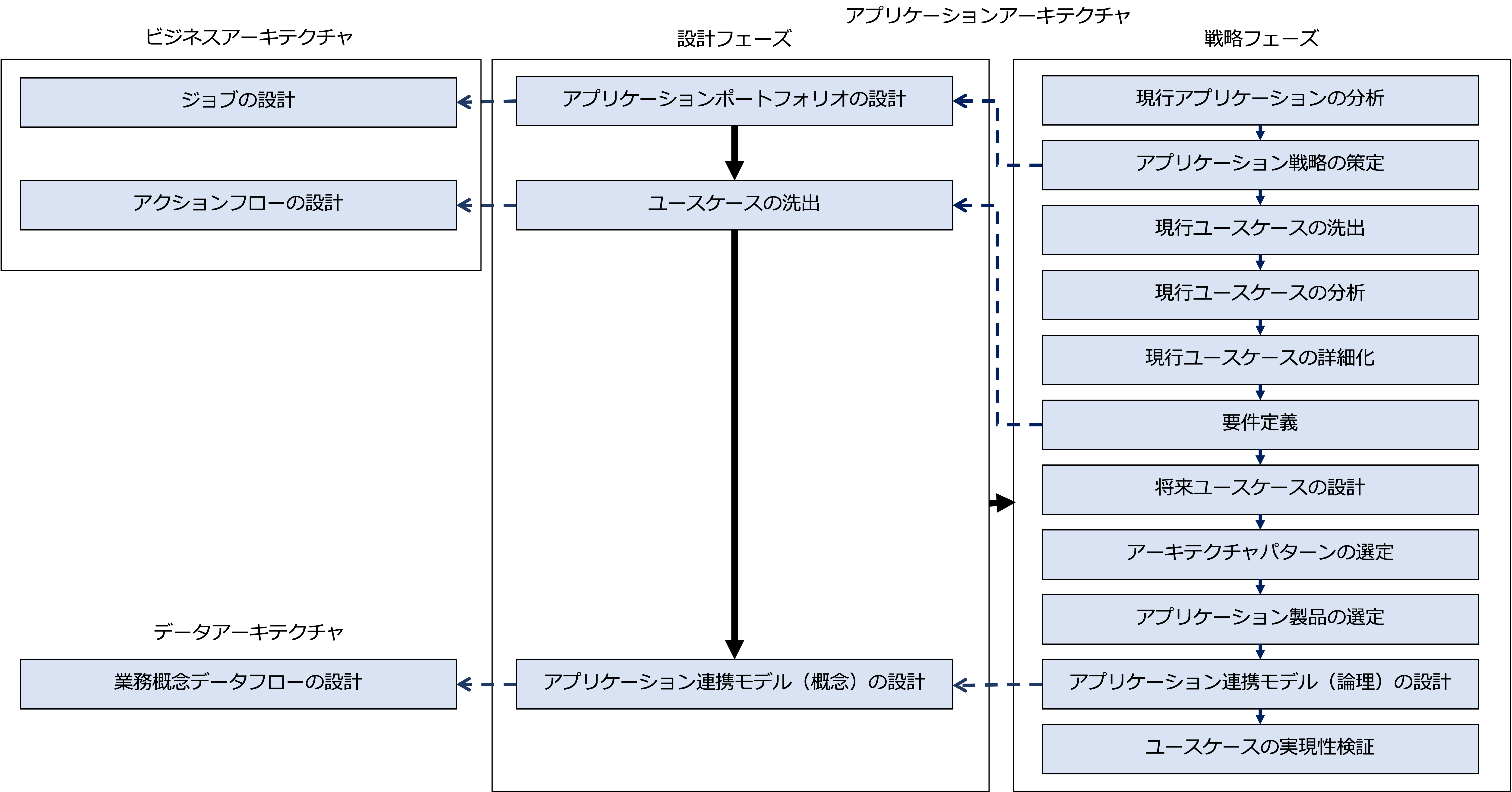
アプリケーションアーキテクチャの設計
次の図は、アプリケーションアーキテクチャを設計するプロセスを示しています。
ユースケースの洗出
バリューチェーンを見ると、顧客管理の主なプロセスは、「顧客の獲得」、「顧客の活性化」、「顧客の維持」、「顧客の処分」であることがわかります。
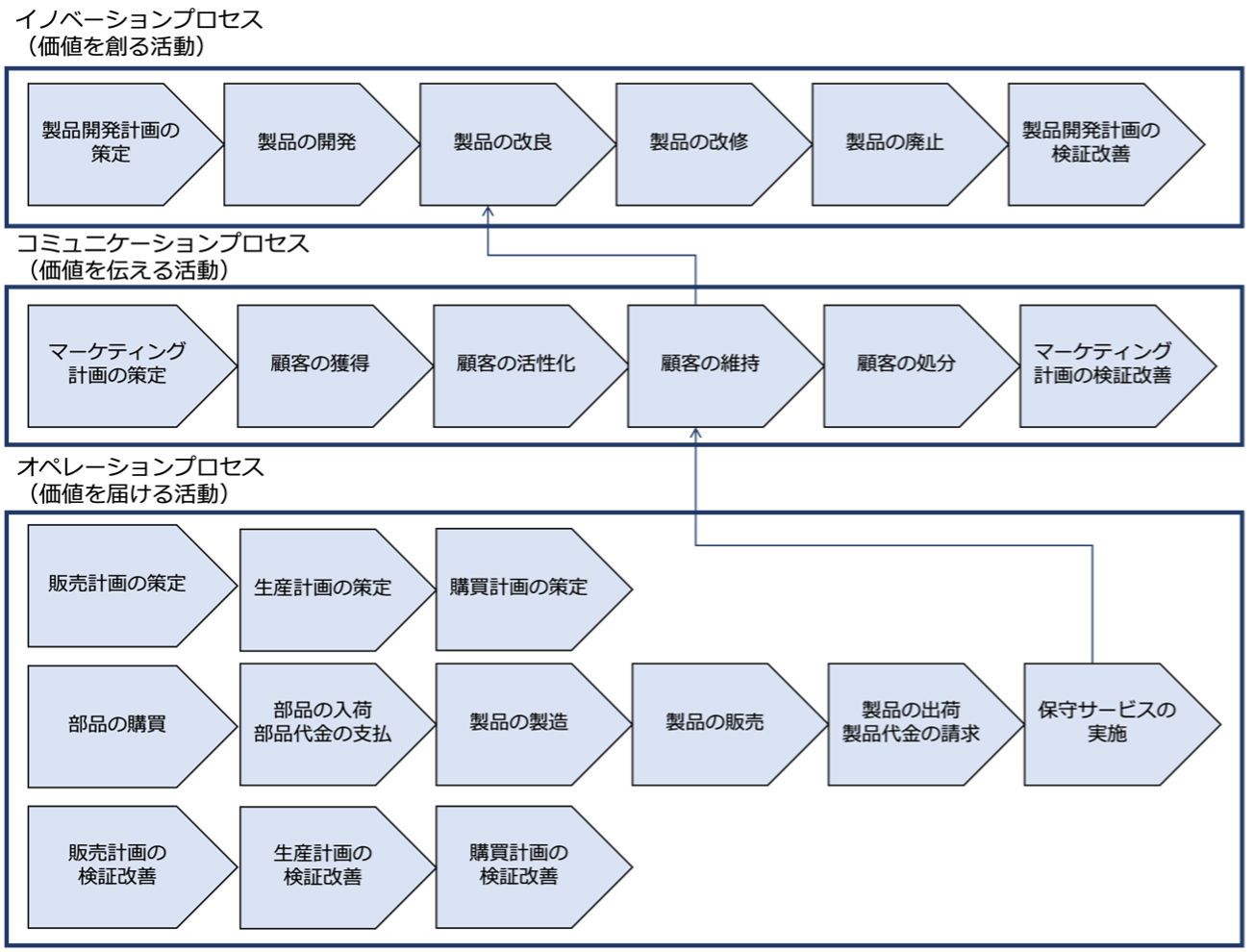
これから、顧客管理フロントエンドシステムの主なユースケースは次のようになると考えられます。
ユースケースの分析
ユースケースを分析するときは、概念データモデルのエンティティのライフサイクルが参考になります。
次の図は、法人顧客の概念データモデルの法人顧客エンティティのライフサイクルを分析したステートマシンです。

これをみると、次のことがわかります。
- 未登録の状態の顧客は、登録されることによって未取引の状態になり、取引開始によって取引中状態になる。
- また、取引停止によっって停止中状態になり、取引終了によって取引終了状態になる。
- それから、未登録の状態の顧客を登録することで、取引中にすることもできるし、取引中の顧客を取引終了にすることもできる。
- 逆に、取引停止中の顧客の取引を再開することもできるし、取引中の顧客の取引を取消すこともできる。
- また、未取引中と取引中の顧客のみ、顧客情報を変更することができる。
- なお、顧客情報を変更する一環として、顧客担当者と支払方法を設定することができる。
顧客担当者は、未取引中と取引中の顧客に対して設定できるが、支払方法は、取引中の顧客でないと設定することができない。
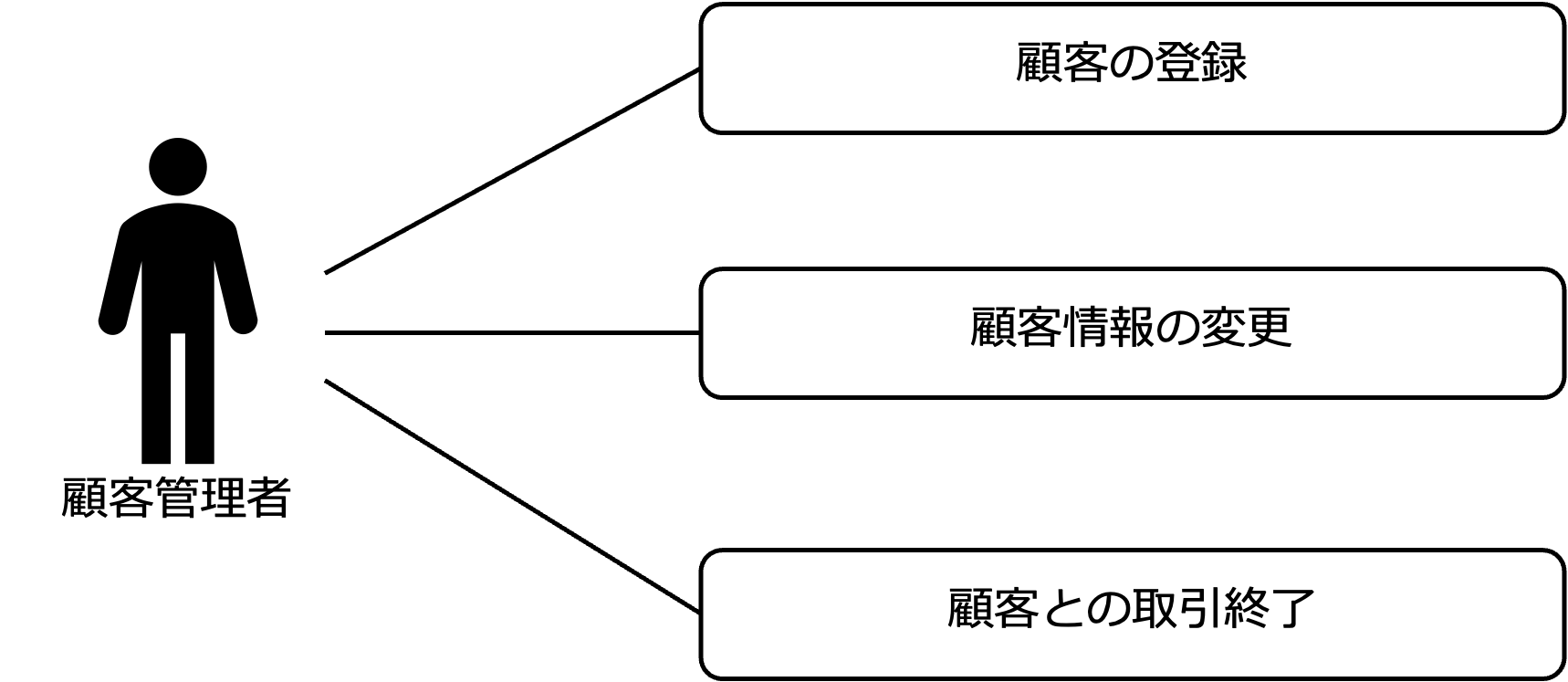
法人顧客エンティティのライフサイクルを考えると、 顧客の登録、顧客情報の変更、顧客の取引終了ユースケースだけでなく、業務上、次のようなユースケースがあることがわかります。
なお、ここでは、顧客担当者の設定ユースケースと支払方法を設定ユースケースは、顧客情報の変更ユースケースを拡張した形にしています。
さらに、顧客をさまざまな分析軸で分類することがあると考え、顧客情報の変更ユースケースの一環として、顧客の分類ユースケースを追加しています。
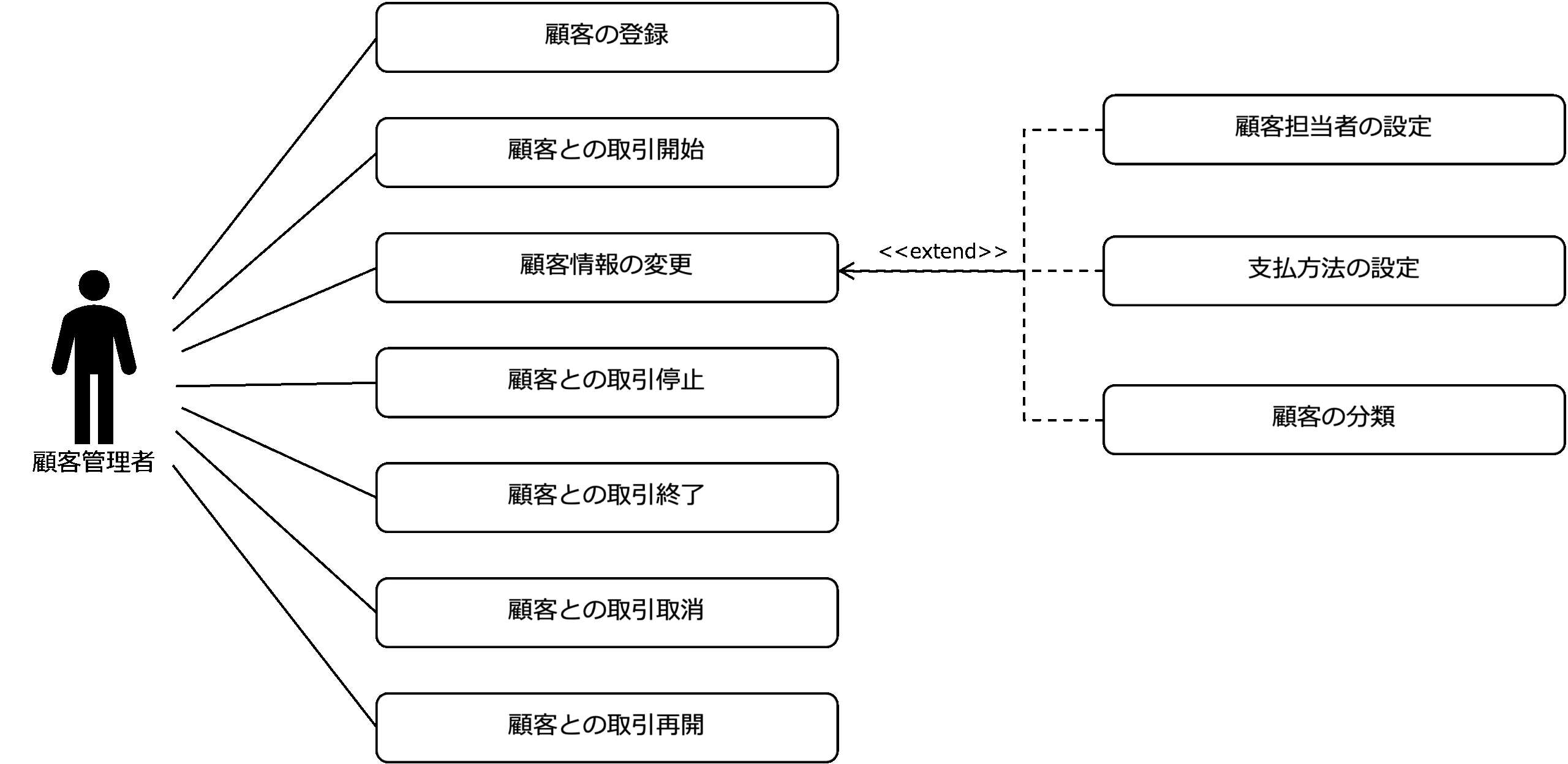
これまでは、業務的視点でユースケースを考えてきましたが、ここで、システムの視点でユースケースを分析し、さらに洗練させてみましょう。
次の図は、システムの視点でユースケースを洗練したモデルです。
これを見ると、顧客情報の照会ユースケースが起点となって、顧客情報の更新ユースケース、顧客担当者の設定ユースケース、支払方法を設定ユースケース、顧客の分類ユースケースが拡張されていることがわかります。
また、顧客との取引開始や取引停止など顧客の状態変化をともなうものは、顧客のステータスの変更と考え、顧客取引の変更ユースケースとして汎化し、顧客情報の更新ユースケースに包含させています。
それから、顧客情報の照会ユースケースと顧客の登録ユースケースは、ともに、顧客一覧の照会ユースケースから派生することがわかります。
システムの視点で作成したユースケースモデルからUIの構成を次のように考えることができます。
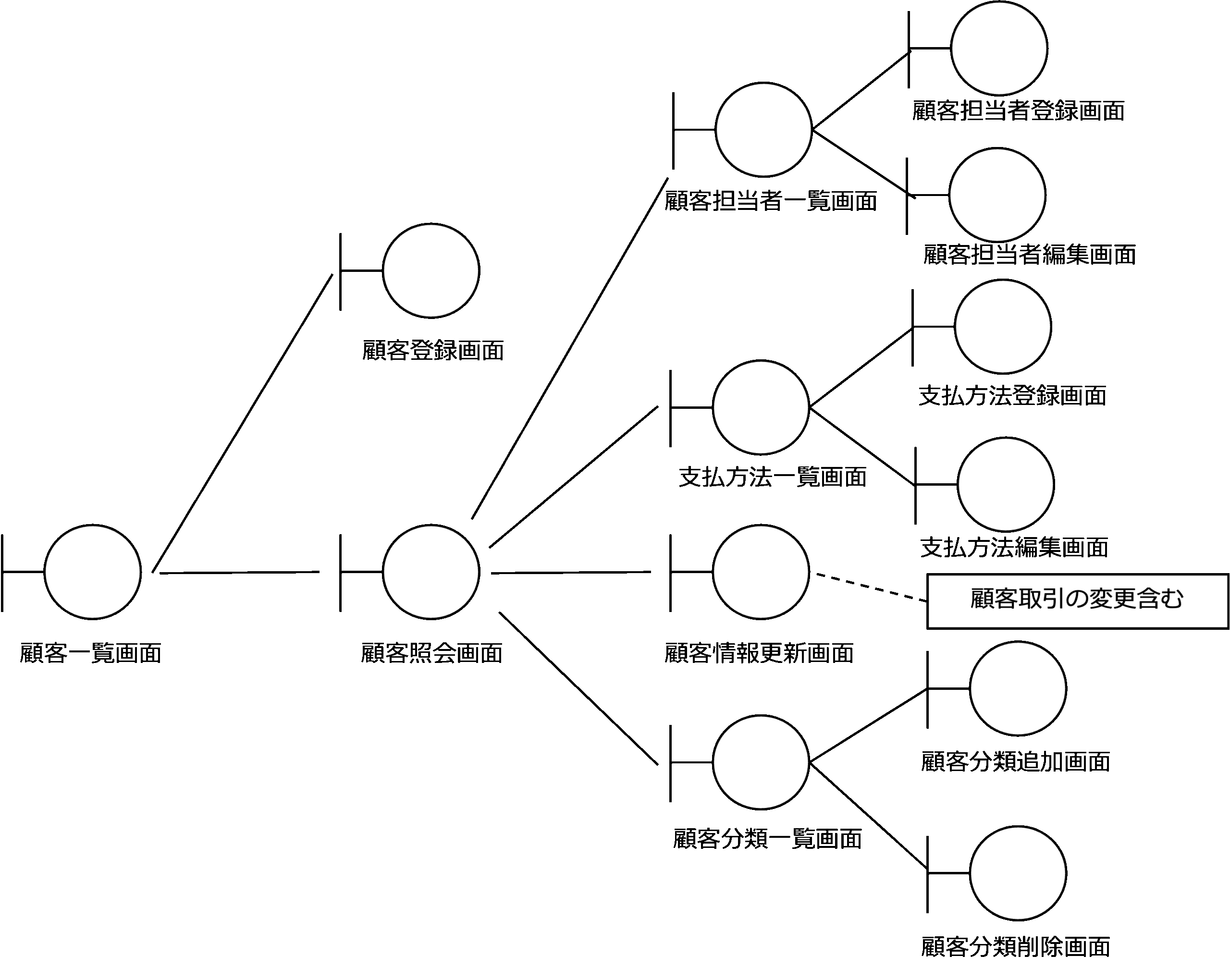
最初に顧客一覧画面があり、そこから顧客登録画面と顧客照会画面に遷移し、顧客照会画面から、顧客担当者一覧画面、支払方法一覧画面、顧客情報更新画面、顧客分類一覧画面に遷移することがわかります。
ユースケースの詳細化
次の図は、上述した顧客管理フロントエンドアプリケーションの顧客の登録ユースケースの画面遷移図です。

この図をみると、顧客一覧画面で顧客の追加を選択することで、顧客登録画面に遷移し、顧客を登録することがわかります。
なお、ここでは、画面遷移のトリガーに、対応するAPIを設定しています。
この図から、顧客一覧画面をロードするときは、search_customers_pageというAPIを呼び出し、顧客を登録するときは、register_customerというAPIを呼び出していることがわかります。
次の図は、顧客情報の照会ユースケースの画面遷移図です。
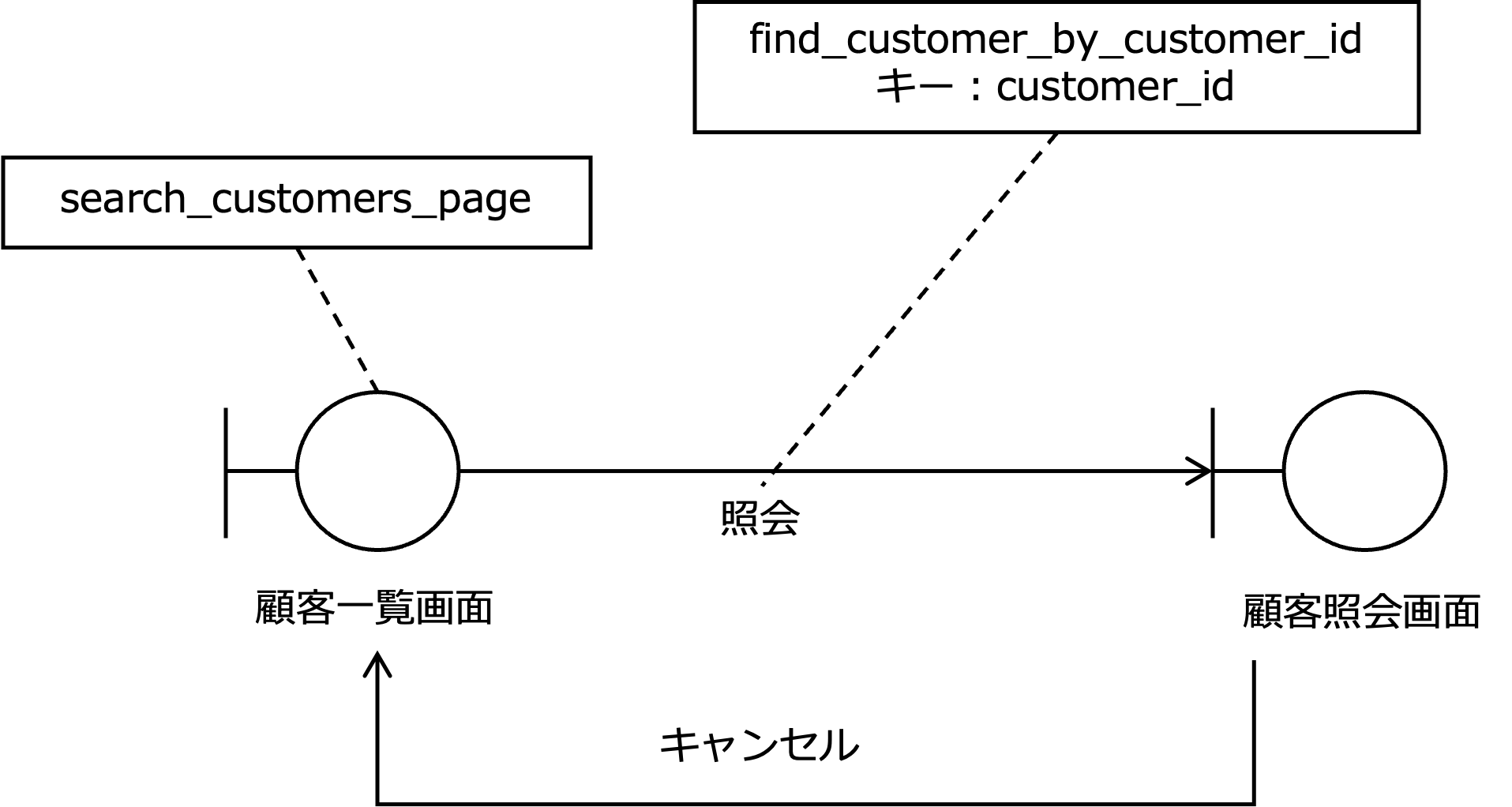
この図をみると、顧客一覧の顧客を照会することで、顧客照会画面に遷移することがわかります。
また、顧客一覧の中の特定の顧客の情報を照会するとき、find_customer_by_customer_idというAPIを呼び出し、その際、キーとしてcustomer_idを渡す必要があることがわかります。
次の図は、顧客情報の更新ユースケースの画面遷移図です。
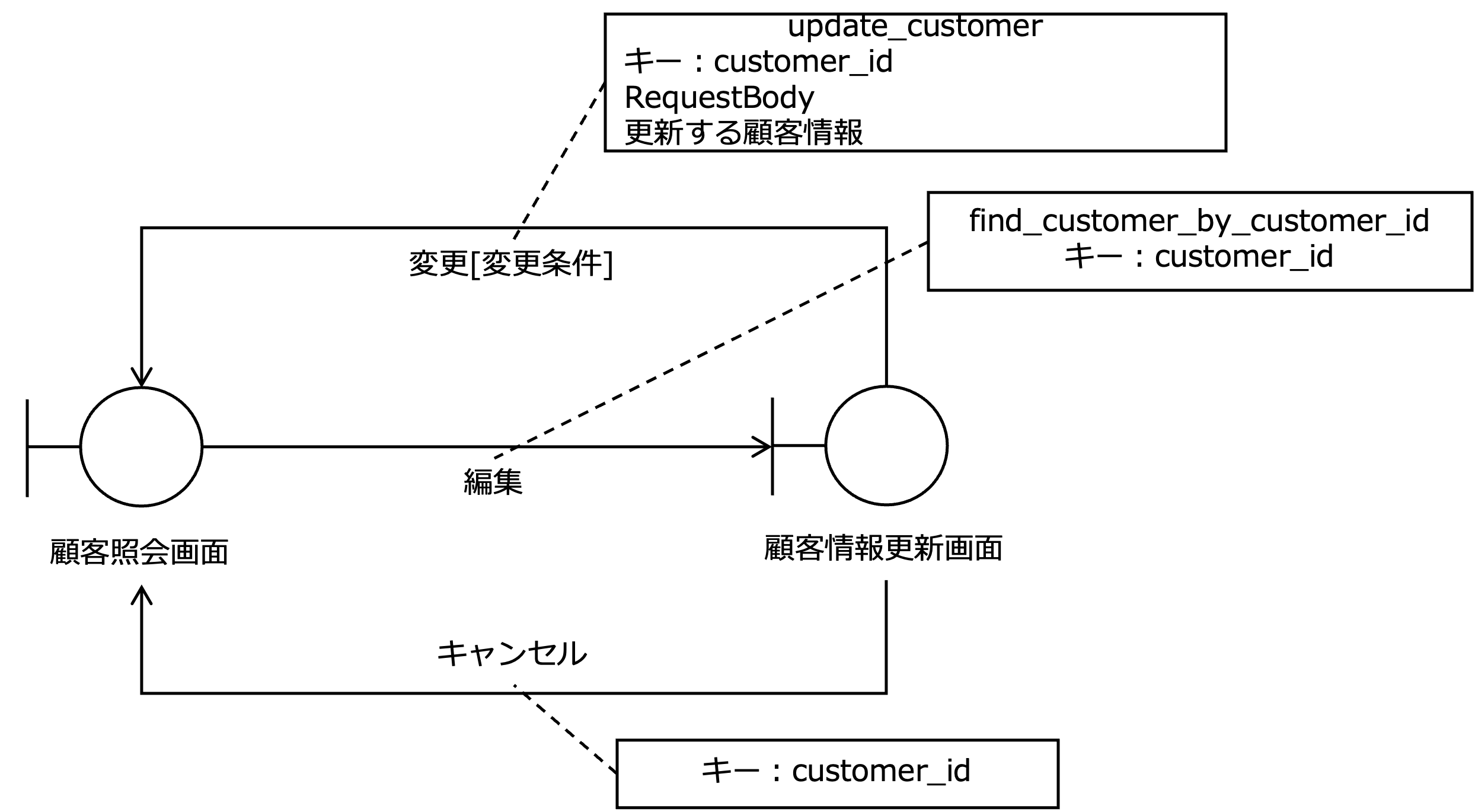
この図をみると、顧客照会画面で編集を選択することで、顧客情報更新画面に遷移し、顧客情報を変更することができることがわかります。
また、顧客照会画面から顧客情報更新画面に遷移するとき、find_customer_by_customer_idを呼び出すためのキーとしてcustomer_idを渡す必要があることがわかります。
また、顧客情報を変更するとき、update_customerというAPIを呼び出し、その際、キーとしてcustomer_id、および、更新する顧客情報を渡す必要があることがわかります。
さらに、顧客情報更新画面でキャンセルすると、顧客照会画面のfind_customer_by_customer_idを呼び出すために必要なキーとしてcustomer_idを渡し、顧客照会画面に戻ることがわかります。
次の図は、顧客の分類ユースケースの画面遷移図です。
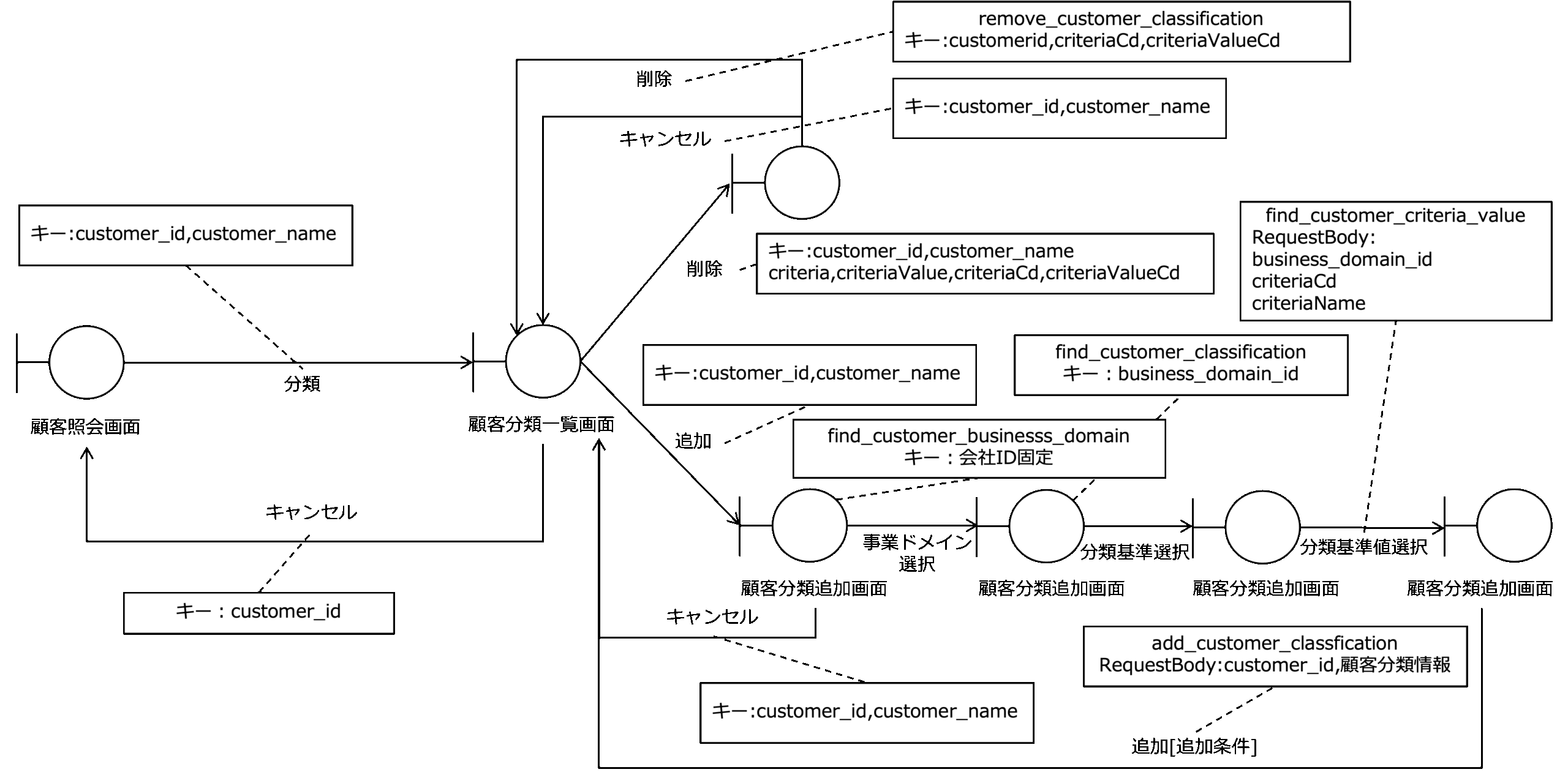
この図をみると、顧客照会画面で分類を選択することで、キーとしてcustomerIdとcustomerNameを渡して顧客分類一覧画面に遷移することがわかります。
また、顧客分類一覧画面で追加を選択すると、キーとしてcustomerIdとcustomerNameを渡して顧客分類追加画面に遷移することがわかります。
顧客分類追加画面では、会社IDをキーにfind_customer_businesss_domainを呼び出し、事業ドメインが選択できること、選択された事業ドメインのbusiness_domain_idをキーにfind_customer_classificationを呼び出し、顧客分類基準が選択できること、選択された事業ドメインのbusiness_domain_idとcriteriaCd、criteriaNameを渡し、find_customer_criteria_valueを呼び出すことによって顧客分類基準値が選択できることがわかります。
顧客分類追加画面で追加を選択すると、キーとしてcustomerIdと顧客分類情報を渡してadd_customer_classificationを呼び出し、顧客分類を追加して、顧客分類一覧画面に戻ることがわかります。
また、顧客分類追加画面でキャンセルすると、キーとしてcustomerIdとcustomerNameを渡して顧客分類一覧画面に戻ることがわかります。
次に、顧客分類一覧画面で追加を選択すると、キーとしてcustomerIdとcriteriaCd、criteriaValueCdを渡して顧客分類削除画面に遷移することがわかります。
顧客分類削除画面で削除を選択すると、キーとしてcustomerIdとcriteriaCd、criteriaValueCdを渡してremove_customer_classificationを呼び出し、顧客分類を削除して、顧客分類一覧画面に戻ることがわかります。
また、顧客分類削除画面でキャンセルすると、キーとしてcustomerIdとcustomerNameを渡して顧客分類一覧画面に戻ることがわかります。
アプリケーション連携モデル(論理)の設計
上記顧客マスターデータの全体概念データフローをアプリケーション連携モデル(論理レベル)を展開すると次の例のようになります。
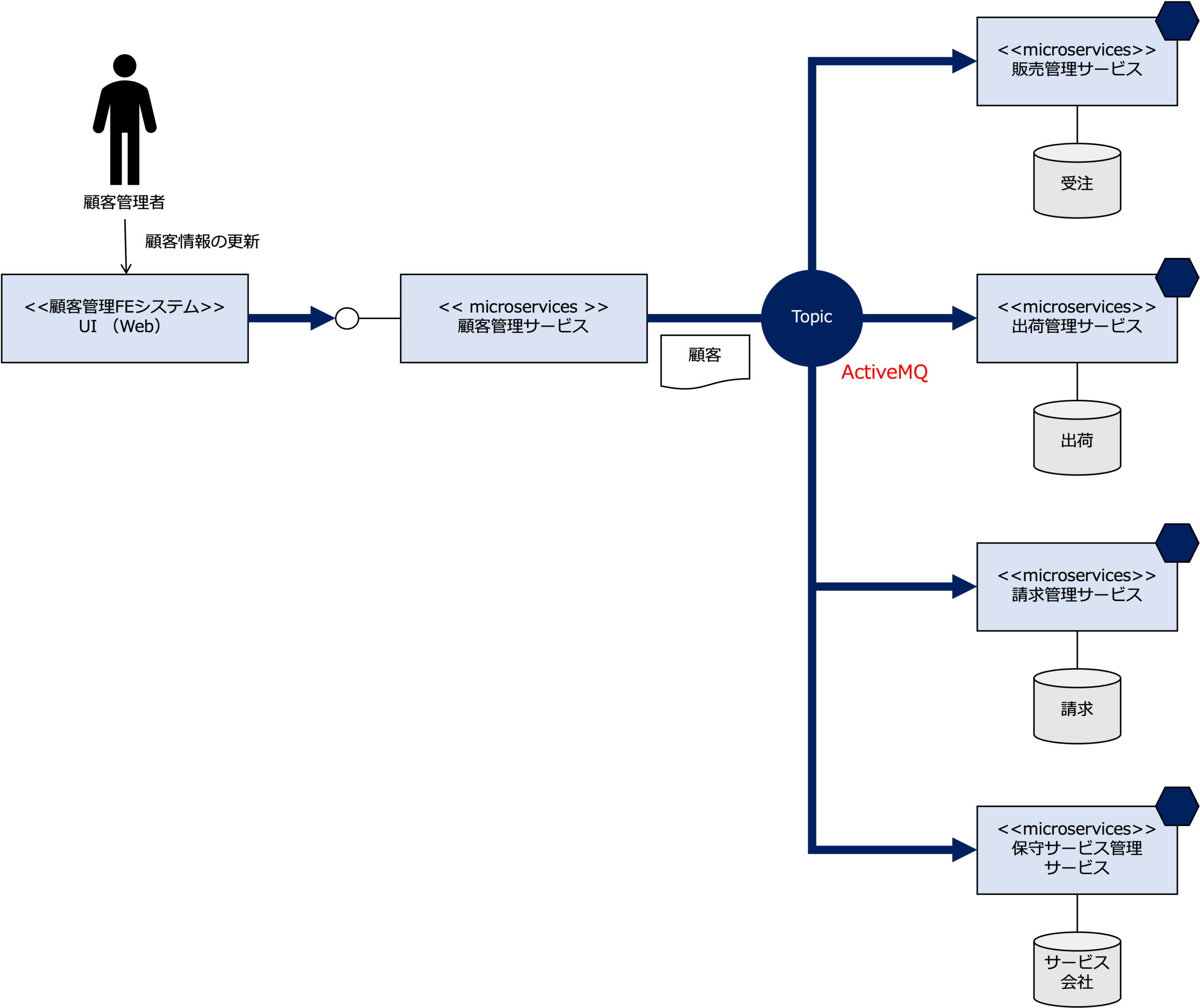
このアプリケーション連携モデルは、顧客管理サービスの顧客データが更新される都度、顧客データを必要とするマイクロサービスに、ActiveMQのTopicを介して配布(ブロードキャスト)するというイベント駆動アーキテクチャの仕組を表しています。
ユースケース駆動開発のアプローチ
ユースケース駆動開発では、次のように「機能」、「構造」、「振舞」の3つのステップで開発を進めることになります。
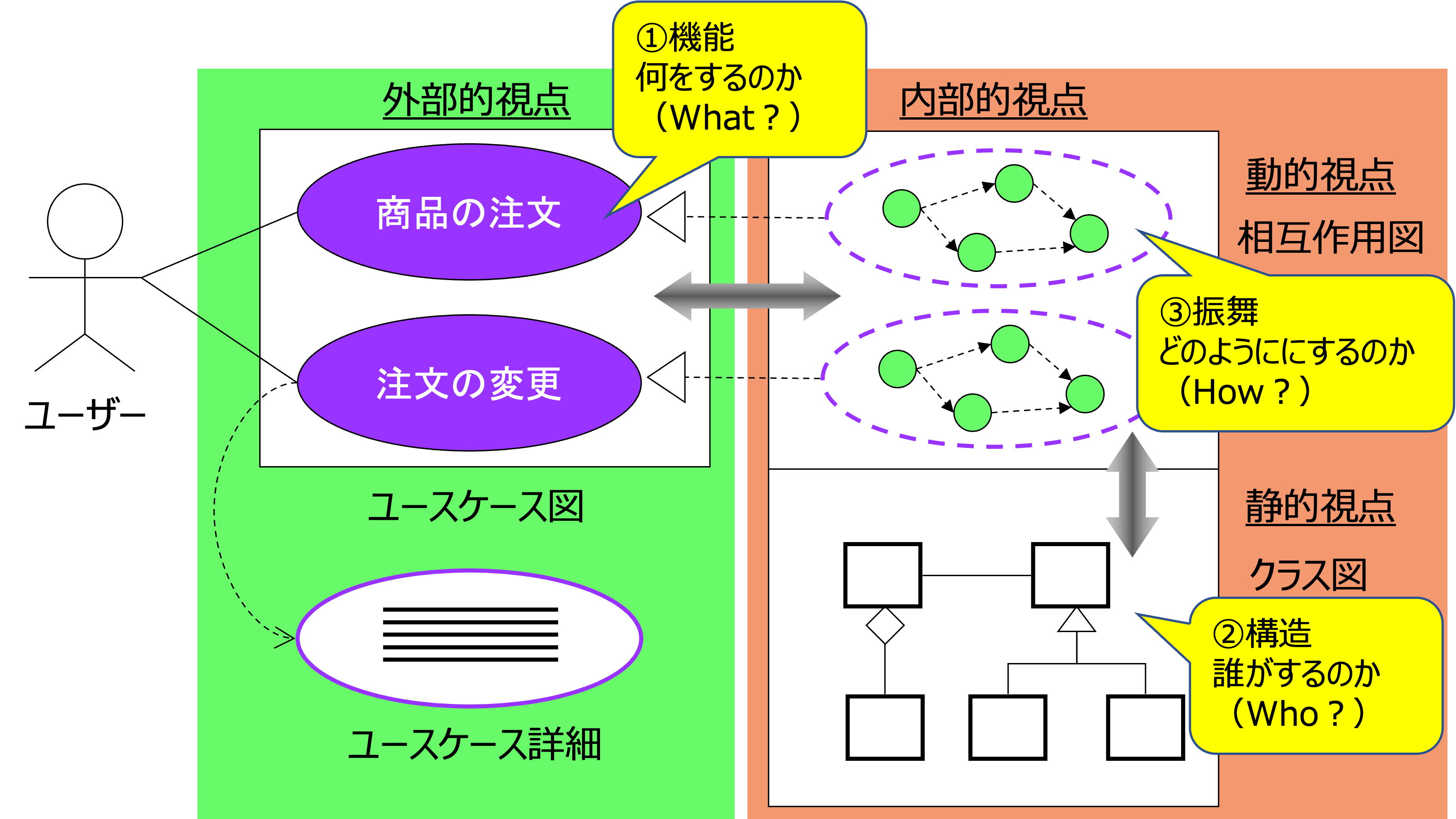
- 機能
