![]()
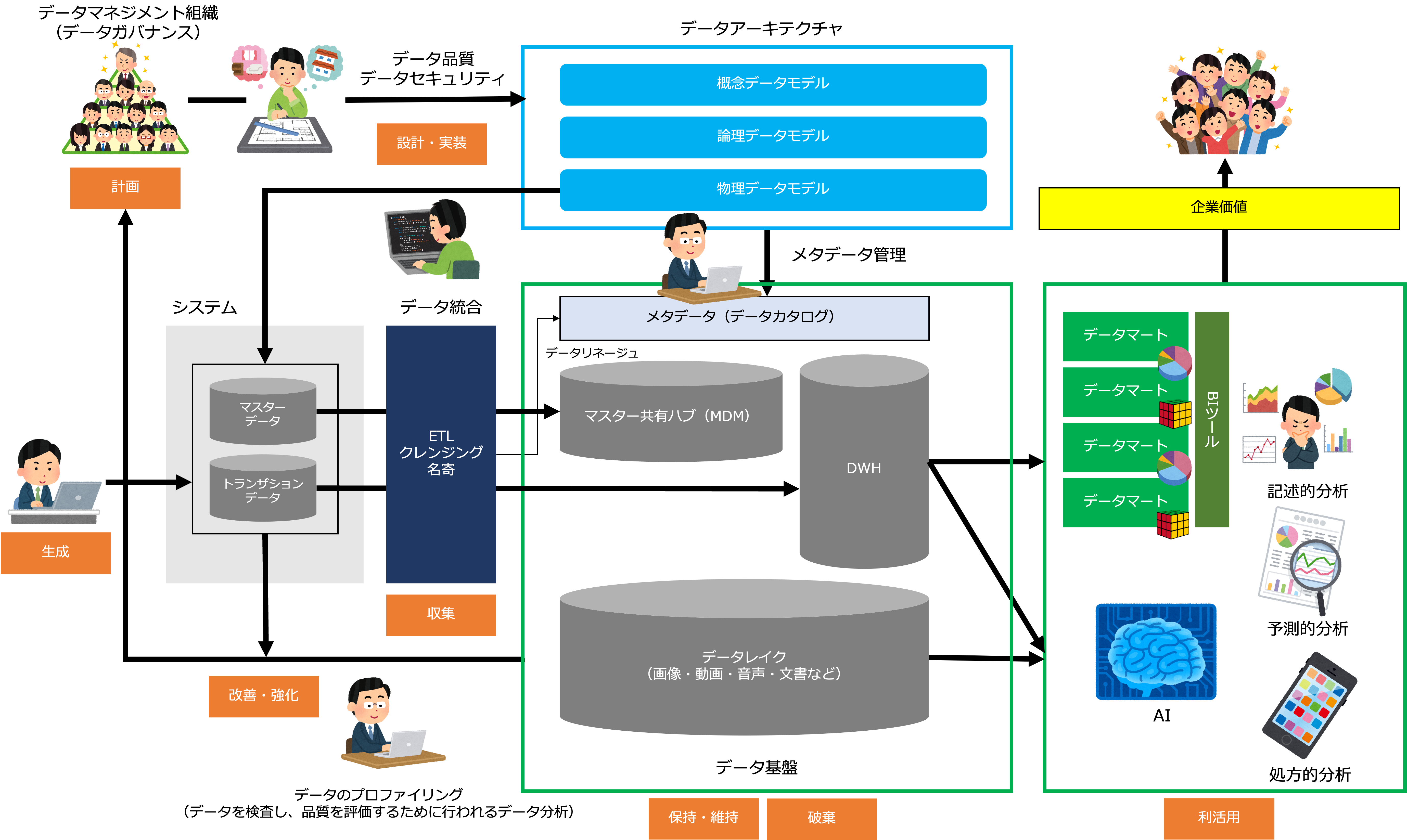
これは、データマネジメントの全体像を表した図です。
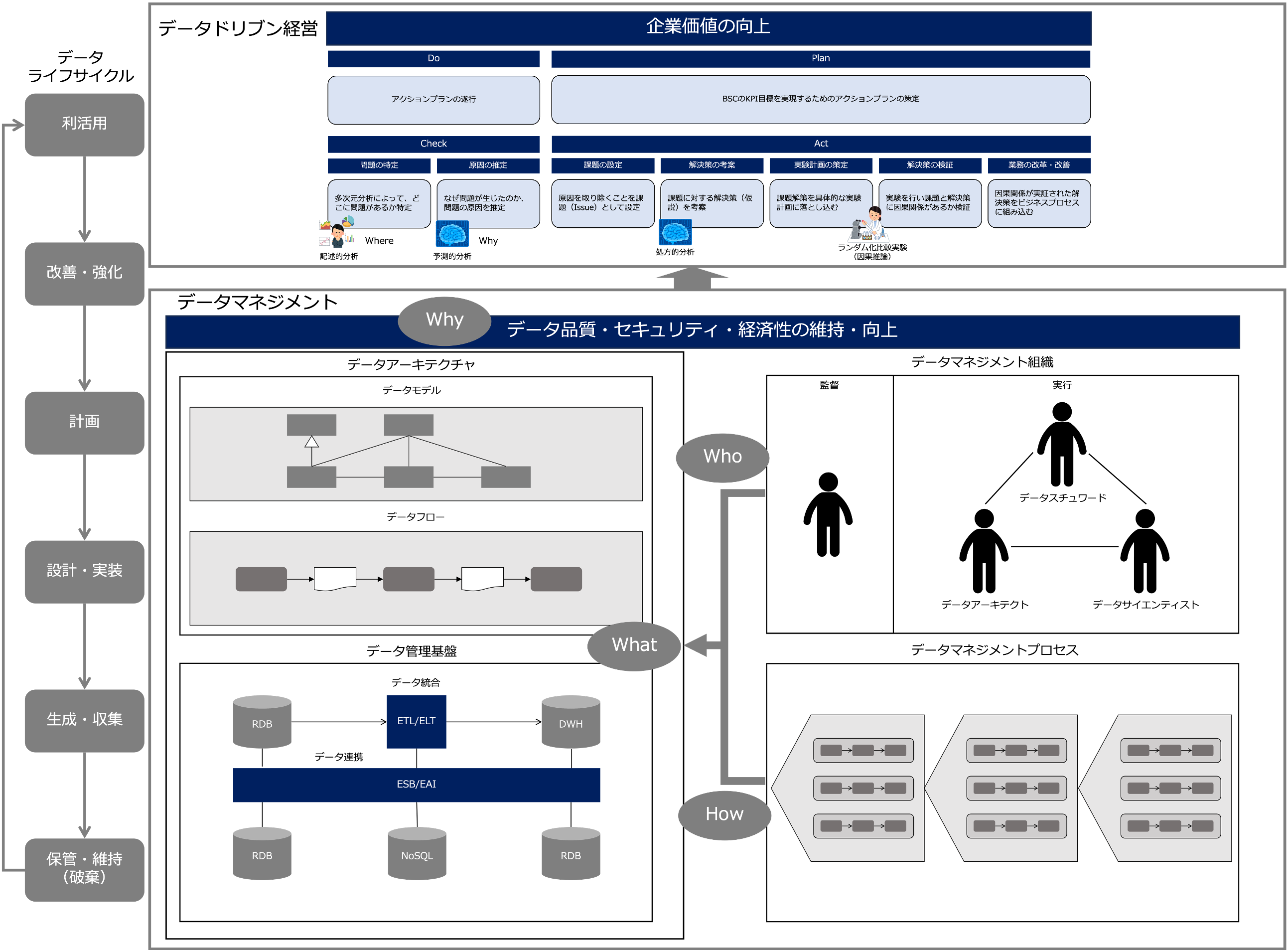
ここでは、データマネジメントについて次の観点で解説します。
データの重要性
変化が激しく、不透明で先行きが予測できない昨今の経営環境を、
- Volatility(変動性)
- Uncertainty(不確実性)
- Complexity(複雑性)
- Ambiguity(不透明性)
の頭文字をとってVUCA(ブーカ)という言葉で表すことがあります。
それは、SNSやモバイル技術によって人と人がつながる時間や距離が短くなったことで、個人の欲望や考えが、複雑なネットワークを介してすぐに世界中に広がり、いつどこで、どんな需要が生まれるか読みづらく、欲求の新陳代謝も激しくなっているからではないでしょうか。
このように、先行き不透明で予測困難な時代、経験や勘に頼るのではなく
稼ぐ力を持つ資産としてのデータをどう利活用してくか
ということが会社を発展させていくための重要な課題となっています。
「データは新しい石油(Data is the new oil)」と言われています。
会社に眠っているデータを、人やAIが、いかにうまく利活用して企業価値を生み出すことができるかが重要なのです。
最近では、「DATA is BOSS 収益が上がり続けるデータドリブン経営入門」という書籍で、データドリブン経営に舵をきり、売上右肩上がりの急成長をとげた「一休.com」の例が話題になっています。
さて、経営にデータを活用することの重要性は理解しているものの、多くの企業が、
- 会社にはさまざまなデータがあるのに活用されていない
- 会社にデータを活用できる人材がいない
- コストをかけてデータ基盤を構築したのに有効活用されていない
という状況にあるようです。
これは、
- ビジネスにとってどのようなデータが重要かわからない
- 必要なデータはどこにどういう状態で存在しているかわからない
- 必要なデータを取得するためにはどうすればよいかわからない
- 必要なデータを分析できる状態にするためには何をすればよいかわからない