まず、外部的視点で、システムがユーザーに提供すべき価値をユースケース(何をするのか)としてモデル化します。 - 構造
次に、内部的視点で、ユースケースを実現するシステムの構成要素の構造(誰が実現するのか)を明確にします。 - 振舞
最後に、システムを構成する要素の振舞(どのようにユースケースを実現するのか)を分析することで、システムの構造の妥当性を検証します。
このアプローチをシステム開発の工程で分けると次のようになります。
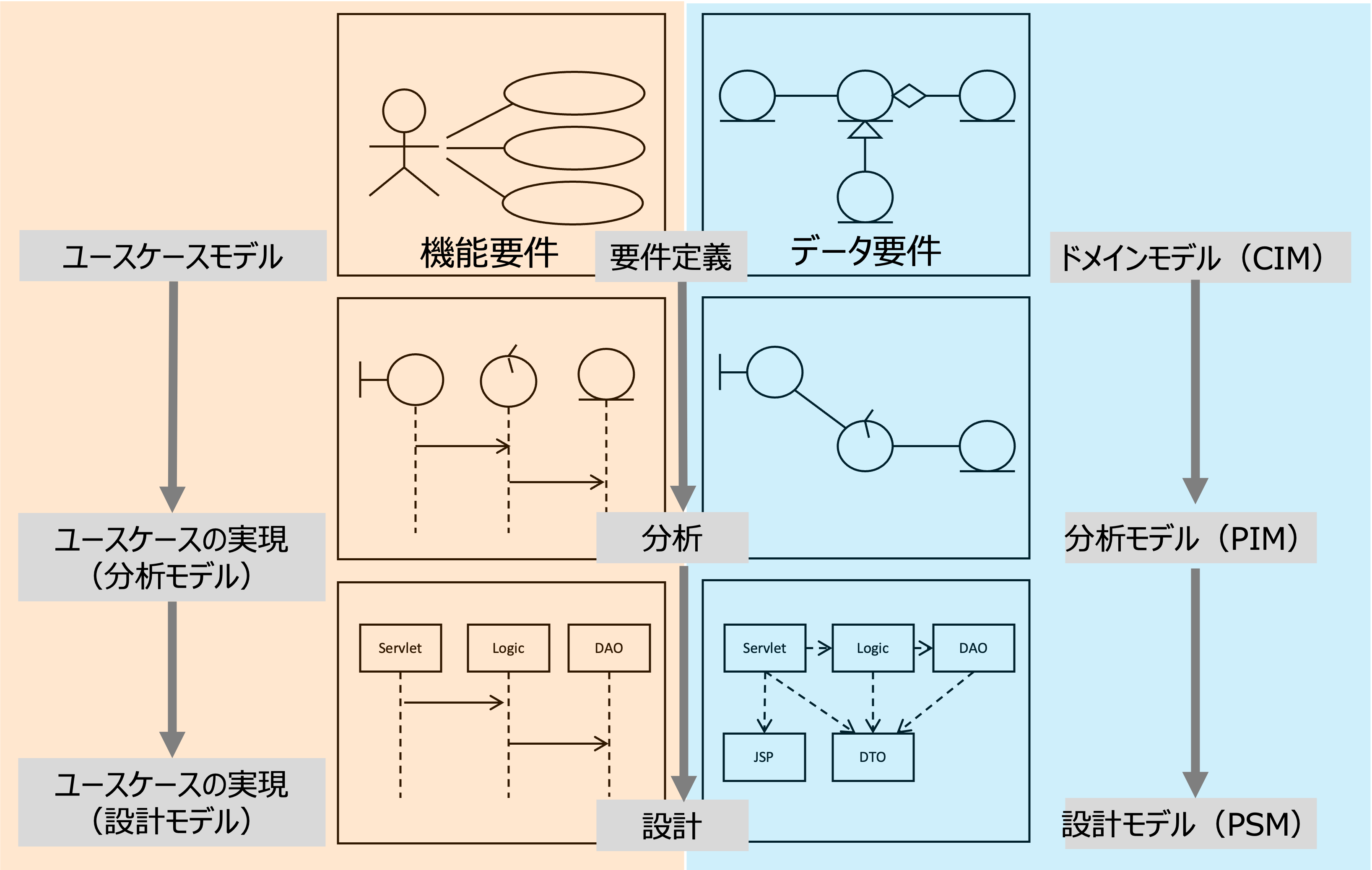
図にあるCIM、PIM、PSMは、MDA(Model-Driven Architecture:モデル駆動アーキテクチャ)の概念です。
MDAでは、システムを構築するとき、次の3つのモデルを分けて考え、CIM→PIM→PSMという流れで設計することで、より堅牢なシステムをつくることができるとしています。
- CIM(Computation Independent Model)
計算機処理に依存しないモデル。業務モデル。 - PIM(Platform Independent Model)
IT基盤に依存しないモデル。論理モデル。 - PSM(Platform Specific Model)
IT基盤に特化したモデル。物理モデル。
IT基盤に依存した設計モデル(PSM)は技術の進歩に応じて変わりますが、本質的な業務をモデル化した概念モデル(CIM)や、論理的なメカニズムを表す分析モデル(PIM)は再利用することができます。
システム開発では、「要件定義」段階で業務の仕組をCIMとして可視化し、「分析」工程でシステムの仕組を論理的に分析しPIMとして表し、「設計」工程で、PIMを、IT基盤に依存したPSMに展開します。
さて、マイクロサービスアーキテクチャを適用する場合、次の図のように、主にUIを司るフロントエンドアプリケーションと、ビジネスロジックや永続化されるデータを管理するマイクロサービスに分けて開発します。
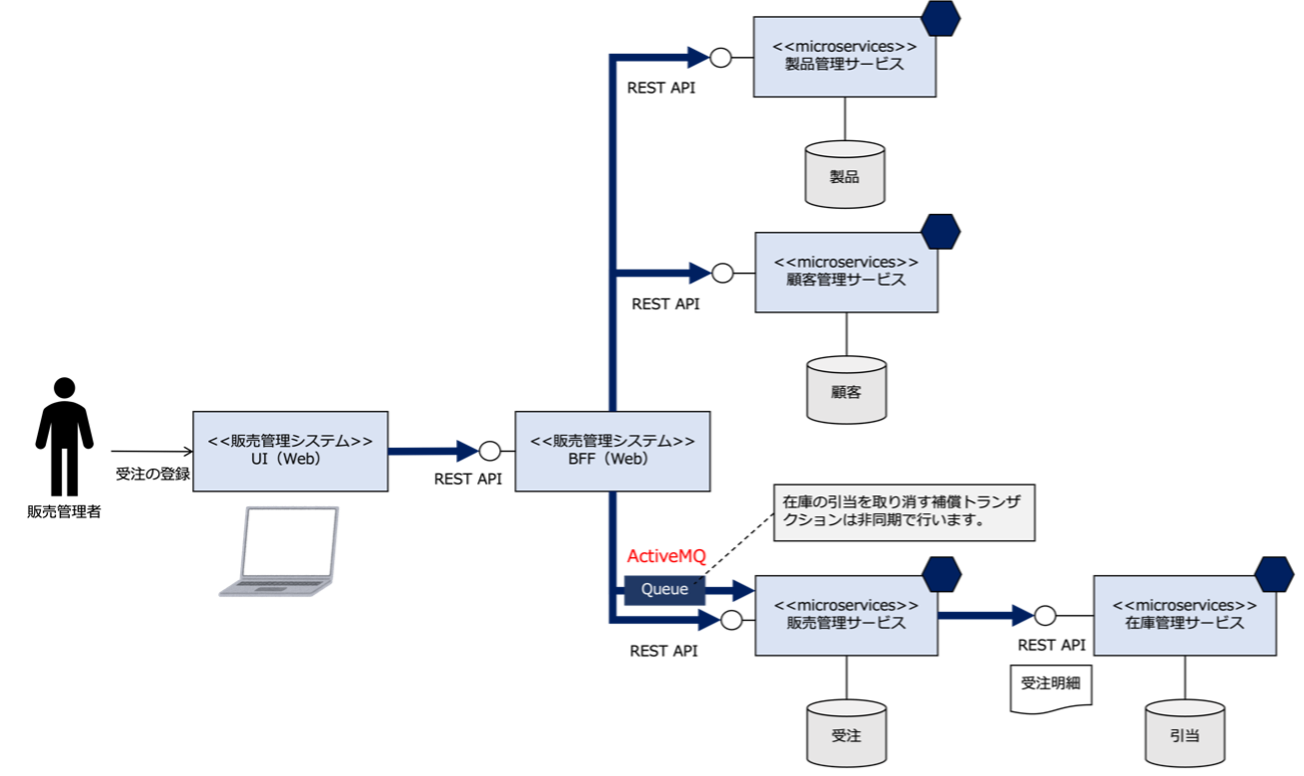
この図の中の、BFFとはBackends For Frontendsの略で、アーキテクチャパターンの1つで、フロントエンドとバックエンドの中間に位置し、双方の複雑な処理を緩和させる役割を担うサーバー機能のことです。
ここでは、マイクロサービスアーキテクチャを前提に、マイクロサービスの開発と、フロントエンドアプリケーションの開発を分けて説明します。
マイクロサービスの開発
ここでは、データアーキテクチャとアプリケーションアーキテクチャの結果を受けて、マイクロサービスを開発する方法について説明します。
要件定義
要件定義では、システムの目的(存在意義)を明確にし、それを実現するためにシステムに求められる要件(必要な条件)を定義します。
ここでは、そのうち、機能要件と、非機能要件のデータ要件で定義する内容について説明します。
- 機能要件
- ユースケース
- 画面構成
- 画面遷移(ビジネスルール)
- データ要件
- ドメインモデル
- 集約ルートのステートマシン
機能要件の定義
機能要件では、業務課題を解決するために必要なシステムの働きを機能要件として定義します。
ユースケース
ユースケース駆動設計では、ユースケースでシステムの働きを表現します。
ここで、重要なのは、ドメインエキスパートから業務上どのようなユースケースが有り得るか聞き出して漏れなく定義することです。
次の図は、顧客管理フロントエンドアプリケーションのユースケースの例です。
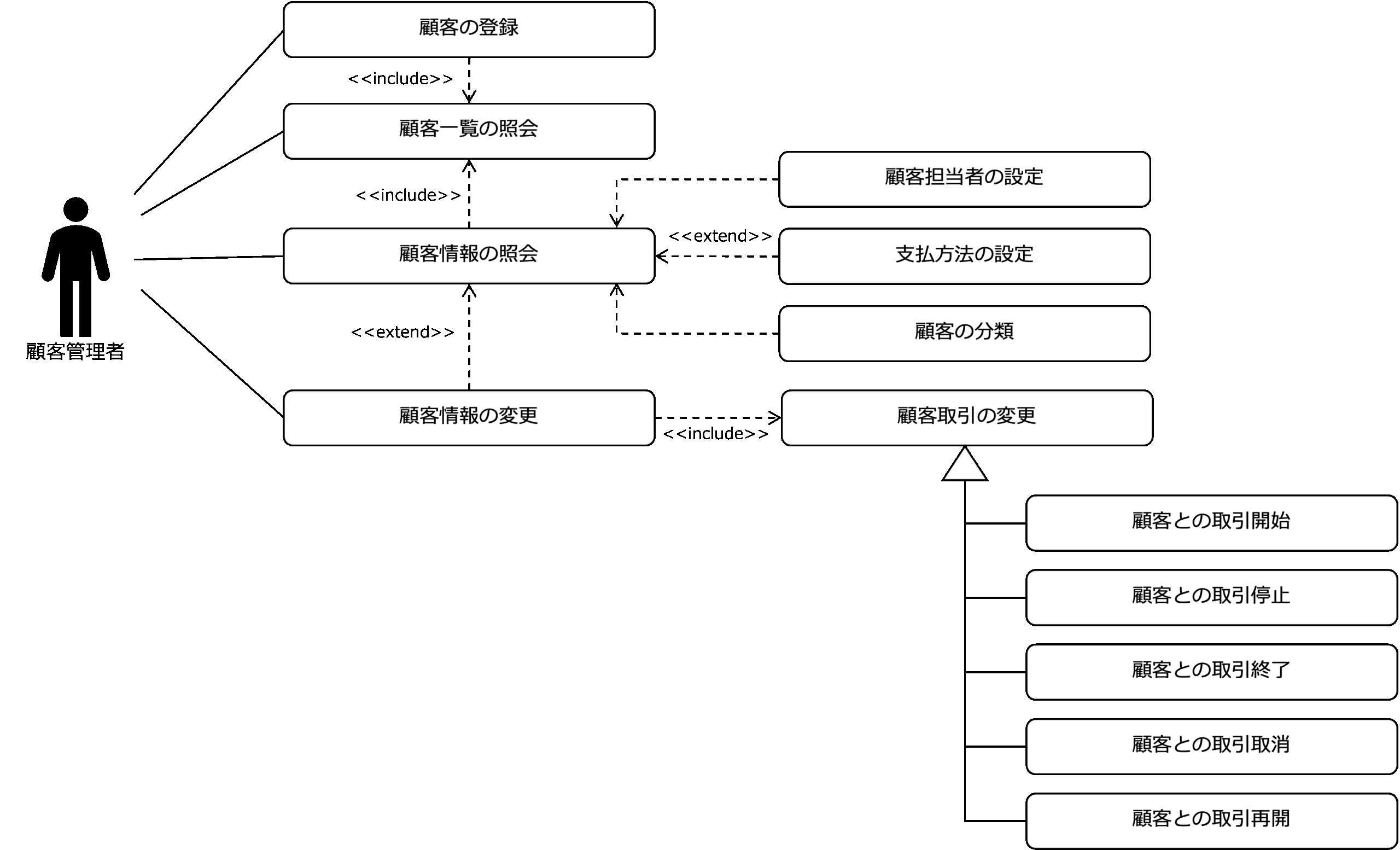
マイクロサービスは、フロントエンドアプリケーションから呼び出される側なので、このユースケースを実現する仕組として関わってきます。
画面構成
アプリケーションのユースケースが明確になると、そこから、画面の構成を導くことができます。
次の図は、顧客管理フロントエンドアプリケーションの画面構成の例です。
画面遷移
画面構成が決まると、ユースケース単位に、画面遷移を設計します。
フロントエンドアプリケーションを開発するときは、画面遷移のどのトリガーで、どのマイクロサービス(API)にアクセスするか考慮する必要があります。
次の図は、顧客情報の更新ユースケースの画面遷移図です。
この図をみると、顧客照会画面で編集を選択することで、顧客情報更新画面に遷移し、顧客情報を変更することができることがわかります。
また、顧客照会画面から顧客情報更新画面に遷移するとき、find_customer_by_customer_idを呼び出すためのキーとしてcustomer_idを渡す必要があることがわかります。
また、顧客情報を変更するとき、update_customerというAPIを呼び出し、その際、キーとしてcustomer_id、および、更新する顧客情報を渡す必要があることがわかります。
さらに、顧客情報更新画面でキャンセルすると、顧客照会画面のfind_customer_by_customer_idを呼び出すために必要なキーとしてcustomer_idを渡し、顧客照会画面に戻ることがわかります。
データ要件の定義
データアーキテクチャの一環として定義された概念データモデル、および、それに対して定義されたビジネスメタデータの要件をデータ要件とします。
ドメイン駆動設計を適用する場合、概念データモデルをドメインモデルにし、集約ルートのステートマシンを明確にします。
ドメインモデル
次の図は、顧客マスターデータの全体概念マスターデータモデルをドメインモデルに展開したものです。
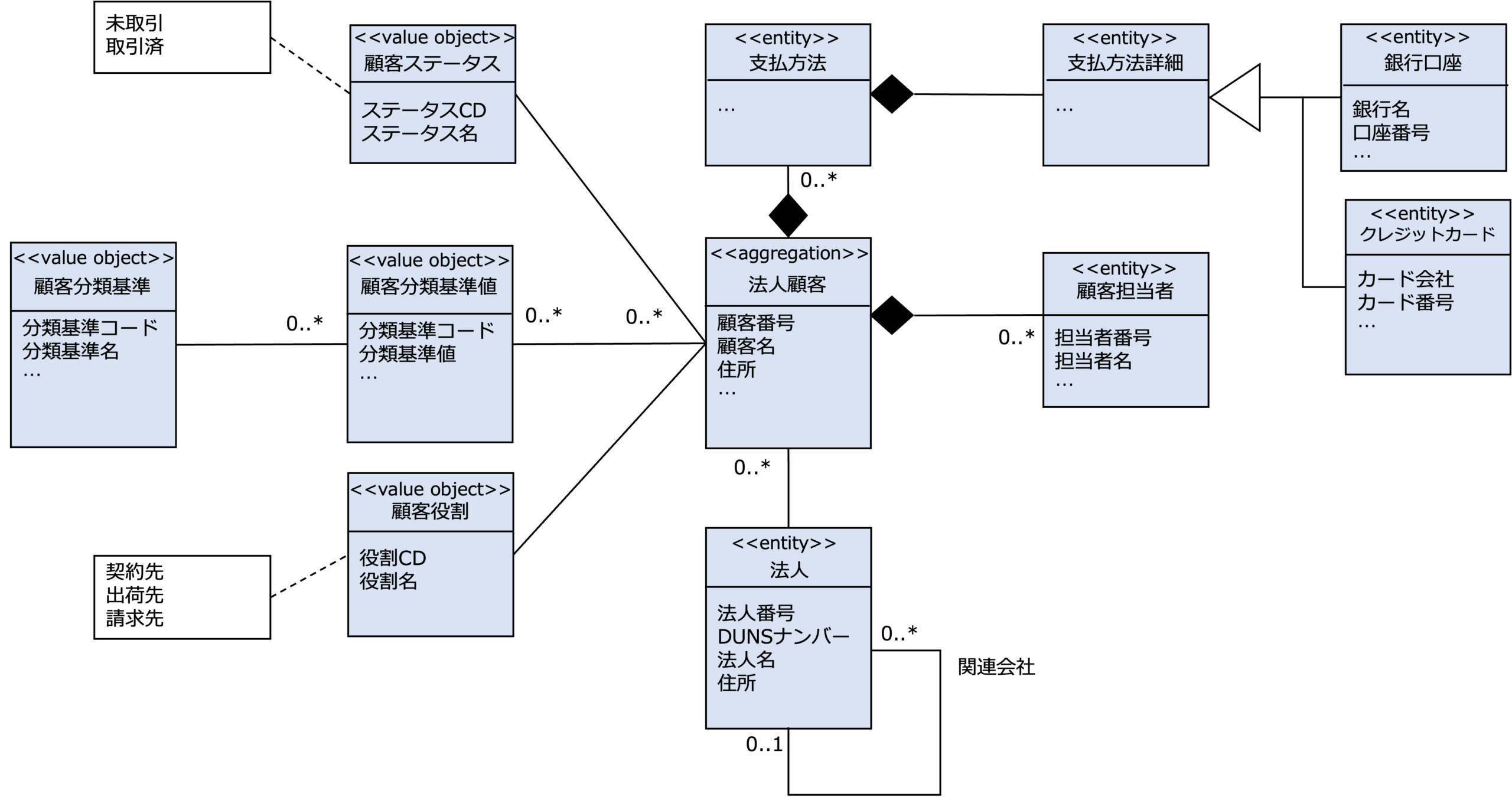
UMLのステレオタイプで「aggregation」になっている法人顧客がDDDの集約のルート、そして「entity」になっているのがエンティティ、「value object」になっているの値オブジェクトです。
エンティティと値オブジェクトの違いを、同一性、不変性、ライフサイクルという観点でまとめると次のようになります。

なので、原則不変でIDを持たない分類基準および基準値、顧客役割、顧客ステータスは値オブジェクトになっていることがわかります。
JavaのJPA場合、クラスを@Entityに指定することでエンティティを実装します。
@Entity
public class Corporate {
}
値オブジェクトの場合、次のように組込み可能クラスとして実装します。
@Embeddable
public class ClassificationCriteria {
}
組込み可能クラスは、@Entityに組み込んで適用します。
なお、列挙型は、次のように、あらかじめ定義された有限個の識別子(列挙子)だけを値として持ち、型安全を保証するための型なので値オブジェクトの実現方法としては適切ではありません。
public enum CustomerStatus {
ACTIVE,//取引中
INACTIVE,//停止中
PROSPECT,//未取引
CLOSED //取引終了
}
集約ルートのステートマシン
集約ルートのステートマシンを明確にすることで、分析の段階でドメインロジックの網羅性を担保することができます。
次の図は、法人顧客のライフサイクルを表したステートマシン(状態遷移図)です。
分析
分析では、システムのユースケースを実現する論理的な仕組を分析します。
具体的には、
- ユースケースを実現するために必要なクラスを洗い出し、
- クラス間の関係を考え(構造化)、
- そのクラス構造で本当にユースケースが実現できるか検証し、ビジネスロジック(ドメインロジックとアプリケーションロジック)を定義します。
UMLを使う場合、クラス図でクラス構造を可視化し(上図の②)、相互作用図を使って、そのオブジェクトの振舞を分析する(上図の③)ことで、クラス構造の妥当性を検証します。
ユースケースを分析するとき作成するクラス図や相互作用図を分析モデルと呼びます。
さて、ユースケースを分析するときに有効な方法の一つにロバストネス分析があります。
これは、ユースケースを実現するクラスを、バウンダリ、コントロール、エンティティという3つの役割に分け、バウンダリ→コントロール→エンティティというアクセスの流れをつくることで変化に強い(Robustな)内部構造にするという方法です。
- バウンダリ(Boundary)
ユーザーや外部システムなどシステムの外部要素と相互作用する責務を担うクラス。
外部要素がユーザの場合、画面構成のクラスを使用する。 - コントロール(Control)
画面遷移や処理で他のクラスのコントロールを担うクラス。 - エンティティ(Entity)
永続化する必要がある情報を表すクラス。ドメインモデルのクラスから選択する。
バウンダリ(Boundary)、コントロール(Control)、エンティティ(Entity)を合わせて「BCE」と言います。