など、データを経営に活かすための知識や仕組が十分に整備されていないからではないでしょうか。
データとは、人や物、事象に関する事実を表したものです。
データマネジメント知識体系(DMBOK)では、
データは万物に関する事実を表現する
と説明しています。
この事実としてのデータを経営に活かすことでデータは経済価値を持つ資産になります。
データマネジメントは、データを経営に活かすための知識や仕組を整備する方法を提供します。
データマネジメントとは何か
DMBOKでは、データマネジメントを、
データという資産の価値を提供し、管理し、守り、高めるために、それらのライフサイクルを通して計画、方針、スケジュール、手順などを開発、実施、監督すること
と定義しています。
これを、
- なぜ(WHy)
- だれが(Who)
- どのように(How)
- 何をするのか(What)
で並び替えると、次のように言い換えることができます。
データマネジメントとは、
- データの品質、セキュリティ、経済性を維持、向上するために(Why)
- データマネジメント組織が(Who)
- データマネジメントプロセス(開発、実施、監督)に従って(How)
- データのライフサイクルを管理すること(What)
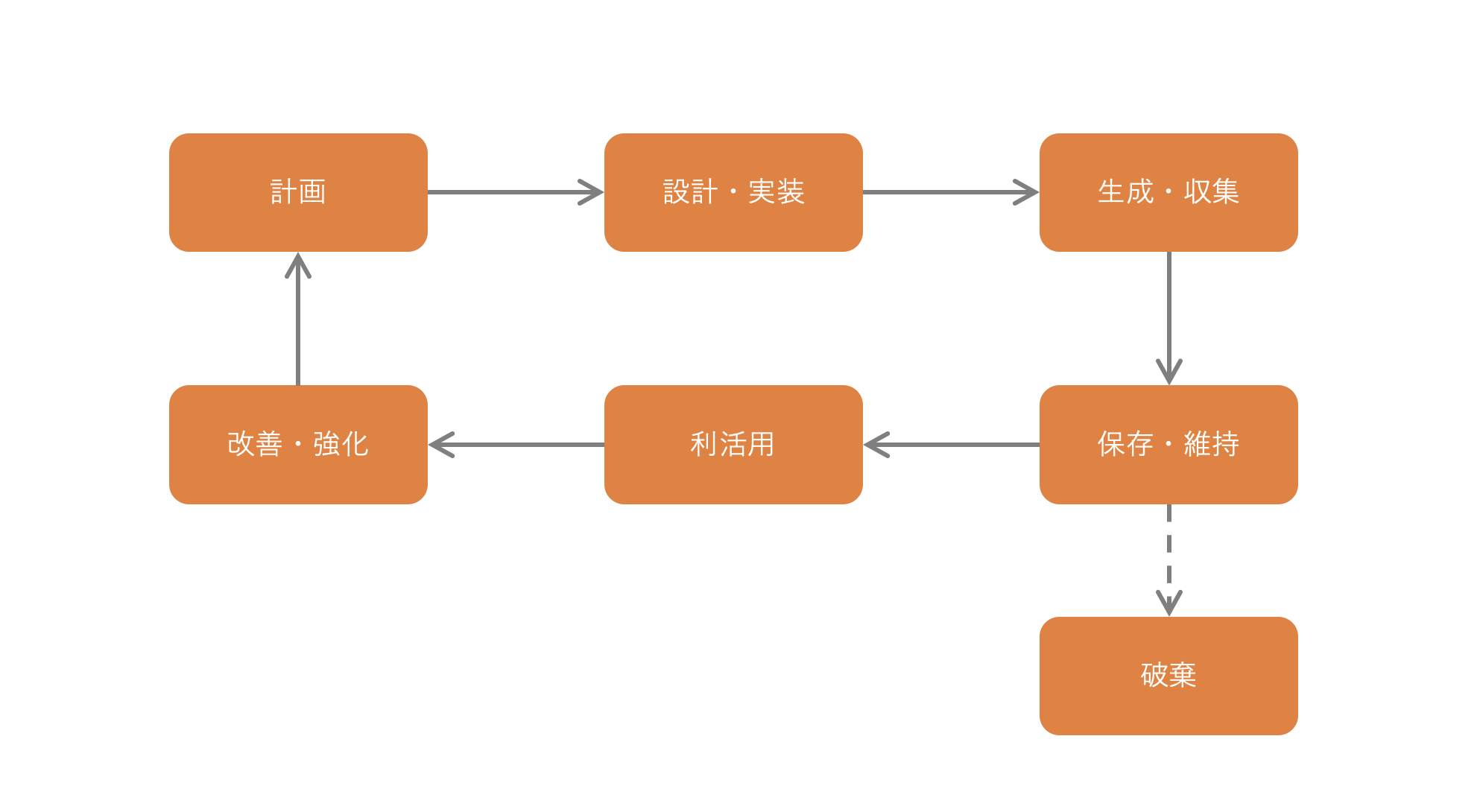
データのライフサイクルは、計画、設計・実装、生成・収集、保管・維持(場合によって破棄)、利活用、改善・強化という流れです。
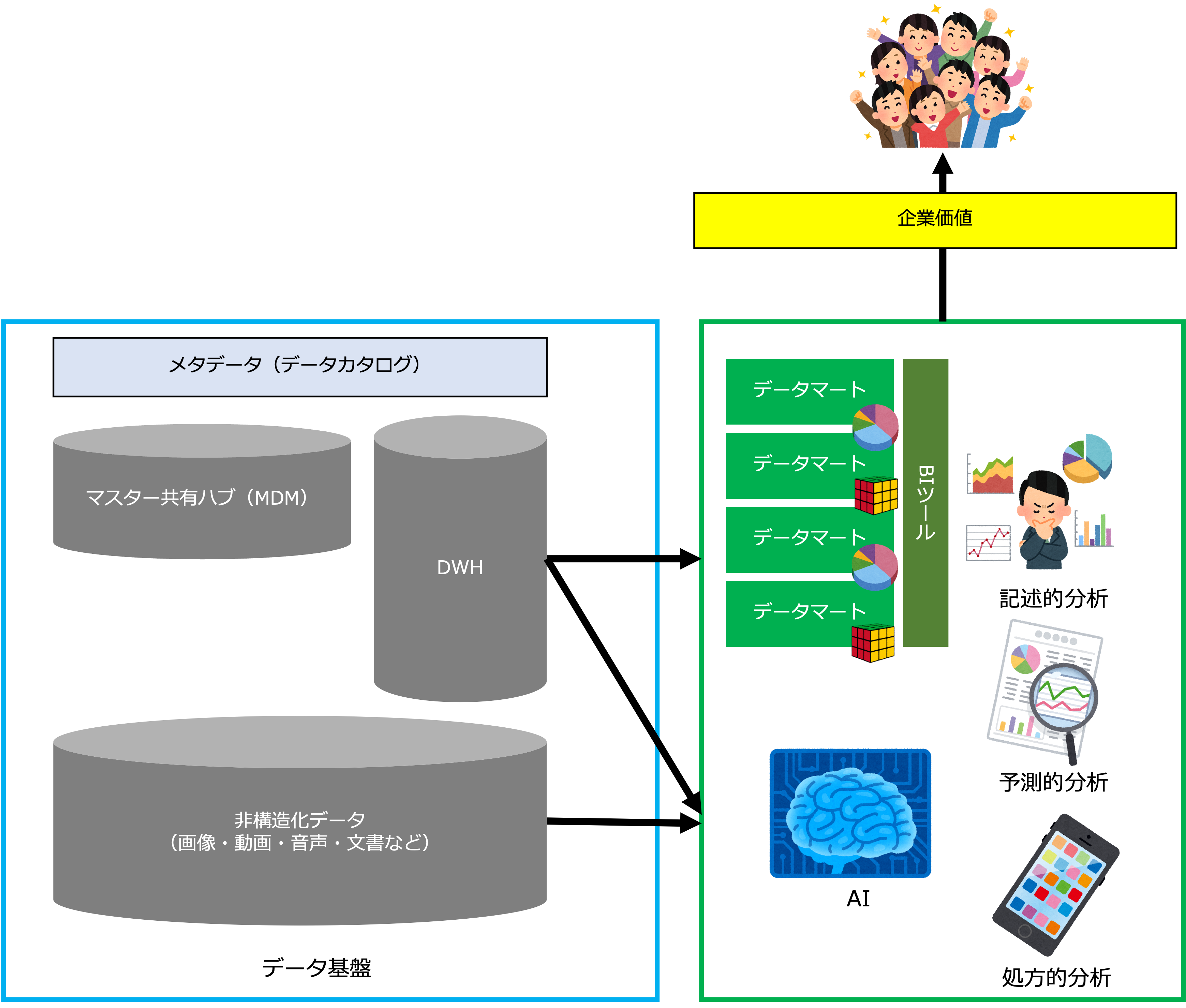
具体的に言うと、まず、業務上必要なデータを計画し、データの構造(データモデル)やデータの流れ(データフロー)を設計し(データアーキテクチャ)、それをデータベース(以降、DB)などデータ管理基盤上に実装します。
次に、業務活動を通して発生するデータが、データ管理基盤上で生成・収集、保管・維持されます。
データ管理基盤上のデータは、企業価値を高めるために利活用され(データドリブン経営)、その結果を受けて改善・強化されます。
なお、ここではDBやESBなどデータの保管や連携を管理するIT基盤をデータ管理基盤と呼んでいます(企業全体で一元的にデータを管理するIT基盤を狭義的なデータ管理基盤と呼びます)。
データライフサイクルを通してデータを管理する組織とプロセスを、それぞれ、データマネジメント組織、データマネジメントプロセスといいます。
データマネジメント組織は、データマネジメントプロセスに従って、データを設計、実装し、データ管理基盤を構築、運用するだけでなく、それらを通して、データの品質、セキュリティ、経済性を評価し改善します。
データマネジメント組織を、データマネジメント実行する役割と、それが適切に遂行されているか監督する役割に分掌することで、データガバナンスを確立、維持することができます。
データマネジメントの対象には、データアーキテクチャという論理的基盤と、データ管理基盤という物理的基盤があります。
よく見受けられるのが、高額なデータウェアハウスを導入して、「後は、業務部門が自由に使ってください」、というアプローチです。
いくら箱(物理的基盤)だけ用意しても、
なぜ、どのようなデータを、どのように記録し、活用すべきなのか
というデータアーキテクチャ(論理的基盤)が整備されていないと、業務部門も困惑するだけで、どうデータ利活用すればよいかわからず、宝の持ち腐れになってしまうのです。
目的がなく手段だけあるという状態です。
データアーキテクチャとデータ管理基盤が両輪となってデータドリブン経営を実現することができるのです。
それから、DMBOKの11の知識領域とデータマネジメントを構成するデータアーキテクチャ(論理的基盤)、データ管理基盤(物理的基盤)、データマネジメント組織、データマネジメントプロセスの関係は次のようになります。
- データアーキテクチャ
データアーキテクチャには次の知識領域が含まれます。- データアーキテクチャ
- データモデリングとデザイン
- データ品質
- データセキュリティ
- メタデータ
- データ管理基盤
データ管理基盤には次の知識領域が含まれます。- データストレージとオペレーション
- データ統合と相互運用性
- 参照データとマスターデータ
- ドキュメントとコンテンツ管理
- DWHとBI
- データマネジメント組織
データマネジメント組織にはデータガバナンスが含まれます。 - データマネジメントプロセス
データマネジメントプロセスにはデータガバナンスが含まれます。
データマネジメントの必要性