次の図は、法人顧客管理システムの「顧客情報の更新」ユースケースを実現する分析モデル(クラス図)です。
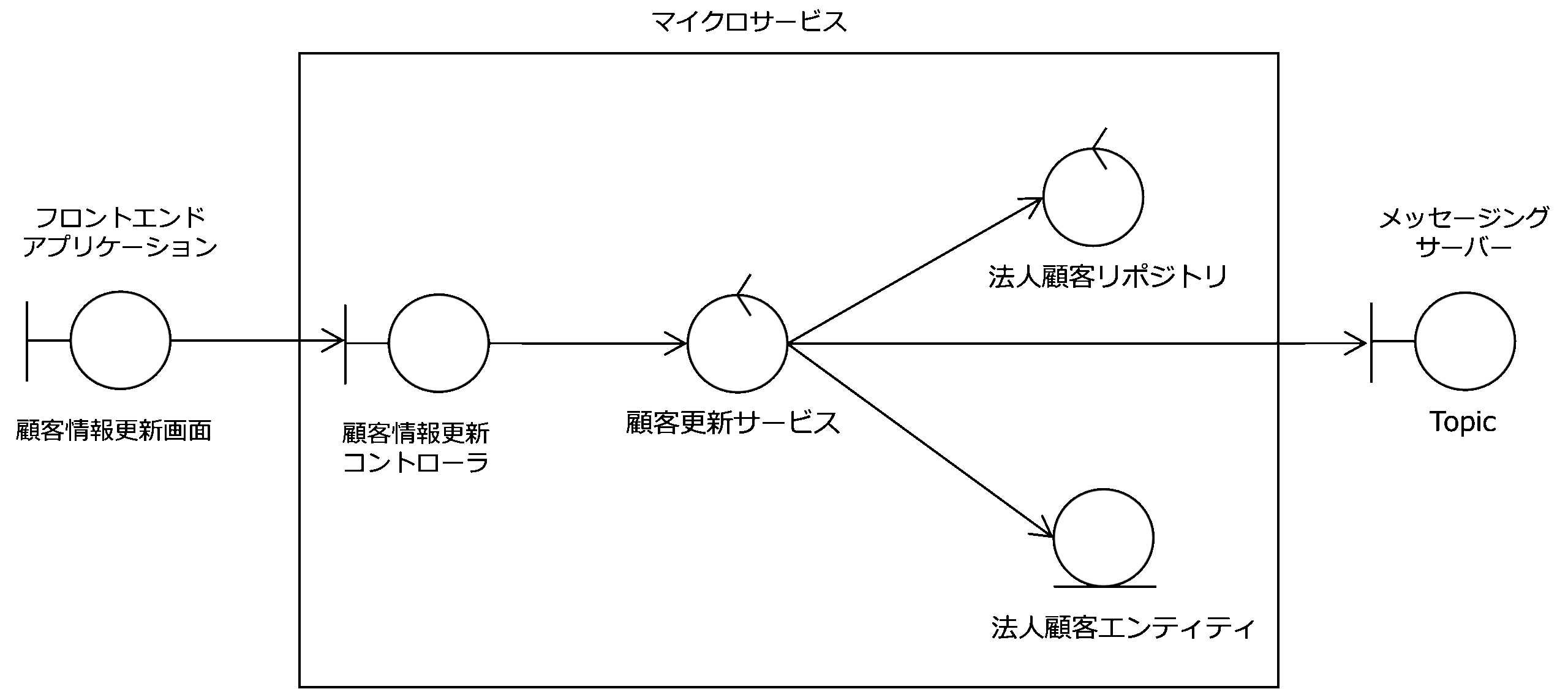
法人顧客管理システムは、フロントエンドアプリケーション、マイクロサービス、メッセージングサーバーから構成されています。
マイクロサービスをDDDで実現するため、ドメインモデルの構成要素である集約ルートである法人顧客エンティティをBCEのエンティティ、法人顧客リポジトリをデータの永続化を管理するコントロールにし、ユースケースの実現を担うドメインモデルの周辺要素として、マイクロサービスのバウンダリとしての顧客情報更新コントローラと、アプリケーションロジックを実現するコントロールとして顧客変更サービスを配置しています。
次に、これらの要素がどのように相互作用して「顧客情報の更新」ユースケースを実現するか分析モデル(シーケンス図)を描いて検証します。
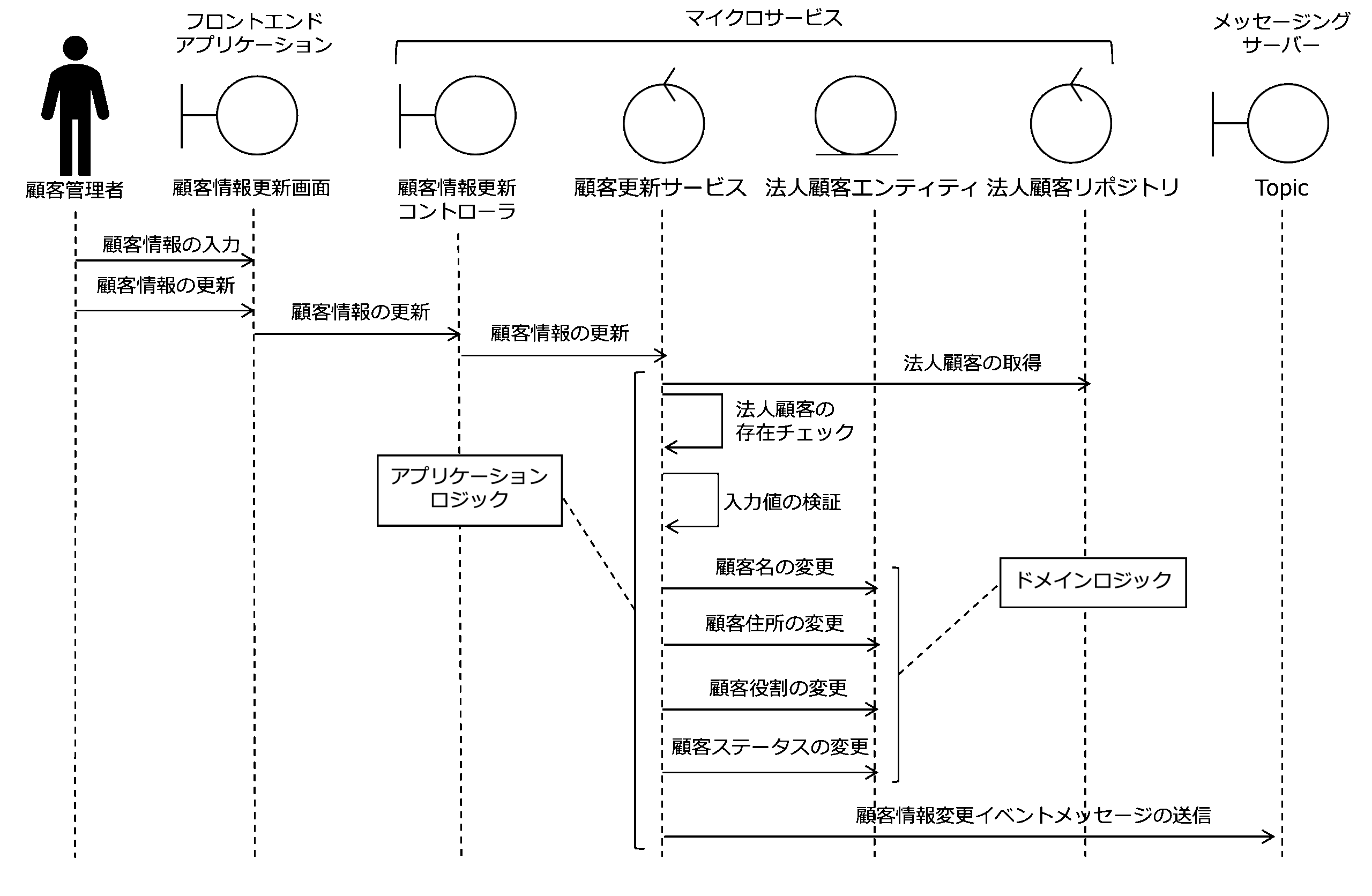
分析モデル(シーケンス図)には、顧客管理者がフロントエンドアプリケーションの顧客情報管理画面で顧客情報を入力して更新したときの流れが表されています。
これは、上述した「顧客情報の更新」ユースケースの画面遷移の「変更」トリガーで呼び出されるAPI、update_customerを実現する部分になります。
ここで重要なのが、画面遷移の[変更条件]を、サービス層のアプリケーションロジックとドメイン層のドメインロジックを分離していることです。
ドメインロジックがドメイン固有のビジネスロジックであるのに対し、アプリケーションロジックは、ユースケースを制御するためのシステムロジックです。
次の表は、ドメインロジックとアプリケーションロジックの違いを、目的、主な責務、定義する内容、主な構成要素、外部依存、例という観点で整理したものです。
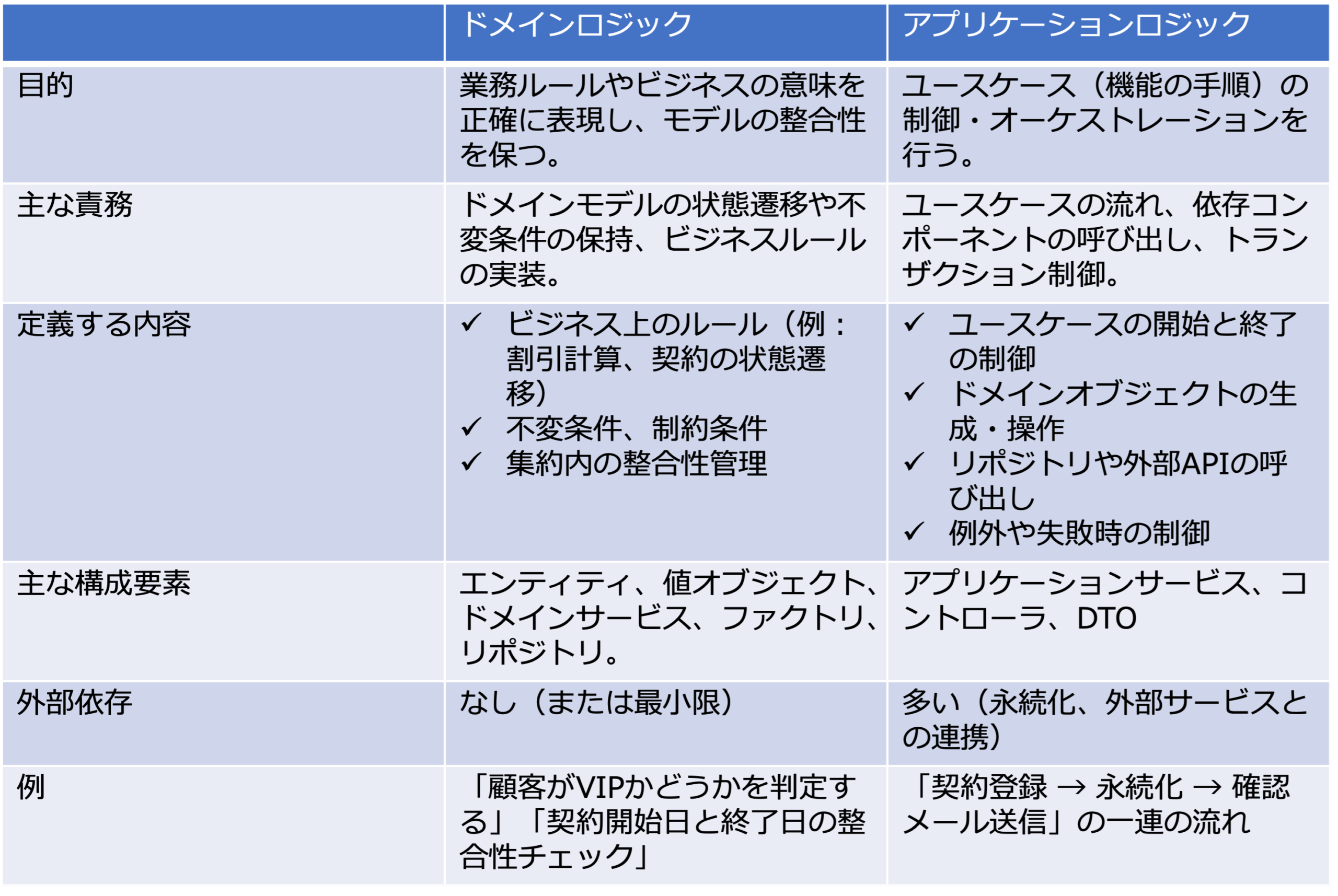
「顧客情報の更新」ユースケースの分析モデル(シーケンス図)を見ると、法人顧客エンティティの取得、および、その存在チェック、入力値の検証(バリデーション)、Topicに対する顧客情報更新イベントメッセージの送信になっています。
ちなみに、なぜTopicに対する顧客情報更新イベントメッセージを送信しているかというと、アプリケーションアーキテクチャのアプリケーション連携モデル(論理)で設計した、顧客管理サービスの顧客データが更新される都度、顧客データを必要とするマイクロサービスに、ActiveMQのTopicを介して配布(ブロードキャスト)するというイベント駆動アーキテクチャを実現するためです。
さて、「顧客情報の更新」ユースケースの分析モデル(シーケンス図)を見ると、法人顧客エンティティが実現する、顧客名の変更、顧客住所の変更、顧客役割の変更、顧客ステータスの変更がドメインロジックになっています。
ドメインロジックとは、ドメイン(開発対象の問題領域)固有のビジネスロジックで、次のような例があります。
- 業務ルール(例:契約者が未成年なら親の同意が必要)
- 計算ロジック(例:割引価格の算出ルール)
- 状態遷移(例:請求ステータスが「未払い」から「支払い済み」になる条件)
- 不変条件(例:口座残高がマイナスになってはいけない)
ドメインロジックは、ドメイン知識としてドメインモデルの中にカプセル化し、外側のサービス層に漏れないようにします。
これによって、ドメインモデルの再利用性や保守性を上げることができ、より堅牢なシステムをつくることができます。
ここでは、集約ルートの法人顧客のライフサイクルを分析することでドメインロジックを抽出してみましょう。
次の図は、法人顧客のライフサイクルを表したステートマシン(状態遷移図)です。
これをみると、次のことがわかります。
- 未登録の状態の顧客は、登録されることによって未取引の状態になり、取引開始によって取引中状態になる。
- また、取引停止によっって停止中状態になり、取引終了によって取引終了状態になる。
- それから、未登録の状態の顧客を登録することで、取引中にすることもできるし、取引中の顧客を取引終了にすることもできる。
- 逆に、取引停止中の顧客の取引を再開することもできるし、取引中の顧客の取引を取消すこともできる。
- また、未取引中と取引中の顧客のみ、顧客情報を変更することができる。
- なお、顧客情報を変更する一環として、顧客担当者と支払方法を設定することができる。
顧客担当者は、未取引中と取引中の顧客に対して設定できるが、支払方法は、取引中の顧客でないと設定することができない。
これから、上記分析モデルの顧客名、顧客住所、顧客役割、顧客ステータスの変更のにおけるドメインロジックを次のように考えることができます。
- 顧客名の変更は、顧客が未取引か取引中でなければできない。
- 顧客住所の変更は、顧客が未取引か取引中でなければできない。
- 顧客役割の変更は、顧客が未取引か取引中でなければできない。
- 顧客担当者の設定は、顧客が未取引か取引中でなければできない。
- 支払方法の設定は、顧客が取引中でなければできない。
- 未登録の場合、未取引から取引中にしか変更できない。
- 未取引の場合、取引中にしか変更できない。
- 取引中の場合、停止中、取引終了、未取引にしか変更できない。
- 停止中の場合、取引終了、取引中にしか変更できない。
- 取引終了の場合、ステータスの変更はできない。
これらのドメインロジックは、通常、集約ルートである法人顧客エンティティのメソッドとして実装してカプセル化します。
設計
分析では、BCEを適用してユースケースを実現する論理的な仕組を分析しましたが、設計では、分析モデルを物理的な仕組に展開します。
設計するときは、論理的な仕組を実現するIT基盤(特にミドルウェア)として、非機能要件を満たすためのデータベース管理システム(DBMS)、Webサーバー、アプリケーションサーバー、プログラム言語、アプリケーションフレームワークなどの構成を考えます。
例えば、アプリケーションフレームワークとしてSpringフレームワークを適用する場合、BCEのエンティティは@Entity、アプリケーションサービスは@Serivice、リポジトリはJpaRepositoryなどとして実装されます。
@Entity
public class CorporateCustomer
@Service
public class CustomerUpdateService
public interface CorporateCustomerJpaDataRepository extends JpaRepository
それから、設計の一環として、非機能要件などシステムに求められる要件を解決するための汎用的な機構(汎用メカニズム)を考えます。
ここでは、法人顧客エンティティが実現すべく「顧客ステータスの変更」ロジック
- 未登録の場合、未取引から取引中にしか変更できない。
- 未取引の場合、取引中にしか変更できない。
- 取引中の場合、停止中、取引終了、未取引にしか変更できない。
- 停止中の場合、取引終了、取引中にしか変更できない。
- 取引終了の場合、ステータスの変更はできない。
をステートパターンというデザインパターンを使って実現する例を紹介します。
次の図は、クラス図を使って、法人顧客エンティティが「顧客ステータスの変更」を実施するときのメカニズムを表しています。
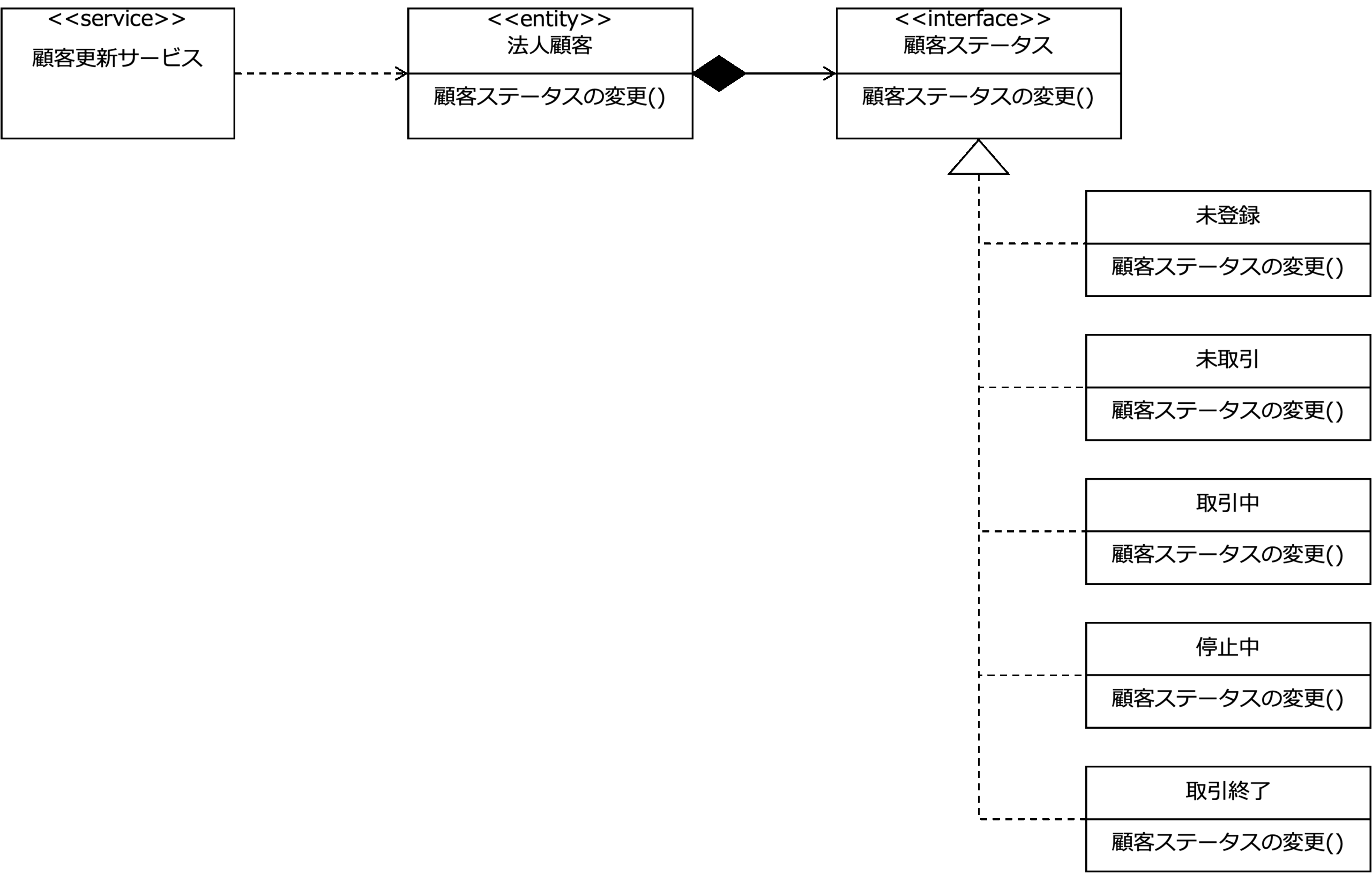
これを見ると、顧客更新サービスが、法人顧客エンティティが「顧客ステータスの変更」を依頼すると、法人顧客エンティティは、それが持つ顧客スタータスに処理を委譲していることがわかります。
ここで、顧客スタータスは、「顧客ステータスの変更」の仕様を定義しただけのインターフェースで、実際の処理は、顧客スタータスを実現する「未登録」、「未取引」、「取引中」、「停止中」、「取引終了」という状態を表すクラス(状態オブジェクト)です。
このようにインターフェースと、その実装部分を分離することで、相手に公開するインターフェスは変えずに実装部分を自由に交換することができるようになりシステムの生産性や保守性を高めることができます。
この場合、「未登録」、「未取引」、「取引中」、「停止中」、「取引終了」クラスの実装方法を変更しても、新しい状態クラスを追加しても顧客スタータスというインターフェスを利用する法人顧客エンティティは影響を受けません。
具体的には、法人顧客エンティティは次の例のように実装すれば、内部処理の変更や状態クラスの追加があっても、この部分を変える必要はないのです。
public void changeStatus(CustomerStatus newStatus) {
CustomerStatusState state = CustomerStatusStateFactory.getState(this.status);