さて、データのライフサイクルの中で、データが直接経済価値を生む活動(プロフィットセンター)は「データ利活用」で、あとの活動はコストがかかるだけのコストセンターです。
データマネジメントは、データライフサイクル全体を通して、データの品質とセキュリティと経済性を管理します。
データの経済性とは「できるだけコストをかけずに、どれだけデータの持つ経済価値を活かせるか」を表します。
データライフサイクルのコストセンターの活動は、「データ利活用」にかかるコストをさげるために必要なコストだと考えることができます。
データマネジメントを導入することで品質とセキュリティの高いデータを「データ利活用」のためにコストをかけずに迅速に準備することができるようになります。
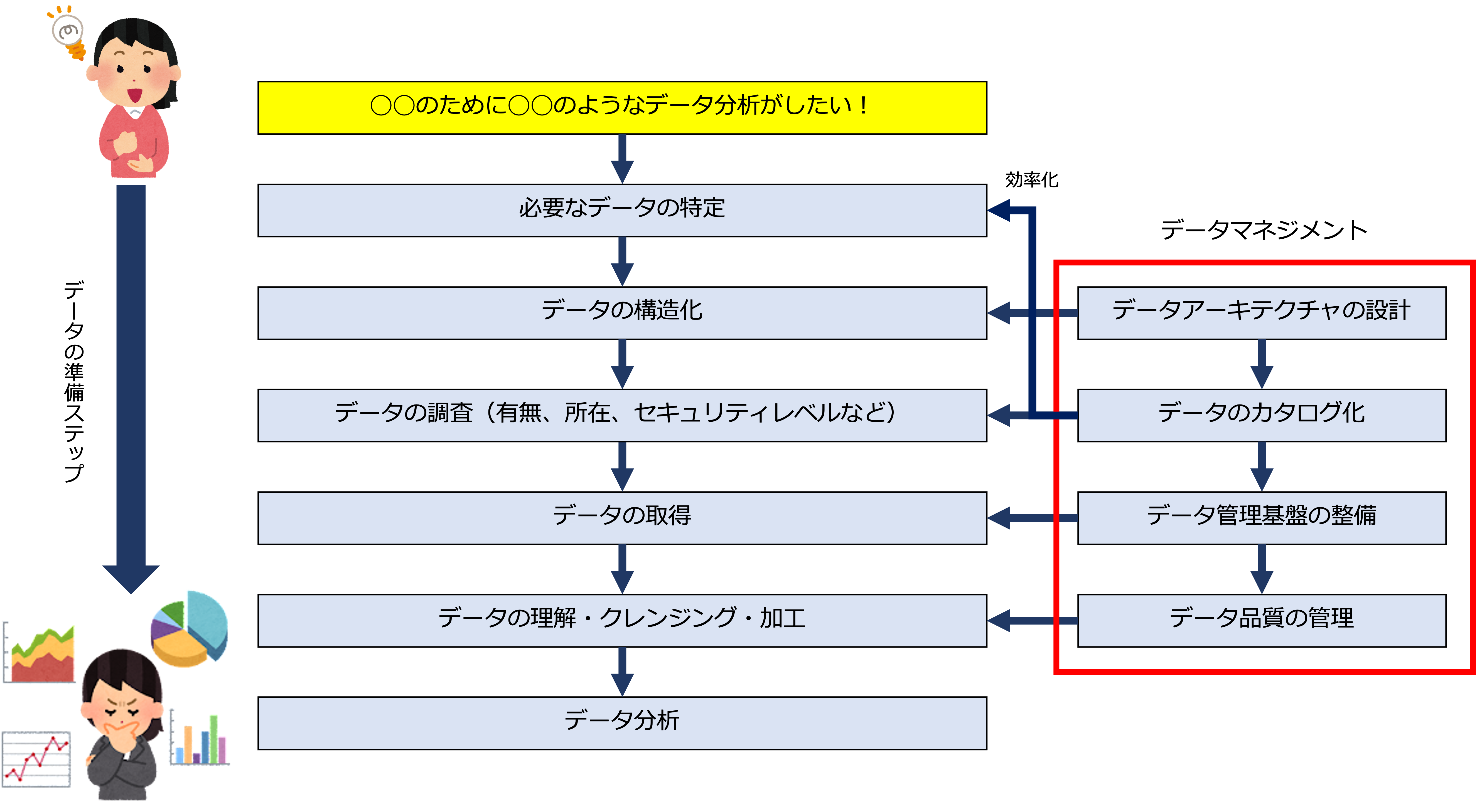
例えば、社員が「こんなデータ分析をしたい!」と考えても、実際にデータ分析ができるようになるまでにはさまざまな準備のステップが必要です。
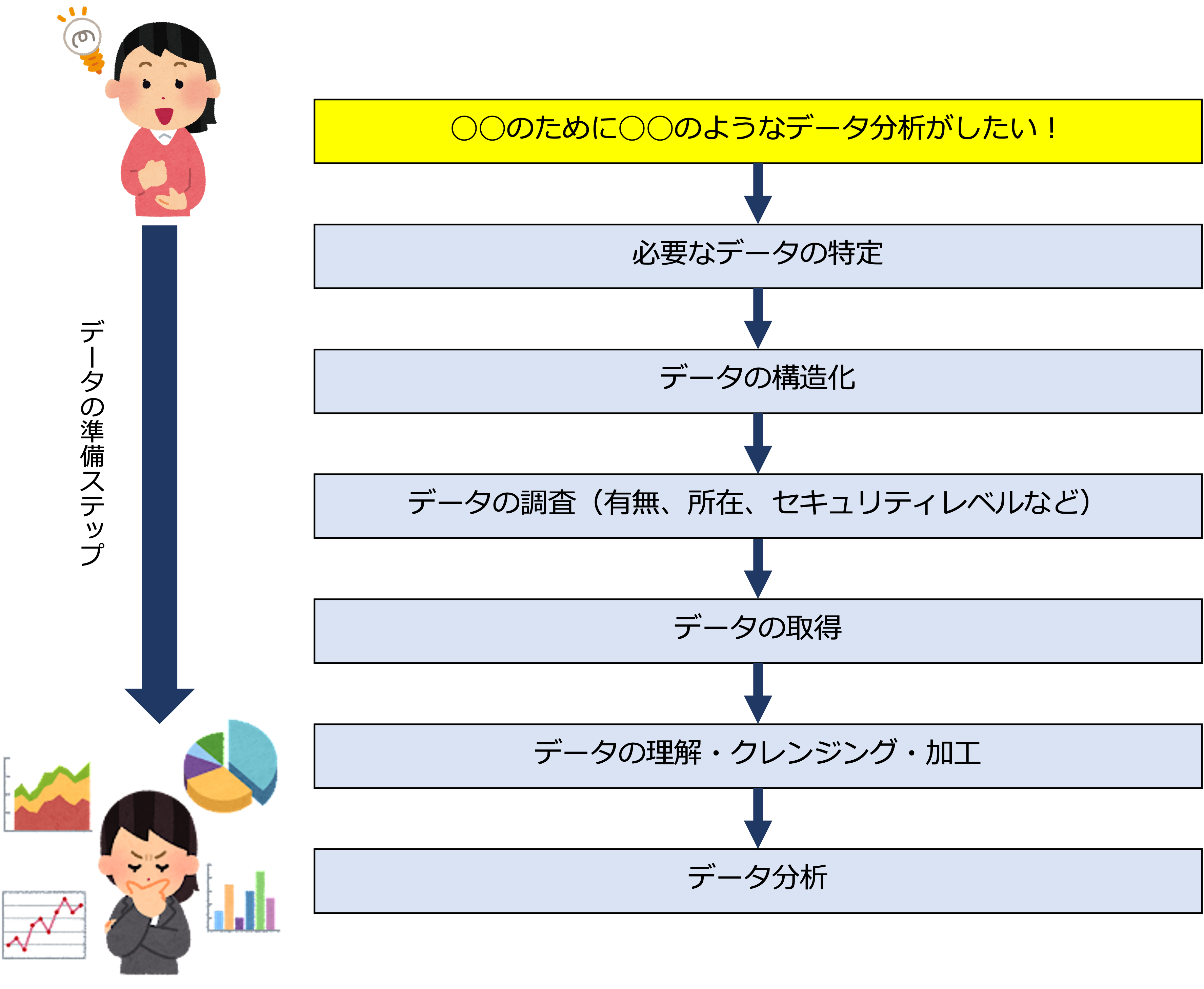
例えば、身近に次のような問題はないでしょうか。

これは、業務活動によって発生する事実としてのデータはあるものの、データが資産になっていない(稼ぐ力を持っていない)、つまり、ビジネスにとって重要な(経済価値を持つ)データがすぐに活用できる状態になっていないということです。
データマネジメントが導入されると、さきほどの問題は次のように解決することができます。
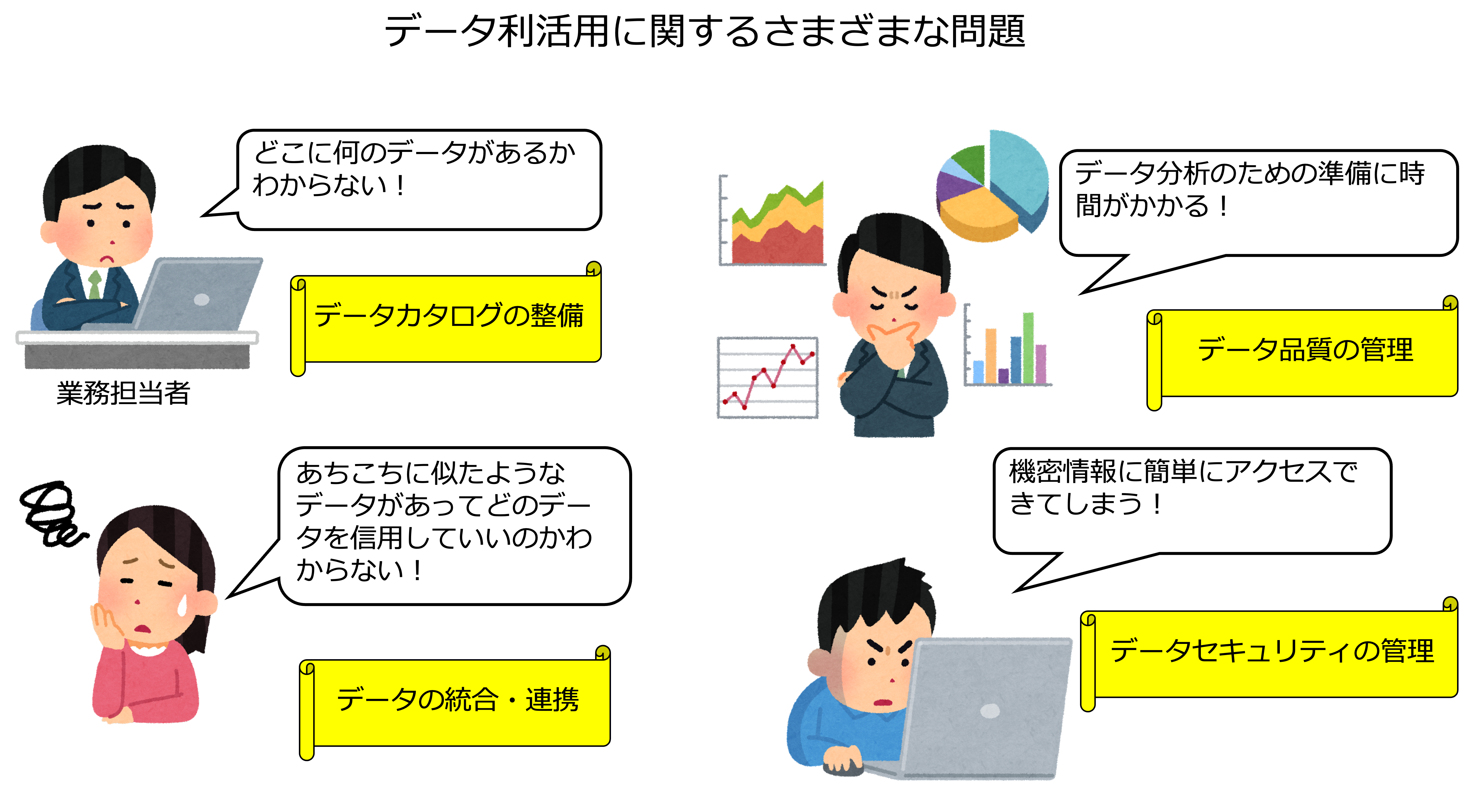
データカタログの整備
データアーキテクチャを設計し、各データのメタデータ(データに関するデータ)を定義し、データカタログとして整備することで、データ分析者は、必要なデータに関する情報(データの有無、所在、構造、来歴、品質の状態、セキュリティレベル、利用するときの連絡先など)を得ることができるようになります。

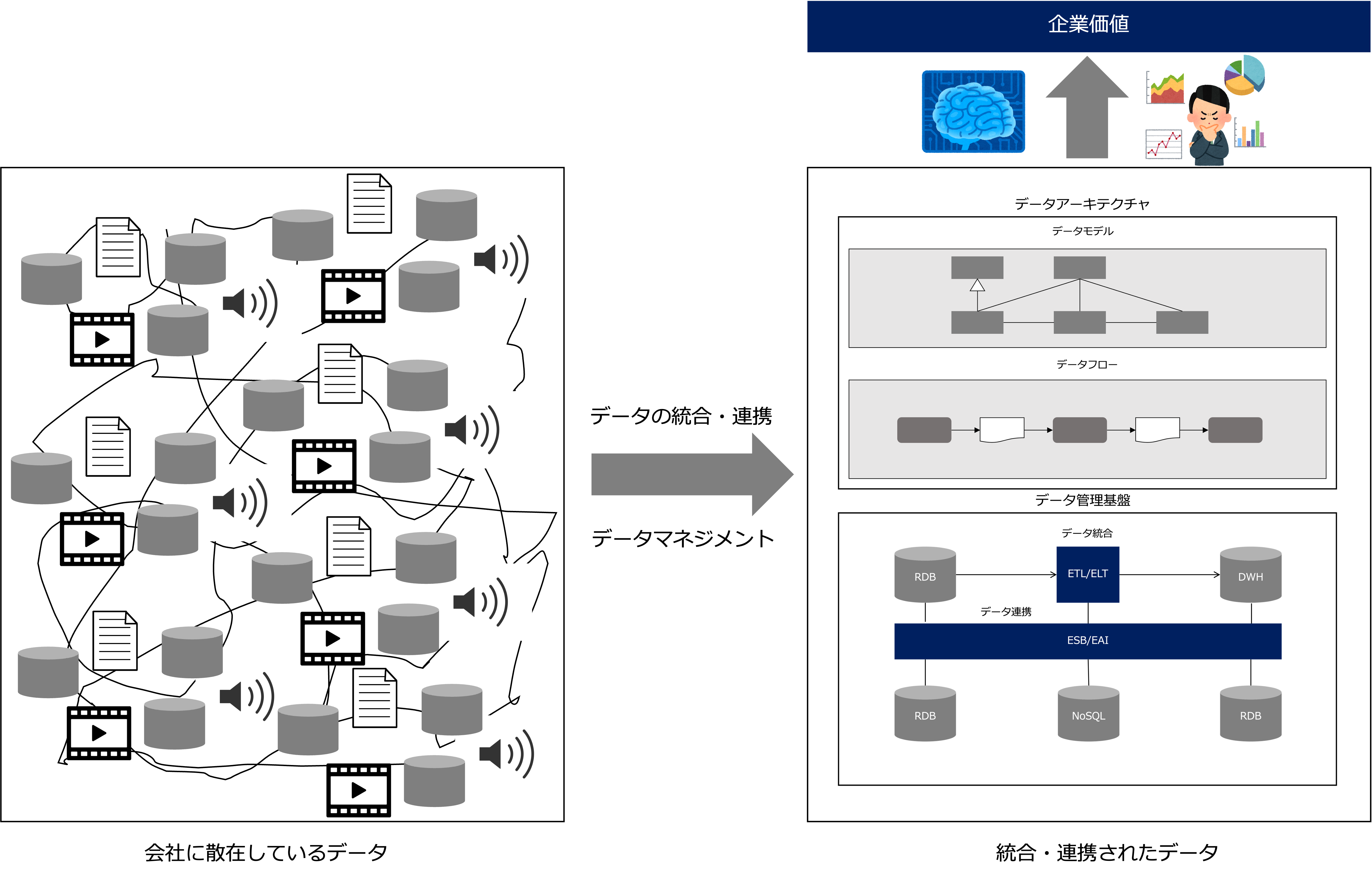
データの統合・連携
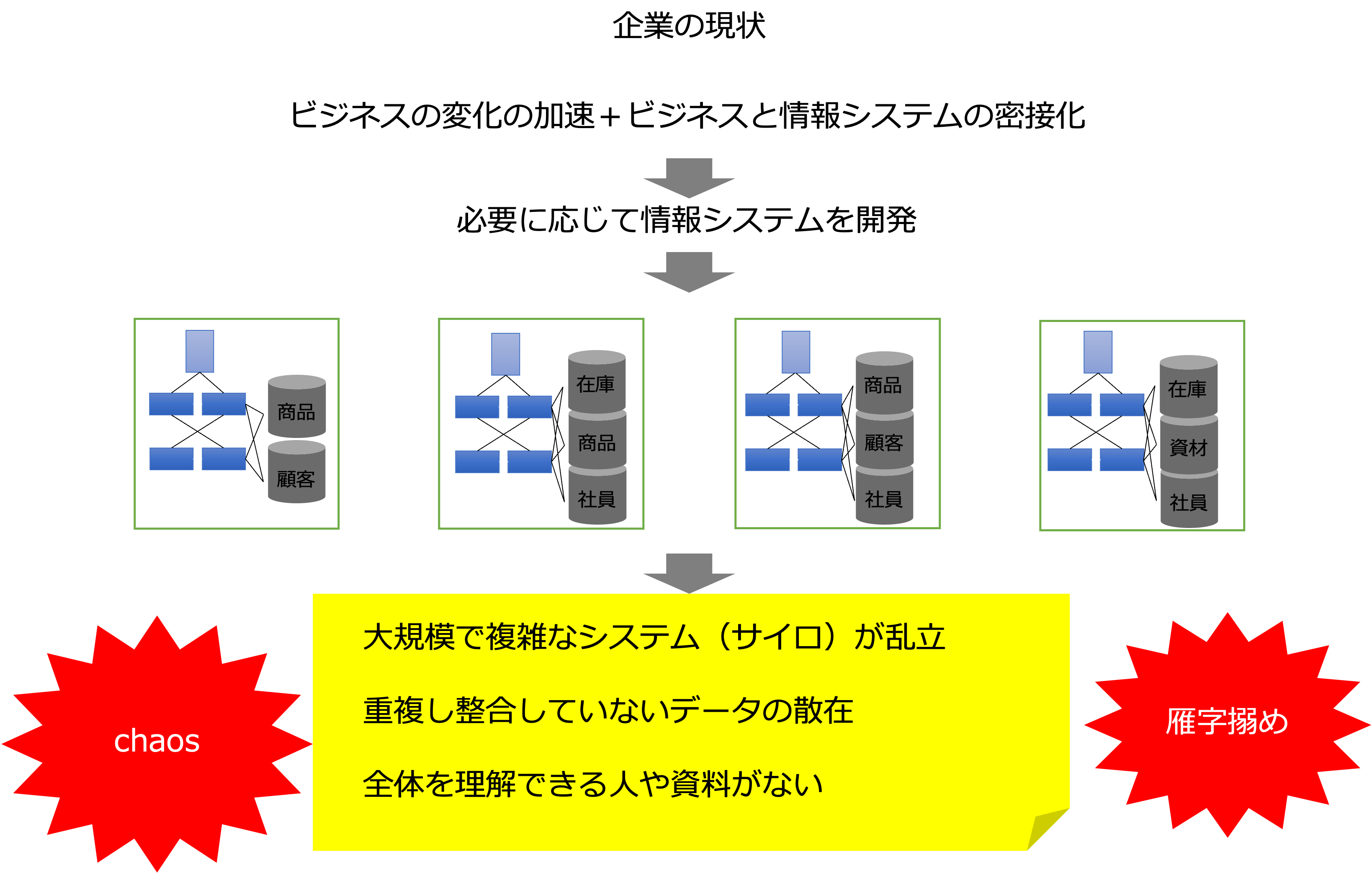
多くの会社が、
ビジネスの変化が加速し、ビジネスとITが密接化する中、全体の設計図もなく、必要に応じてシステムを導入してきた結果、
- 大規模で複雑なシステムがサイロのように乱立している