state.changeStatus(this, newStatus);// 状態オブジェクトに委譲
}
実装
設計まで終われば、生成AIにソースコードを生成させて設計結果を実装します。
次の表は、生成AIをつかって実装するときの代表的ツールを、特徴、主な用途、対応IDE・環境という観点で整理したものです。

ここでは、JavaSpringフレームワークでアプリケーションを実装する上で考慮すべきポイントについてまとめます。
インフラ層の実装ポイント
SecurityConfig対応
@Configuration + @EnableWebSecurity + WebSecurityConfigurerAdapterを拡張したSecurityConfigを作成し、次の構成を実装します。
- CORS(クロスオリジン)設定
CORS(Cross-Origin Resource Sharing、オリジン間リソース共有)とは、異なるオリジン(プロトコル + ドメイン + ポート番号 の組み合わせ)間でのリソース共有を許可する仕組みのことです。
例えば、次の2つの異なるオリジンがあります。
・http://localhost:3000 → オリジンA
・http://162.14.223.11:1000 → オリジンB
ブラウザは 同一オリジンポリシー(Same-Origin Policy) に従っており、通常はオリジンAからオリジンBのAPIを呼べません。
そこで CORSをサーバー側で設定して、特定オリジンからのアクセスを許可できるようにします。
http.cors() と @Bean CorsFilter によって、どのフロントエンドからアクセスを許可するか(例:localhost:3000 など)、どのメソッド、どのヘッダーを許可するか認証付き(credentials=true)かどうかを指定できます。
これは “フロントエンドとの安全な接続(クロスドメイン)” を実現するための設定です。 - 認証フィルター(AuthFilter)の登録
addFilterBefore(authFilter, UsernamePasswordAuthenticationFilter.class) によって、独自のフィルター(JWT検証など)を Spring Security のフィルターチェーンに組み込みコントローラーに届く前に 認証・認可処理を行えるように します。
これは “誰がアクセスしているかを検証するための仕組み(セキュリティの中核)” です。
ドメイン層の実装ポイント
- 楽観ロック対応
楽観ロック(Optimistic Locking)とは、同時に複数のトランザクションが同じデータを更新しようとしたときの整合性を保つための手法です。
楽観ロックを実現するためには、集約ルート(対応するテーブル)に、@Versionを設定する必要があります。
@Entity
public class Product {
@Id
private Long id;private String name;
@Version
private Long version; // ← 楽観ロック用のバージョンフィールド
}
その上で、サービス層で、次のように制御します。
@Transactional
public void updateCustomer(CorporateCustomer customer) {
try {
customerRepository.save(customer);
//同時更新時の例外
} catch (OptimisticLockException e) {
throw new BusinessException(“Concurrent update error”, e);
}
} - データマネジメント対応
ここでは、監査すべきエンティティの作成日時・更新日時・作成者・更新者などの情報を自動的に記録・管理するためのデータマネジメント手法について説明します。- Auditableを定義する
@MappedSuperclass
@EntityListeners(AuditingEntityListener.class)
public abstract class Auditable {@CreatedDate
@Column(updatable = false)
private LocalDateTime createdAt;@LastModifiedDate
private LocalDateTime updatedAt;// 必要に応じて追加
// @CreatedBy
// private String createdBy;// @LastModifiedBy
// private String updatedBy;public LocalDateTime getCreatedAt() {
return createdAt;
}public LocalDateTime getUpdatedAt() {
return updatedAt;
}
} - @EnableJpaAuditingを定義して監査機能(Auditing)を有効化する
@SpringBootApplication
@EnableJpaAuditing
public class CorporateCustomerApplication {
public static void main(String[] args) {
SpringApplication.run(CorporateCustomerApplication.class, args);
}
}
@EnableJpaAuditingは、Spring Data JPA における監査機能(Auditing)を有効化するアノテーションです。
これを付けることで、以下のような注釈をエンティティに付けたときに、Spring が自動的にその値を設定・更新してくれるようになります。- @CreatedDate: 作成日時を自動セット
- @LastModifiedDate: 最終更新日時を自動セット
- @CreatedBy: 作成者(ユーザー名など)を自動セット(※別途 AuditorAware が必要)
- @LastModifiedBy: 最終更新者を自動セット(※同上)
- データマネジメントが必要なエンティティをAuditableで拡張する
@Entity
public class CorporateCustomer extends Auditable {
@Id
private String customerNumber;private String customerName;
// その他のフィールド
}
- Auditableを定義する
- ページネーションの実現
ページネーション(Pagination:ページ分割)とは、データやコンテンツが大量にある場合に、それを複数の「ページ」に分割して表示する仕組みのことです。
Spring Data JPAのPageとPageableは、ページネーションを行うための便利な仕組みです。
Pageは、ページごとの検索結果を表すクラスです。
また、Pageable は、ページネーションの条件を表すインターフェースで、次のような情報を持ちます。- ページ番号(0から始まる)
- 1ページの件数(ページサイズ)
- ソート条件(必要に応じて)
JPAリポジトリで、次にように検索インターフェースを定義します。
PagesearchCustomerWithCorporateDetailsPaged(
@Param(“customerName”) String customerName,
@Param(“role”) CustomerRole role,
@Param(“status”) CustomerStatus status,
@Param(“corporateName”) String corporateName,
@Param(“corporateNumber”) String corporateNumber,
@Param(“dunsNumber”) String dunsNumber,
Pageable pageable
);
それを受けてコントローラでページ単位の検索結果を返します。
@GetMapping(“/search-paged”)
public ResponseEntity
@RequestParam(required = false) String customerName,
@RequestParam(required = false) CustomerRole role,
@RequestParam(required = false) CustomerStatus status,
@RequestParam(required = false) String corporateName,
@RequestParam(required = false) String corporateNumber,
@RequestParam(required = false) String dunsNumber,
Pageable pageable
) {
Pageresult = customerQueryService.searchCustomerWithCorporateDetailsPaged(
customerName, role, status, corporateName, corporateNumber, dunsNumber, pageable
);
return ResponseEntity.ok(result);
}
}
サービス層の実装ポイント
イベント駆動アーキテクチャの実現
次のように、JMS(Java Message Service)を使ってイベント駆動アーキテクチャ(EDA: Event-Driven Architecture)を実現します。
- JMSプロバイダ(ブローカー)の導入と設定
- ActiveMQやRabbitMQなどのJMSブローカーを導入
- QueueやTopicの作成
- 永続化(Persistence)や再送、TTL(Time-To-Live:メッセージの有効期限)、DLQ(Dead Letter Queue:処理に失敗したメッセージを隔離して保存する特別なキュー)などの設定
- JmsConfitの定義
アプリケーション(クライアント側)から ActiveMQなどのメッセージングサーバーとやり取りするための設定をします。
configパッケージに、
@Configuration
@EnableJms
public class JmsConfig
を定義します。 - ドメインイベントの定義
xx.domain.eventにドメインイベントを定義します。
例
/**
* 個人情報が更新されたことを表すドメインイベント
*/
@Getter
@AllArgsConstructor
public class PersonUpdated implements Serializable {/**
*
*/
private static final long serialVersionUID = 1L;private final String personId;
private final String firstName;
private final String middleName;
private final String lastName;private final String zipcode;
private final String country;
private final String state;
private final String city;
private final String street;private final String birthDate; // ISO形式文字列で表現(LocalDateはDTOに直接使いにくい)
private final String phoneNumber;
private final String emailAddress;}
- メッセージ(DTO)の定義
xx.adapter.messagingにドメインイベントを定義します。
冪等性を確保するためmessageIdを設けるようにします。
コンシューマ側で以下のように、冪等性を確保するロジックを設ける必要があります。
if (messageLogRepository.existsByMessageId(message.getMessageId())) {
return; // すでに処理済み → スキップ
}
メッセージ(DTO)の例
/**
* JMS送信用の個人情報更新イベントDTO
*/
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class PersonUpdatedEventMessage implements Serializable {private static final long serialVersionUID = 1L;
private String messageId; // ✅ 追加:メッセージの一意識別子
private String personId;
private String firstName;
private String middleName;
private String lastName;private String zipcode;
private String country;
private String state;
private String city;
private String street;private String birthDate;
private String phoneNumber;
private String emailAddress;public static PersonUpdatedEventMessage from(com.culnou.person.domain.event.PersonUpdated event) {
return new PersonUpdatedEventMessage(
UUID.randomUUID().toString(), // ✅ messageIdをここで生成
event.getPersonId(),
event.getFirstName(),
event.getMiddleName(),
event.getLastName(),
event.getZipcode(),
event.getCountry(),
event.getState(),
event.getCity(),
event.getStreet(),
event.getBirthDate(),
event.getPhoneNumber(),
event.getEmailAddress()
);
}
} - プロデューサー(イベント発行者)の実装
例
@Service
@RequiredArgsConstructor
public class OrderEventSender {private final JmsTemplate jmsTemplate;
public void sendOrderCreatedEvent(OrderCreatedEvent event) {
jmsTemplate.convertAndSend(“order.created.topic”, event);
}
} - コンシューマー(イベントリスナー)の実装
@Component
public class OrderEventReceiver {@JmsListener(destination = “order.created.topic”, containerFactory = “jmsListenerContainerFactory”)
public void onOrderCreated(OrderCreatedEvent event) {
// 受け取ったイベントに対する処理
}
} - アプリケーションサービスでイベント発行を呼び出す
プレゼンテーション層の実装ポイント
- OpenAPI対応
OpenAPIとは、「OpenAPI Specification(OAS)」の略称で、主にRESTful Web APIのエンドポイント、リクエスト、レスポンス、パラメータ、認証方式などを、機械可読かつ人間にも理解しやすいフォーマット(通常はYAMLまたはJSON)で記述するための標準仕様です。
主な活用方法は以下です。- API確認
どんなエンドポイントがあるか、パラメータやレスポンスの形式を確認できる。 - 開発者間連携
フロントエンドや外部開発者に仕様を共有しやすくなる(URL共有でOK)。 - 手動テスト
実際のパラメータを入力して、APIの動作を手軽に試せる。 - 仕様書生成
Swagger UI画面から OpenAPI JSON をエクスポートして仕様書として活用可能。
http://localhost:1000/swagger-ui.html
http://localhost:1000/v3/api-docs - コード生成
OpenAPI Generator を使って、クライアントSDKやサーバスタブを自動生成可能。
@Configurationを定義することでOpenAPIに対応させます。
@Configuration
public class OpenApiConfig {@Bean
public GroupedOpenApi publicApi() {
return GroupedOpenApi.builder()
.group(“public-api”)
.packagesToScan(“com.culnou”) // スキャン対象のパッケージ
.build();
}
}