- 重複して整合していないデータが散在している
- 個別の業務やシステムは詳しいが全体を理解できる人や資料がない
というカオスで雁字搦めな状況に陥っています。
データマネジメントでは、散在して存在する共通データを統合、連携し、会社全体として一元管理するのでデータの信頼性を高めることができます。
データ品質の管理
データ分析をするためには、データがきれいな状態でなければなりません。
次のようなケースを考えてみましょう。
例えば、あるエリアの不動産物件の適正な家賃を推定する場合、広さや駅からの距離、築年数といった変数の影響が大きくなります。
このとき、とある物件の建築年のデータが抜けたまま分析した場合、プログラムがどう判断するのかというと「建築年=””」→「西暦00年に建てられた」→「2024年前に建てられた物件」と捉え、広くて駅近なのに、ものすごく古い物件なので「適正家賃は0.01円」という分析結果を出してきたりするのです。
「DATA is BOSS 収益が上がり続けるデータドリブン経営入門」より引用
このように品質の悪いデータは、間違った意思決定をもたらすかもしれず、経済価値を生む状態とは言えません。
DMBOKでは、セキュリティや品質が確保されていないデータがもたらす事象として以下の例をあげています。
- 誤請求
- 顧客サービスコールの増加とそれを解決する能力の低下
- 事業機会の逸失による収益損失
- 合弁・買収の間に発生する業務統合の遅延
- 不正行為発覚の増加
- 不正なデータに起因する業務上の意思決定不備がもたらす損失
- 良好な信用力の欠如による事業の損失
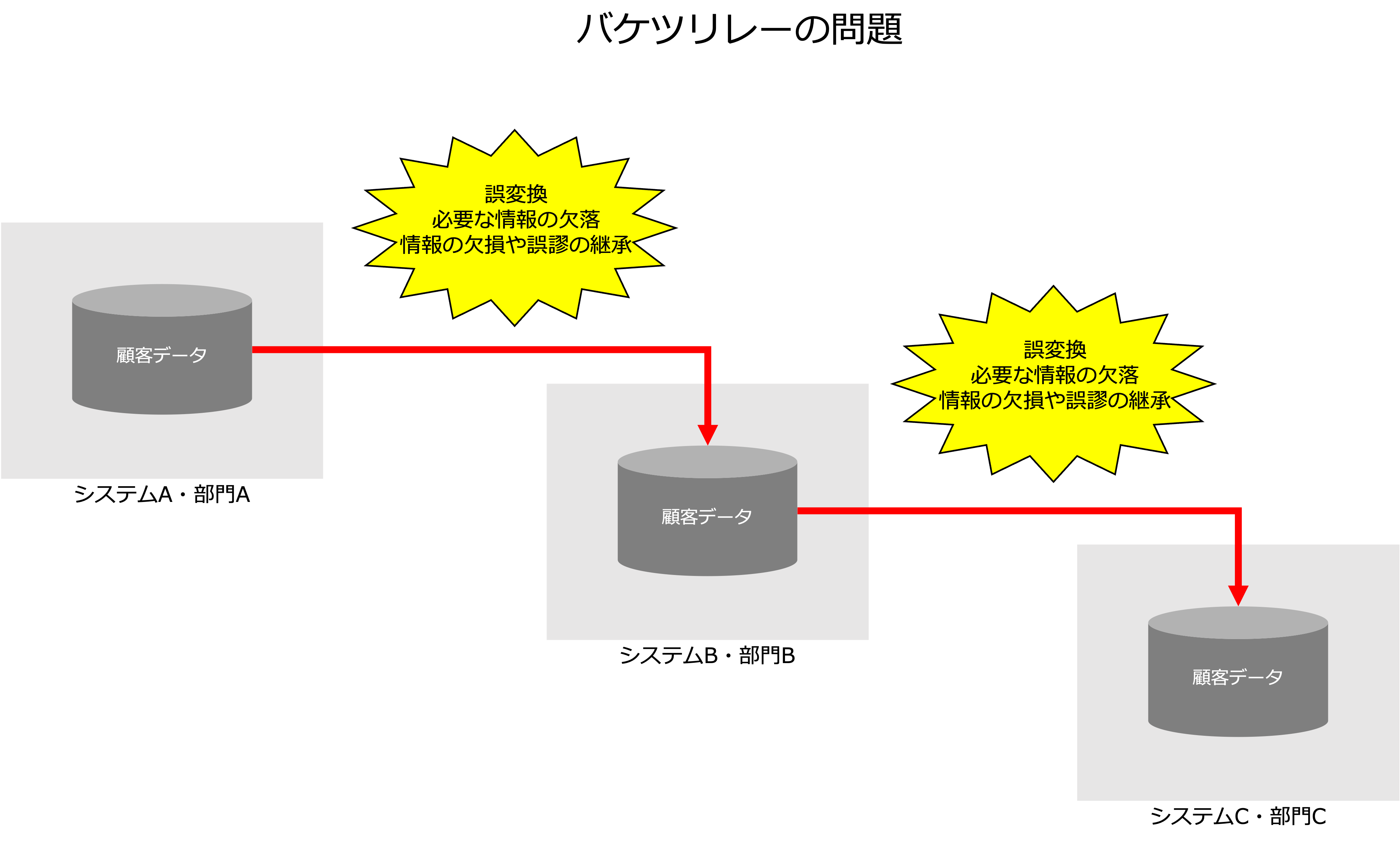
データ分析に必要なデータを取得しても、多くのデータには欠損や誤謬があり、そのままの形では利用できないので、まず、データをクレンジング(破損または不正確なデータを検出して修正すること)してきれいにしてから使う必要があります。
特に、データがバケツリレーのようにコピーされ使い回されていると、
- 誤変換
- 必要な情報の欠落
- 情報の欠損や誤謬の継承
という問題が発生し、会社全体のデータ品質の低下を加速させていきます。
書籍「DATA is BOSS 収益が上がり続けるデータドリブン経営入門」の中で、株式会社一休 代表取締役社長の榊さんは次のように言及しています。