@RestControllerに次のような定義を設定することでAPIを仕様化することができます。- @OpenAPIDefinition
全体の定義(タイトル、バージョン、サーバーなど) - @Tag
APIグループの定義 - @Operation
各エンドポイントの要約と説明 - @Parameter
パス、クエリ、ヘッダーパラメータの説明 - @RequestBody
リクエストボディの説明 - @ApiResponse
レスポンスの説明
例
@Tag(name = “法人顧客登録API”, description = “法人顧客の新規登録や情報取得のためのAPI群”)
@RestController
@RequestMapping(“/corporate_customers”)
@RequiredArgsConstructor
public class CorporateCustomerController {@Operation(summary = “法人顧客の新規登録”, description = “新しい法人顧客を登録します”)
@PostMapping
public ResponseEntityregisterCorporateCustomer(@RequestBody CorporateCustomerDto dto) {
// 実装
return ResponseEntity.ok().build();
}@Operation(summary = “法人顧客の取得”, description = “顧客IDをもとに法人顧客情報を取得します”)
@GetMapping(“/{customerId}”)
public ResponseEntitygetCustomer(@PathVariable String customerId) {
// 実装
return ResponseEntity.ok(/* customerDto */);
}
} - API確認
- エラーハンドリング
Spring Bootで@ControllerAdviceを使ったエラーハンドリングを行うと、アプリケーション全体の例外処理を一元化できます。
具体的には、Spring Bootでは、次の流れで自動的に例外を発生させます。- HTTPリクエスト
- DispatcherServlet
- Controllerメソッド呼び出し
- Exception発生!
- DispatcherServletがキャッチ
- @ExceptionHandlerのあるメソッドを探索
- ControllerAdviceが見つかる
- GlobalExceptionHandlerの処理が実行される
- ResponseEntityを返す(HTTPレスポンス生成)
具体的な実装は次の手順で行います。
- 共通のエラーレスポンスDTOを定義する
実装例
@Data
@AllArgsConstructor
@NoArgsConstructor←相手側でJSONパースできなくなるのでデフォルトコンストラクタを設定する。
public class ErrorResponse {
private String errorCode;
private String message;public ErrorResponse(String errorCode, String message) {
this.errorCode = errorCode;
this.message = message;
}// Getter・Setterを必要に応じて追加
} - 共通の例外ハンドラを作成する
実装例
@ControllerAdvice
public class GlobalExceptionHandler {// 一般的な予期しない例外
@ExceptionHandler(Exception.class)
public ResponseEntityhandleException(Exception ex) {
return ResponseEntity
.status(HttpStatus.INTERNAL_SERVER_ERROR)
.body(new ErrorResponse(“INTERNAL_ERROR”, “Unexpected error occurred.”));
}// 業務例外(独自に定義したBusinessExceptionなど)
@ExceptionHandler(BusinessException.class)
public ResponseEntityhandleBusinessException(BusinessException ex) {
return ResponseEntity
.status(HttpStatus.BAD_REQUEST)
.body(new ErrorResponse(“BUSINESS_ERROR”, ex.getMessage()));
}//ドメイン例外(ドメイン層)
@ExceptionHandler(DomainException.class)
public ResponseEntityhandleDomainException(DomainException ex) {
Locale locale = LocaleContextHolder.getLocale();
String message = messageSource.getMessage(ex.getMessage(), ex.getArgs(), ex.getMessage(), locale);
HttpStatus status = HttpStatus.UNPROCESSABLE_ENTITY;
return ResponseEntity.status(status)
.body(new ErrorResponse(“DOMAIN_ERROR”, message, status.value()));
}// バリデーションエラー(例:@Validでのエラー)
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResponseEntityhandleValidationException(MethodArgumentNotValidException ex) {
String errorMessage = ex.getBindingResult().getFieldErrors()
.stream().findFirst()
.map(fieldError -> fieldError.getDefaultMessage())
.orElse(“Validation failed”);
return ResponseEntity
.status(HttpStatus.BAD_REQUEST)
.body(new ErrorResponse(“VALIDATION_ERROR”, errorMessage));
}// DBの制約違反など
@ExceptionHandler(DataIntegrityViolationException.class)
public ResponseEntityhandleDataIntegrityViolation(DataIntegrityViolationException ex) {
return ResponseEntity
.status(HttpStatus.CONFLICT)
.body(new ErrorResponse(“DATA_INTEGRITY_ERROR”, “Duplicate or invalid data.”));
}
} - 必要に応じて独自例外を定義する
実装例
アプリケーションロジックの例外
public class BusinessException extends RuntimeException {
public BusinessException(String message) {
super(message);
}
}
ドメインロジックに対する例外
public class DomainException extends RuntimeException {
public DomainException(String messageCode, Object… args) {
super(messageCode);
}
} - 例外を発生させる処理に組み込む
実装例
if (someBusinessRuleFails) {
throw new BusinessException(“この操作は許可されていません。”);
}
- エラーメッセージの国際化
Spring Bootで メッセージの国際化(i18n)を実現する手順を以下です。- プロパティファイルを用意する
src/main/resources に以下のようにメッセージリソースファイルを作成します。
# messages.properties(デフォルト)
greeting=Hello!