- データクリーニングや、データクレンジングといった言葉を聞いたことがあると思います。データドリブンな意思決定をするには、扱うデータの質が高いことが前提です。データの質が高くないと、「人間なら絶対こんな返答しないよね」という結果を平気で返してくることがあるので、それを踏まえた活用が大事です。
- データの質の担保は、AIによってデータドリブンがしやすくなるだけに、今後さらに重要になるはずです。経営としては、社でこれらを維持できるよう、努めなければなりません。
このデータの質(データクオリティ)を定義し、体系的に維持、管理する仕組がデータマネジメントなのです。
データマネジメントでは、データの品質要件をメタデータとして定義し、実際のデータをプロファイリング(データを検査し、品質を評価するために行われるデータ分析)し、継続的に品質を改善するのでデータの品質を維持、向上することができます。
データセキュリティの管理
上述したようにデータが散在していると、それだけ機密データの漏洩、破壊、改ざんなどのリスクが高くなります。
データマネジメントでは、データアーキテクチャで設計されたデータのセキュリティ要件(機密性レベルなど)をメタデータとして定義し、それに応じたセキュリティ対策(認証、認可、アクセス制御、監視、データのバックアップと復旧、機器・設備の冗長化、監査、緊急事態計画と実施など)を実施することで、データの機密性、完全性、可用性を保証します。
なお、データを統合するとき、コマンド・クエリ責務分離(CQRS)パターンを適用すると、データの読み込みや書き込みに対するアクセス制限の設計が容易になりデータのセキュリティを上げることができます。
書籍「DATA is BOSS 収益が上がり続けるデータドリブン経営入門」では、日本でデータドリブンが機能していないケースの最初に「見たいデータが見られない」ケースをあげています。
こうした場合は、そもそもデータを整備するケイパビリティが不足しています。
具体的には、どういったデータやどんな分析ができれば顧客の姿が見えてくるか描いた上で、収集するデータの定義、データインフラの整備、データの更新方法などを交通整理していく必要があります。