# messages_ja.properties(日本語)
greeting=こんにちは! - メッセージの構成を決める
@Configuration
public class MessageConfig {
@Bean
public MessageSource messageSource() {
ResourceBundleMessageSource source = new ResourceBundleMessageSource();
source.setBasename(“messages”); // プレフィックス(ファイル名共通部分)
source.setDefaultEncoding(“UTF-8”);
source.setFallbackToSystemLocale(false); // ロケールが見つからない場合、デフォルトにフォールバックしない
return source;
}
//// Accept-Language ヘッダーでロケールを判定
@Bean
public LocaleResolver localeResolver() {
AcceptHeaderLocaleResolver resolver = new AcceptHeaderLocaleResolver();
resolver.setDefaultLocale(Locale.JAPAN); // ← ヘッダーがない場合のフォールバック先
return resolver;
}
}
LocaleResolver は、HTTPリクエストからロケール(言語・地域情報)を解決(決定)するためのインターフェースです。 - コントローラーなどで使用する
@RestController
public class GreetingController {@Autowired
private MessageSource messageSource;@GetMapping(“/greet”)
public String greet() {
return messageSource.getMessage(“greeting”, null, LocaleContextHolder.getLocale());
}
}
LocaleContextHolder は、現在のリクエストスレッドのロケールを取得・設定するためのクラスです。
LocaleContextHolder.getLocale()は現在のリクエストに紐づくロケール(Accept-Language ヘッダーや SessionLocaleResolver 等から決定されたもの)を返します。
- プロパティファイルを用意する
フロントエンドアプリケーションの開発
ここでは、マイクロサービスのAPIと、ノーコードプラットフォームを活用してフロントエンドアプリケーションを開発する方法について説明します。
次の表は、非エンジニアでも「API連携でアプリをすぐ作れる」代表的ツールを、特徴、API連携のしやすさ、向いてる用途という観点で整理したものです。
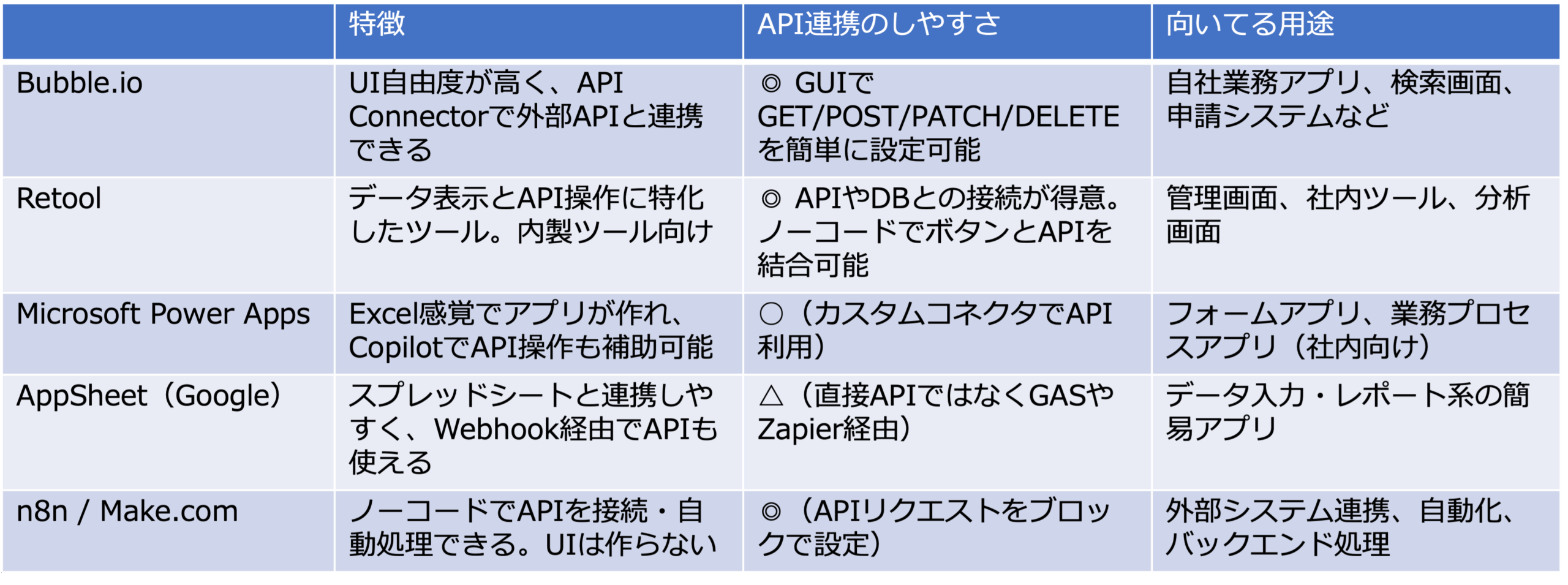
この中で、社内向けアプリだけでなく、顧客向けのサービスも開発できるものはBubble.ioです。
さらに、Bubbleは生成AIを活用した開発も可能で、例えば、次のようなチャットボットの開発実績もあります。
- ChatGPTを組み込んだカスタマーサポートボット
ユーザーからの問い合わせを受け付け、OpenAI APIに送信し、回答を返す。 - 商品レコメンドBot
質問形式でユーザーのニーズを聞き出し、ECサイトの商品をレコメンド。 - 学習支援Bot
中学生〜大学生向けに、自然言語で質問に答える学習アシスタント。
ここでは、Bubble.ioを使って、非エンジニアがAPI連携でアプリを開発する手順を説明します。
Bubble.ioを使ってAPI連携でアプリを開発する手順は次のようになります。
- API Connector設定
- オプションセットの定義(必要に応じて)
- UI構造の設計
- カスタムステートの定義(必要に応じて)
- データのバインド
- UIワークフローの設計
API Connector設定
REST APIの仕様を確認し、エンドポイント、メソッド(GET/POSTなど)、認証、パラメータなどをAPI Connectorで設定します。
その際、「Initialize Call」でレスポンスの構造を取得して、Bubble内のデータ型に自動マッピングさせます。
実装段階で、OpenAPIを適用してAPIを定義しておくと便利です。
APIの使用方法にはActionとDataがあります。
Action
- 使い所
ワークフローでAPIを呼び出したいとき(ユーザーの操作に応じて実行する処理) - 主な用途:
データの作成(POST)
データの更新(PUT、PATCH)
データの削除(DELETE)
認証付きのAPI呼び出し(トークンをセットしてPOSTするなど) - 特徴
ワークフローの「Action」ステップとして利用可能。
結果をカスタムステートやデータに保存可能。
GETでも使用可能だが、レスポンスを直接画面にバインドできない。
Data
- 使い所
画面上にAPIからのデータを表示したいとき(Repeating Groupなどにバインド) - 主な用途:
データの取得(GET) - 特徴
APIのレスポンスをRepeating GroupやTextなどのUI要素に 直接バインド可能。
自動的にキャッシュされ、ページロード時に取得できる。
ワークフローでは基本的に使用しない(手動呼び出しできない)。
それから、パスパラメータとクエリパラメータでは設定の方法が異なります。
- パスパラメータを設定する場合
[パラメータ]でURLに指定する。
http://your.comain/corporate_customers/with-corporate/by-customer-id/[customerId]
URL parametersを指定する。 - クエリパラメータを設定する場合
Parametersに、クエリパラメータを追加する。
オプションセットの定義(必要に応じて)
ステータスや区分など参照データ、あるいは、列挙型になるものをオプションセットとして定義します。
これはUIコンポーネント(Dropdownなど)との連携に使います。
列挙型になる値オブジェクトを実装する場合、それをオプションセットとして定義します。
UI構造の設計