それは事業の特性や組織の状況によって変わってくるので、社内外のリソースをうまく使って、継続的にデータを整備していくための体制づくりから、しっかり取り組むのが得策です。
「DATA is BOSS 収益が上がり続けるデータドリブン経営入門」より引用
データマネジメントは、主に
- ビジネスとして経済価値のるデータを特定する方法
- 企業全体のデータ構造(データ同士の関係)やデーフロー(データのライフサイクルを通した流れ)を可視化し、データの見取り図(データアーキテクチャ)を作成する方法
- データをカタログ化して必要なデータに関する情報(データの有無、所在、構造、来歴、品質の状態、セキュリティレベル、利用するときの連絡先など)をすぐに入手できるようにする方法
- データを統合・連携することでデータの品質やセキュリティを向上させるとともにデータ利活用の効率を上げる方法
- データのライフサイクルを通してデータの品質(一意性、完全性、一貫性など)やセキュリティを組織的に統制する方法
を提供します。
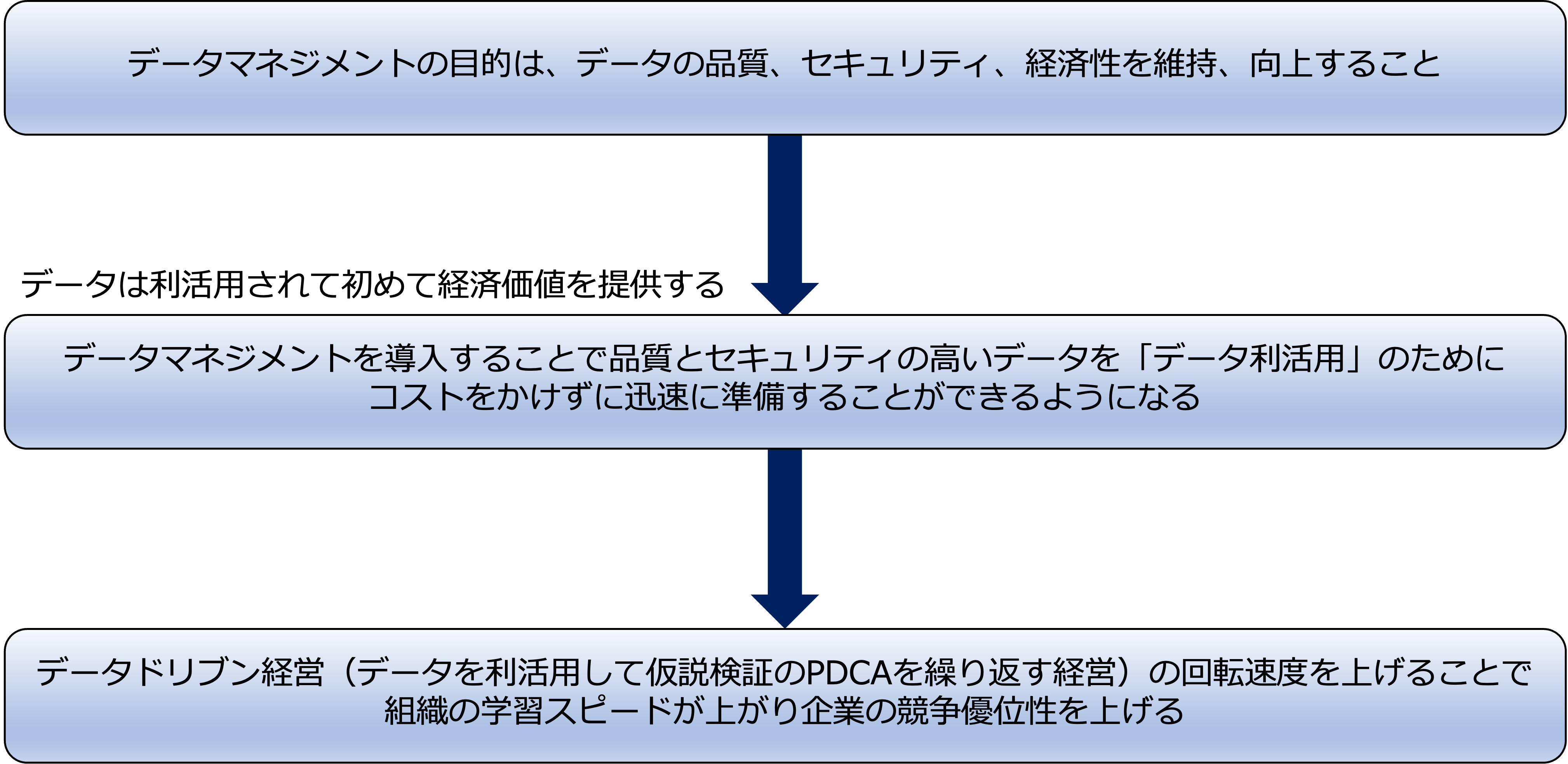
なので、データマネジメントを導入することで、データのプロビジョニングサイクルを極限まで早くすることができ、データドリブン経営による仮説検証の回転速度を上げることができます。
データマネジメントは、会社にあるカオスな状態のデータを整備し、企業価値を生む状態に資産化します。
つまり、会社に眠っている負債としての(維持するためのコストがかかるだけの)データを経済価値のある資産としての(稼ぐ力を持つ)データに変えることができるのです。
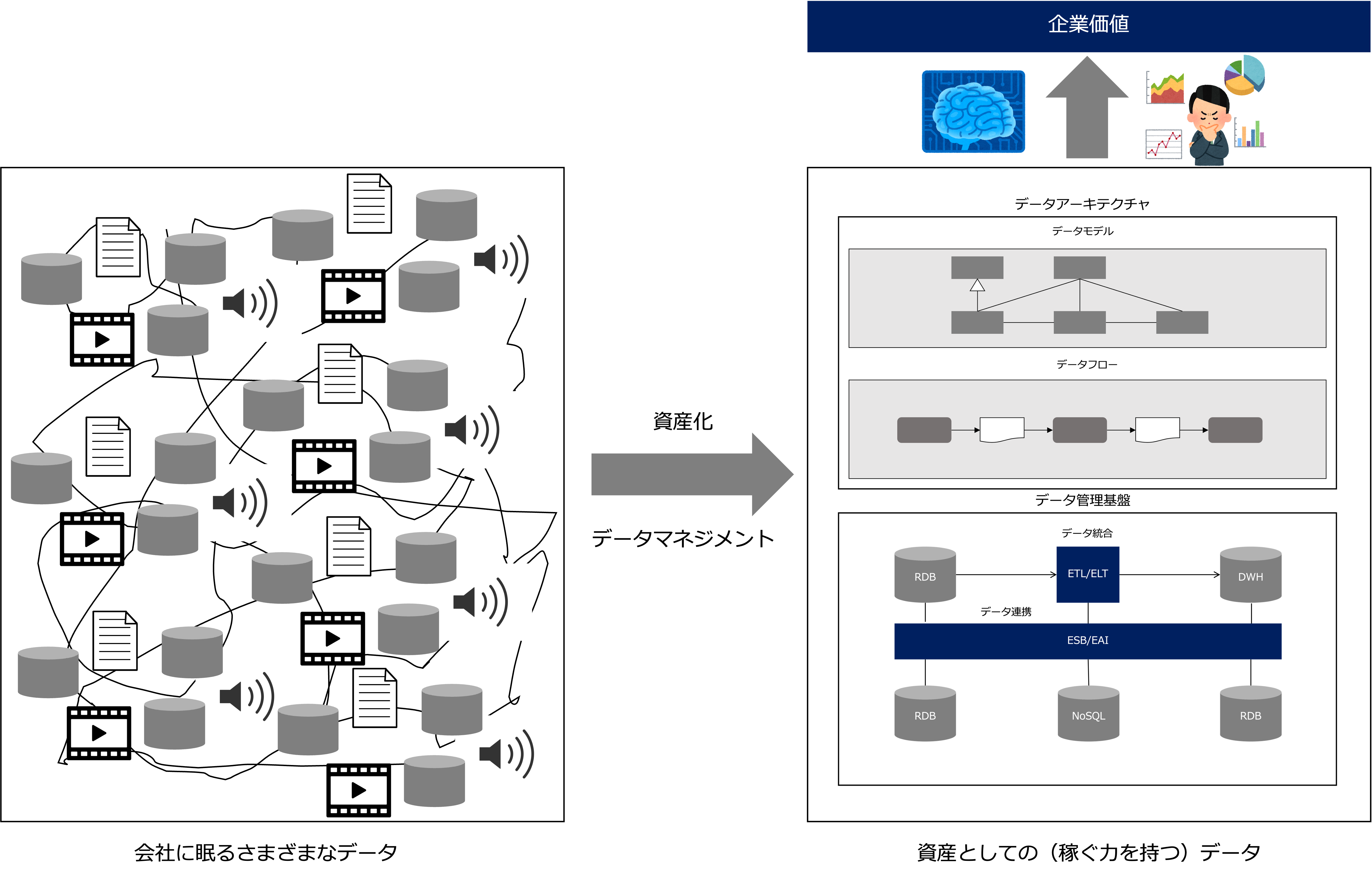
データの資産化とは、ビジネスにとって重要な(経済価値を持つ)データがすぐに活用できる状態になることであり、データドリブン経営の回転速度を上げることで組織が学習スピードを上げるということです。
ピーター・M・センゲの「最強組織の法則」という書籍に、
競争相手より早く学べる能力、それが競争力を維持する唯一の鍵である
と書かれています。
データマネジメントによって競争相手より早く学べる能力をつけることで企業の競争優位性を上げることができるのです。
データマネジメントの導入アプローチ