ページとコンポーネント(RepeatingGroup、Group、Input、Textなど)を構造化して配置します。
各UIコンポーネントの配置(Layout)、外観(Appearance)、条件付き外観変更(Conditional)を設定します。
また、下図は、ドロップリストに表示させる条件を設けて値をフィルタリングしている例です。
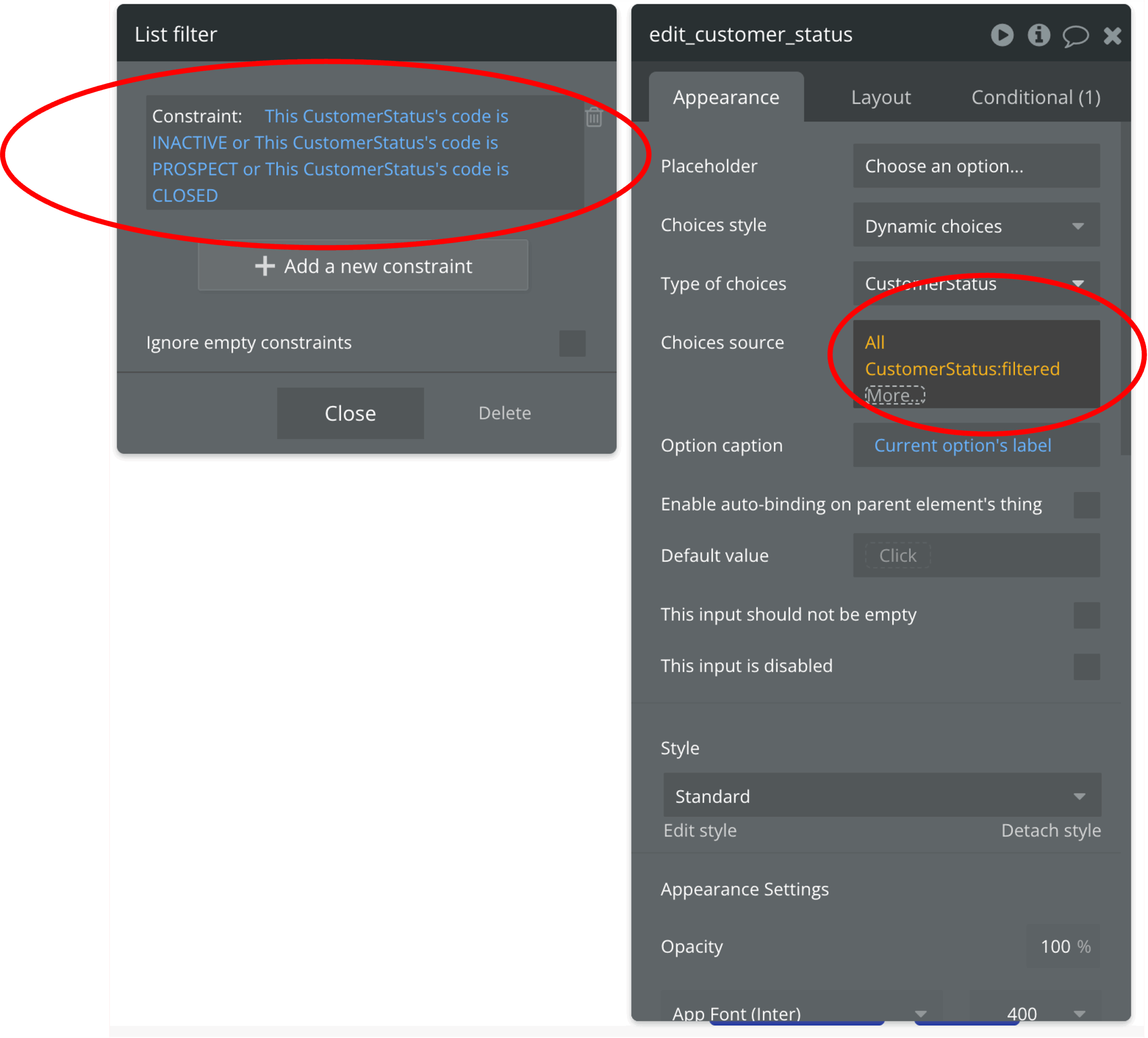
さらに、下図のように、条件付き外観変更(Conditional)で、ドロップダウンリストを表示させる条件を設定することもできます。
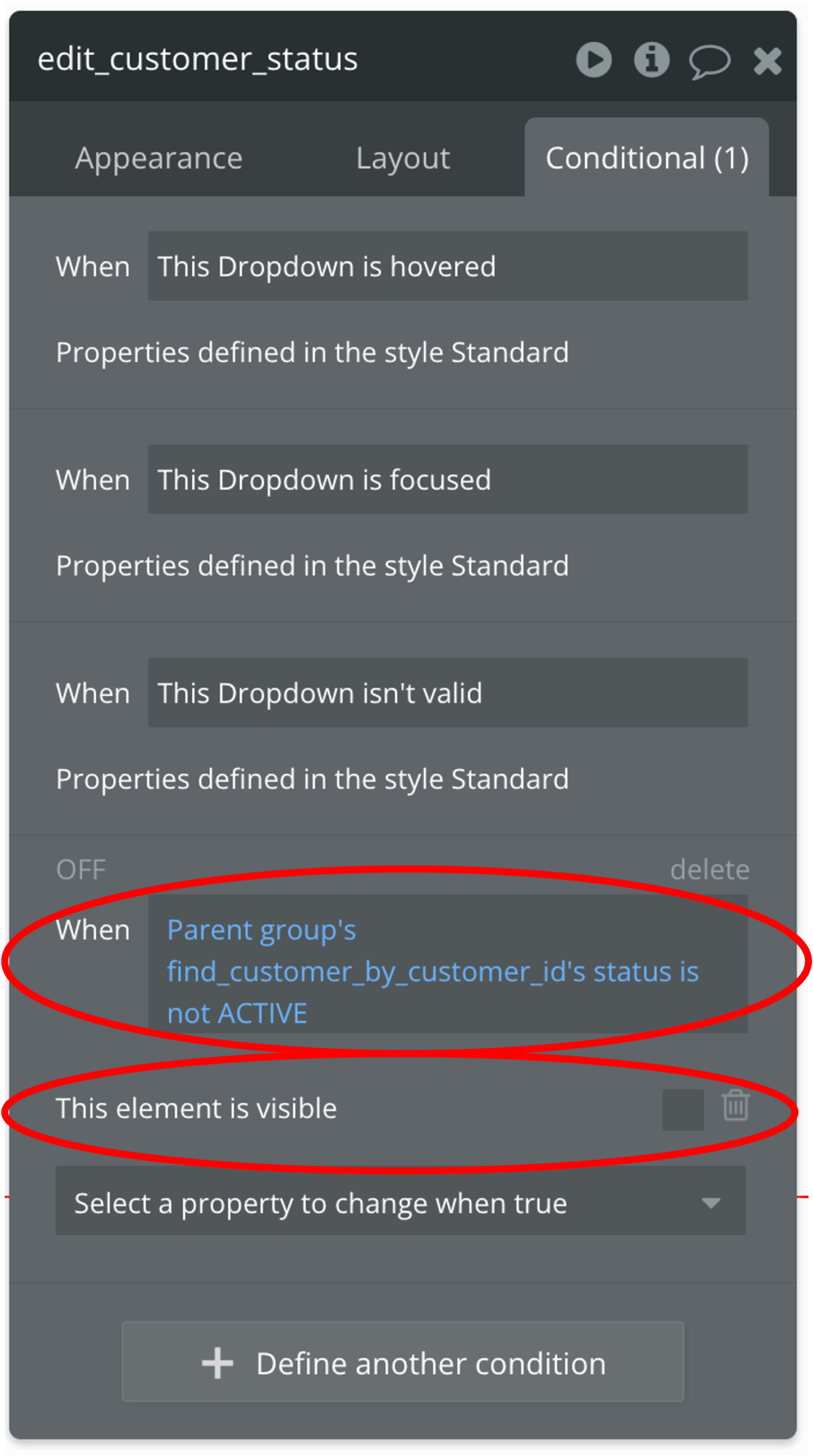
カスタムステートの定義(必要に応じて)
ページ内で状態を保持するための一時変数として設定(例:現在の検索条件、選択中の顧客など)。
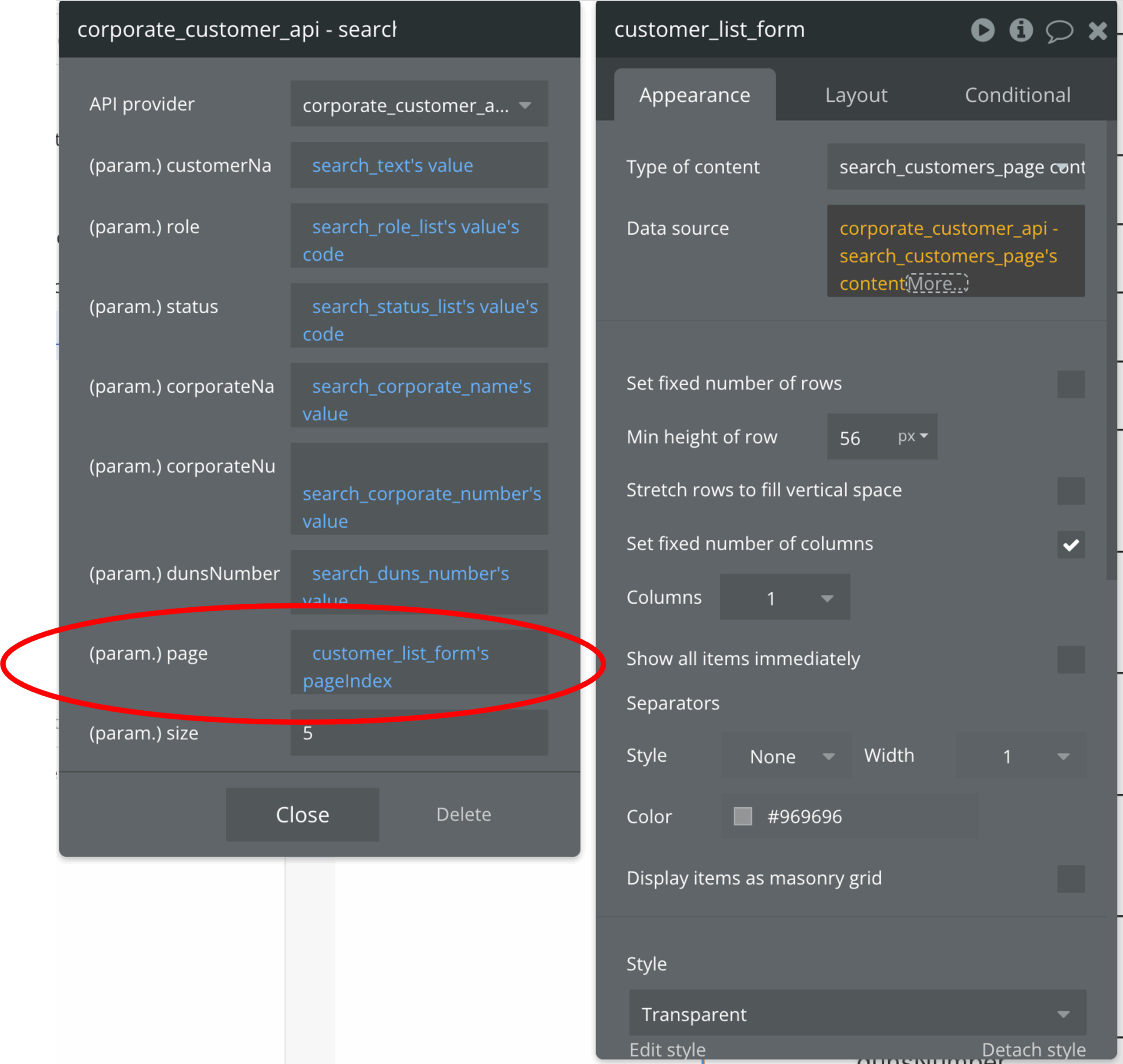
例えば、ページネーションを実現したい場合、カスタムステートにページ番号(この例ではpageIndex)を定義し、それを利用してページを進めます。
下の図は、RepeatingGroupにデータをバインド(後述)している例ですが、pageというAPIのクエリパラメータにpageIndexというカスタムステートを指定しています。
また、下図は、画面のNEXTボタンを押下したとき、pageIndexをインクリメントする設定をしています。
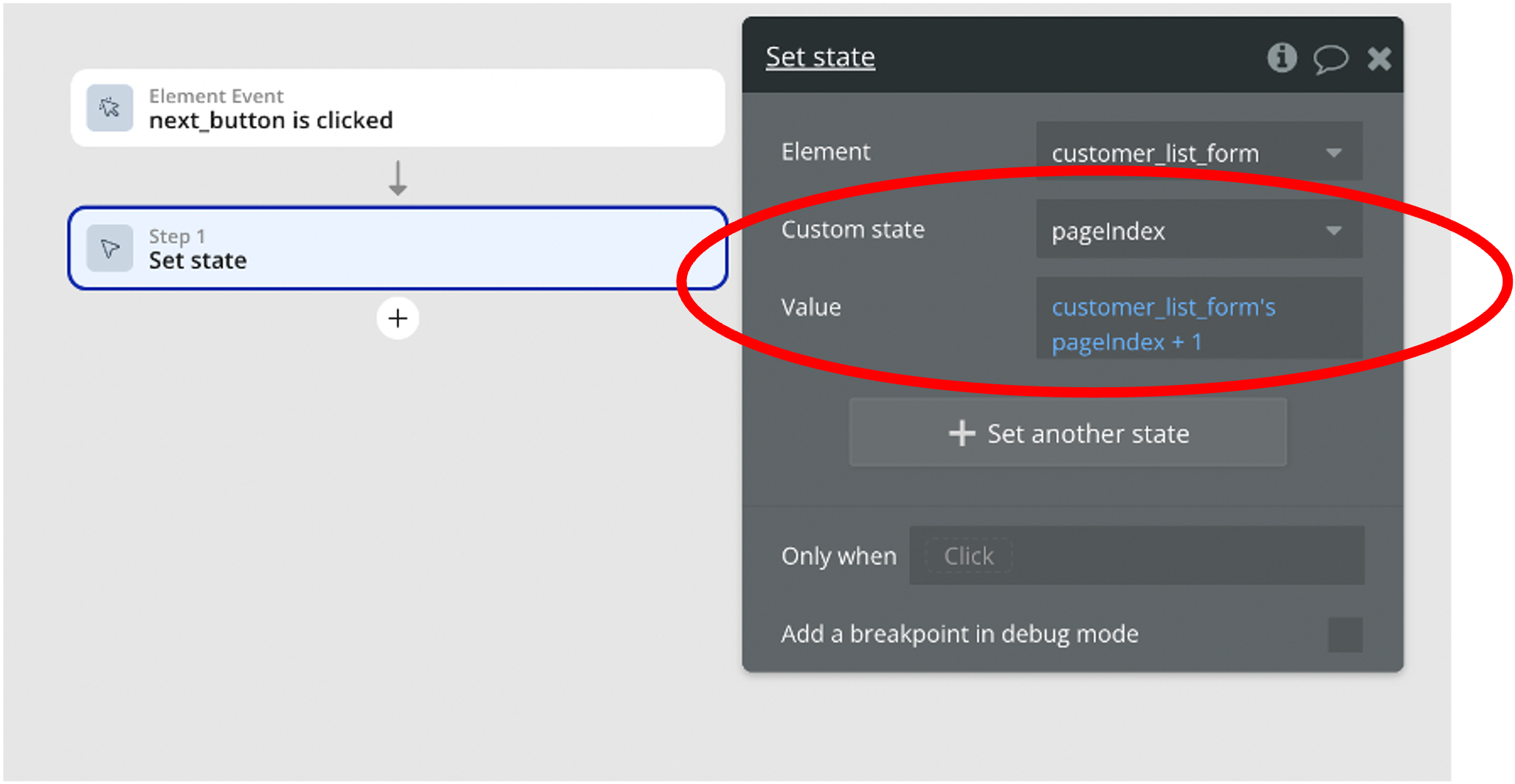
これによって、最新のページ番号が動的に変わり、APIに最新のページ番号とページ数を指定することでデータを取得することができるようになります。
データのバインド
UIコンポーネント(RepeatingGroup、Textなど)に、APIレスポンスやカスタムステートをバインドします(データソース指定)。
データをバインドするときは、Type of contentとData Sourceを設定します。
Type of content
- そのページまたはグループが扱う「データ型(構造)」の指定
- ページ(Page)、グループ(Group)、Reusable Elementで使う
- APIのデータ型を指定することもできる
- Bubbleでは、API Connectorで初期化(Initialize Call)した際に、APIレスポンスの構造から自動的にAPI xxx のような「外部データ型」が内部的に生成される。
API Customer(APIから取得した1件の顧客オブジェクト)。
API Product List(APIから取得した複数件の製品の配列)。
API‘s Content のようにオブジェクトの中の配列を指定することもできる。 - これらは、Bubbleの内部データベースの型とは別物(external type)。
- Bubbleでは、API Connectorで初期化(Initialize Call)した際に、APIレスポンスの構造から自動的にAPI xxx のような「外部データ型」が内部的に生成される。
Data Source
- 実際にその時点で保持・表示すべき「データ(実体)」の指定
- APIから取得した値やカスタムステートの値など、具体的なデータを渡す
APIから取得したオブジェクトの配列部分を使う場合、API’s Content のように配列(リスト)部分を指定する。 - よく使う場所
グループやRepeatingGroupの 中身のデータ指定。
InputやTextなどの 表示用バインド。
下図は、ドロップダウンリストにAPIから取得したデータを表示させるためにChoices sourceを指定しているところです。
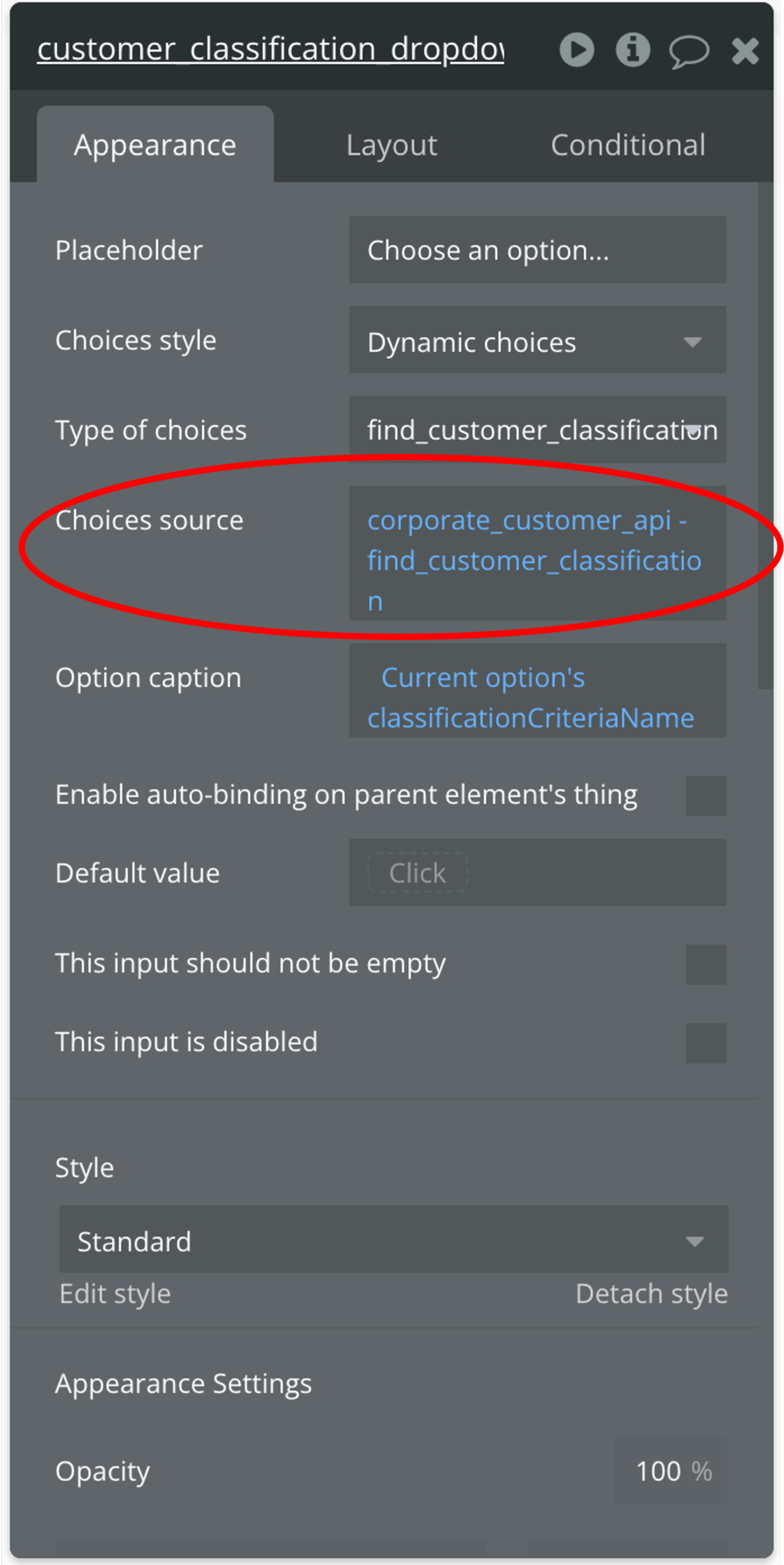
UIワークフローの設計
ボタンやページ読み込み時にAPIを呼び出し、データを取得または送信。
カスタムステートやページデータ(Type of content)にAPIレスポンスを格納し、表示に反映。
API呼び出し後のレスポンスコードやエラーをもとに、アラート表示やUI制御(バリデーション・エラーハンドリング)。
要件定義の画面遷移を参照してUIワークフローを定義します。
下図は、ワークフローによって、サーバーからのエラーメッセージから必要部分を抽出して画面上に表示させる例です。
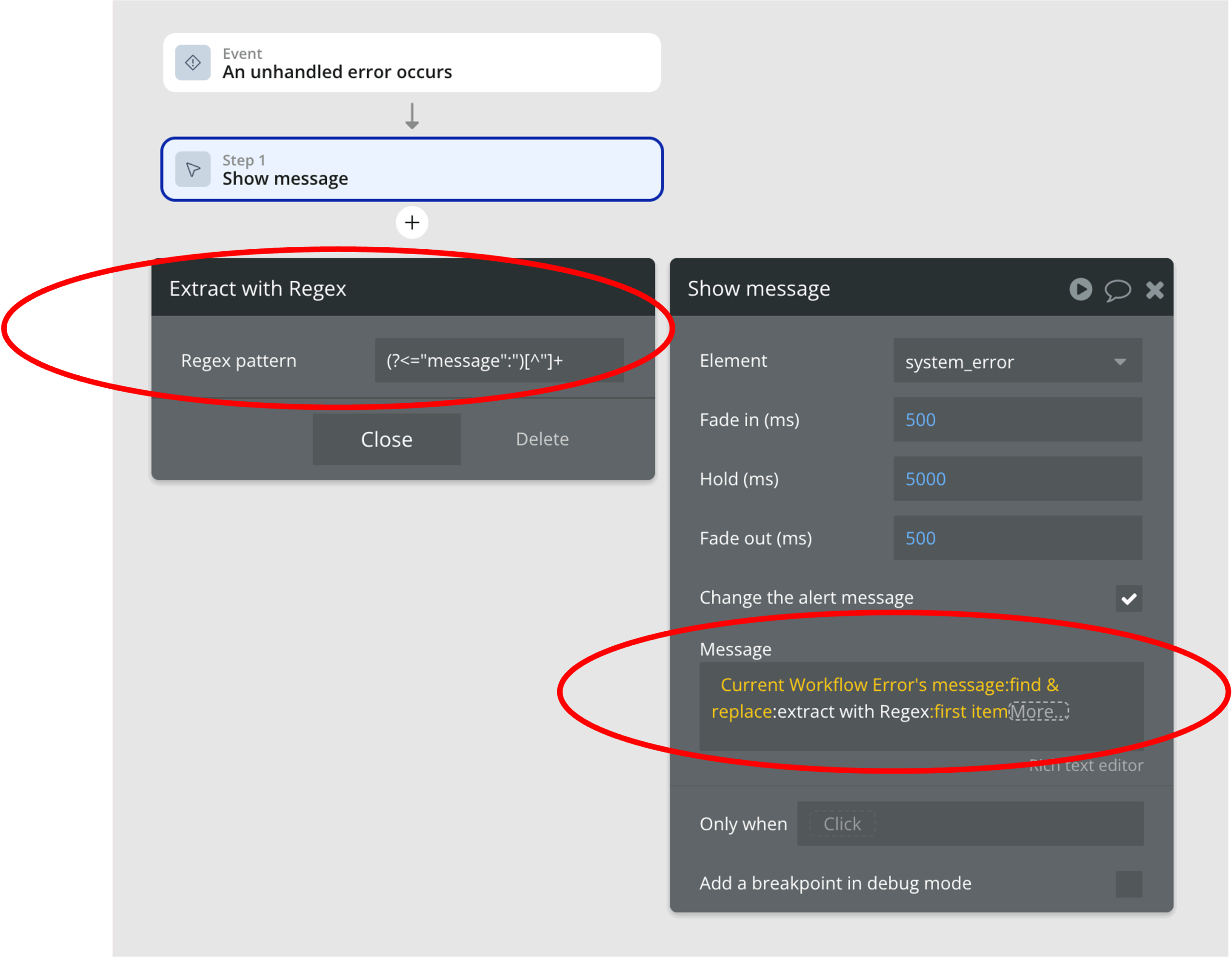
サーバー側では、次のようエラーレスポンスを返すとします。
@Data
@AllArgsConstructor
public class ErrorResponse {
private String code;
private String message; // 実際のユーザー向けメッセージ
private int status;
}
このメッセージのmessage部分をBubble側で抽出して表示するには次のように指定する必要があります。
- find & replace
Use Regex Patternにチェックを入れる。"
を"に変換する。
- extract with Regex
(?<="message":)"[^"]+
という正規表現(Regular Expression)で文字列を抽出する。
- first item
最初の項目を表示する。
また、下図は、ワークフローによって、ドロップダウンリストが変わったタイミングで、APIを介してデータを取得し、その結果をカスタムステートに設定する例です。
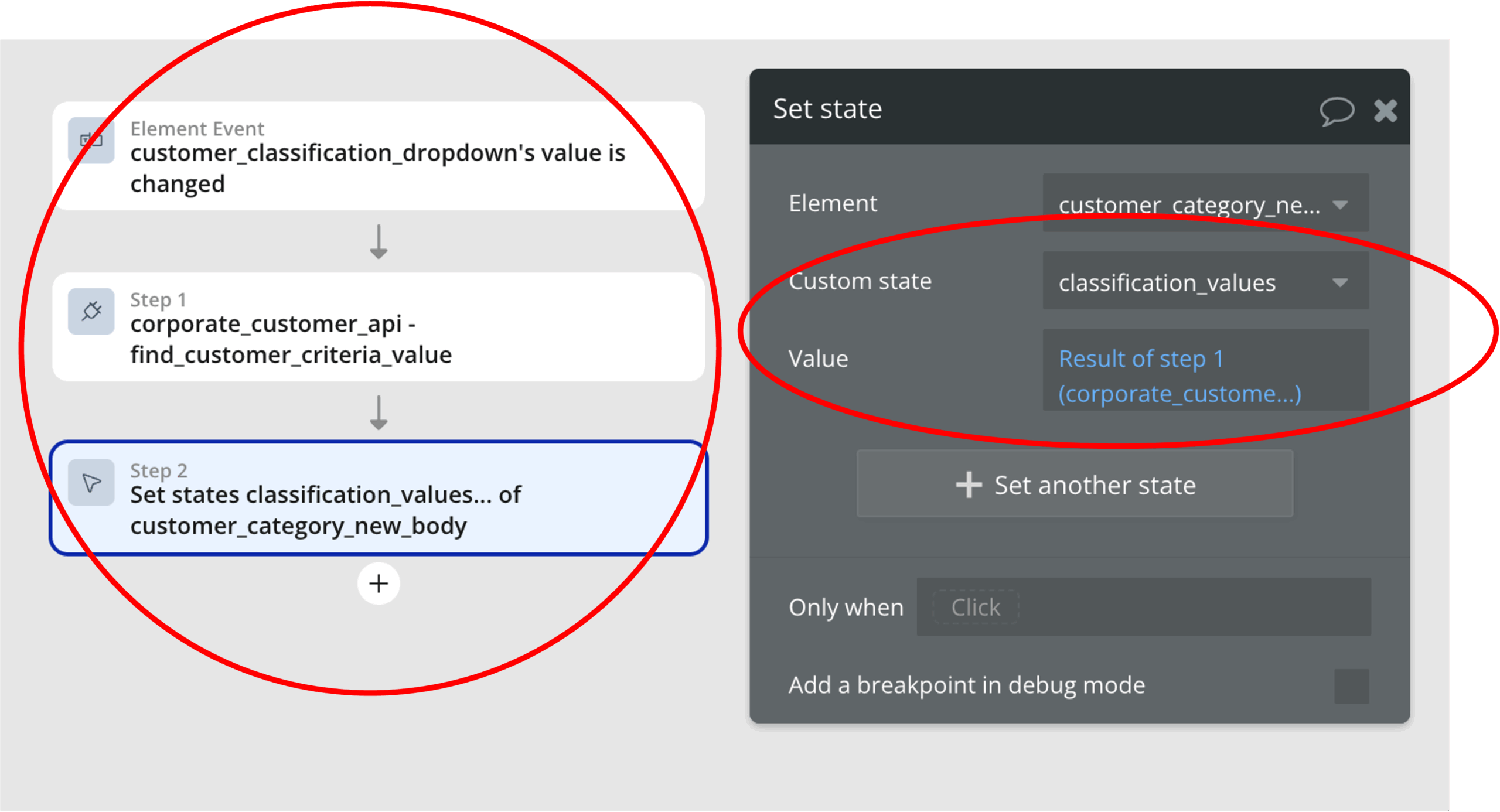
ドロップダウンリストでは、APIから取得されたデータが設定されたカスタムステートを表示することで、ドロップダウンリストの値に応じたデータをリスト表示することができます。


[…] 実装・テスト 内部設計の結果に基づいて、法人管理サービスを実装、テストします。 コントローラを実装するときは、OpenAPIに対応させるようにします。 詳細は、OpenAPI対応を参照してください。 […]
[…] curity + WebSecurityConfigurerAdapterを拡張したSecurityConfigを作成し、次の構成を実装してください。 CORS(クロスオリジン)設定 認証フィルター(AuthFilter)の登録 ※参考情報 セキュリティ対応 […]
[…] イベント駆動アーキテクチャ […]
[…] イベント駆動アーキテクチャ […]