それでは、企業にデータマネジメントを導入するにはどうすればよいのでしょうか。
最後に、データマネジメントの導入プロセスについて見ていきましょう。
データマネジメントは、そのプロセスの状態によって成熟度を測ることができます。
データマネジメント成熟度レベル(Data Management Maturity Levels)は、組織がデータをどのように管理し、利用しているかを評価するための枠組みで、以下の5つのレベルに分けることができます。
- レベル 1: 場当たり的な状態 (Initial)
まずやってみる
データ管理はアドホックであり、プロセス、および、データ基盤管理基盤の手順は正式に文書化されていません。
データの品質が低く、データの利用は個々のプロジェクトに依存します。 - レベル 2: 繰り返し可能な状態 (Repeatable)
最低2回繰り返す
基本的なデータマネジメントプロセス、および、データ基盤管理基盤が確立され、繰り返し可能な手順があります。
しかし、そのプロセスは依然としてプロジェクトごとに異なり、標準化が進んでいません。 - レベル 3: 定義された状態 (Defined)
プロセスとプロダクトを標準化する
データマネジメントプロセス、および、データ基盤管理基盤が組織全体で定義され、標準化されています。
しかし、そのプロセスの実行が一貫しておらず、完全な実施には至っていません。 - レベル 4: 管理された状態 (Managed)
プロセスとプロダクトを管理する
データマネジメントプロセス、および、データ基盤管理基盤が実行、監視され、測定されており、プロセスの効率化が図られています。
継続的な改善が必要ですが、プロセスの監視と測定が定着しています。 - レベル 5: 最適化された状態 (Optimized)
プロセスとプロダクトを継続的に改善する
データマネジメントプロセス、および、データ基盤管理基盤が最適化され、継続的に改善されています。最新の技術やベストプラクティスが取り入れられています。
イノベーションと最適化が組織の文化として根付いており、高度なデータ分析やビジネスインテリジェンスが可能です。
これらのレベルは、組織がデータをどの程度効果的に管理し、利用できるかを評価するための基準となります。
データマネジメントは、次の図のように一つの戦略サイクルで導入されます。
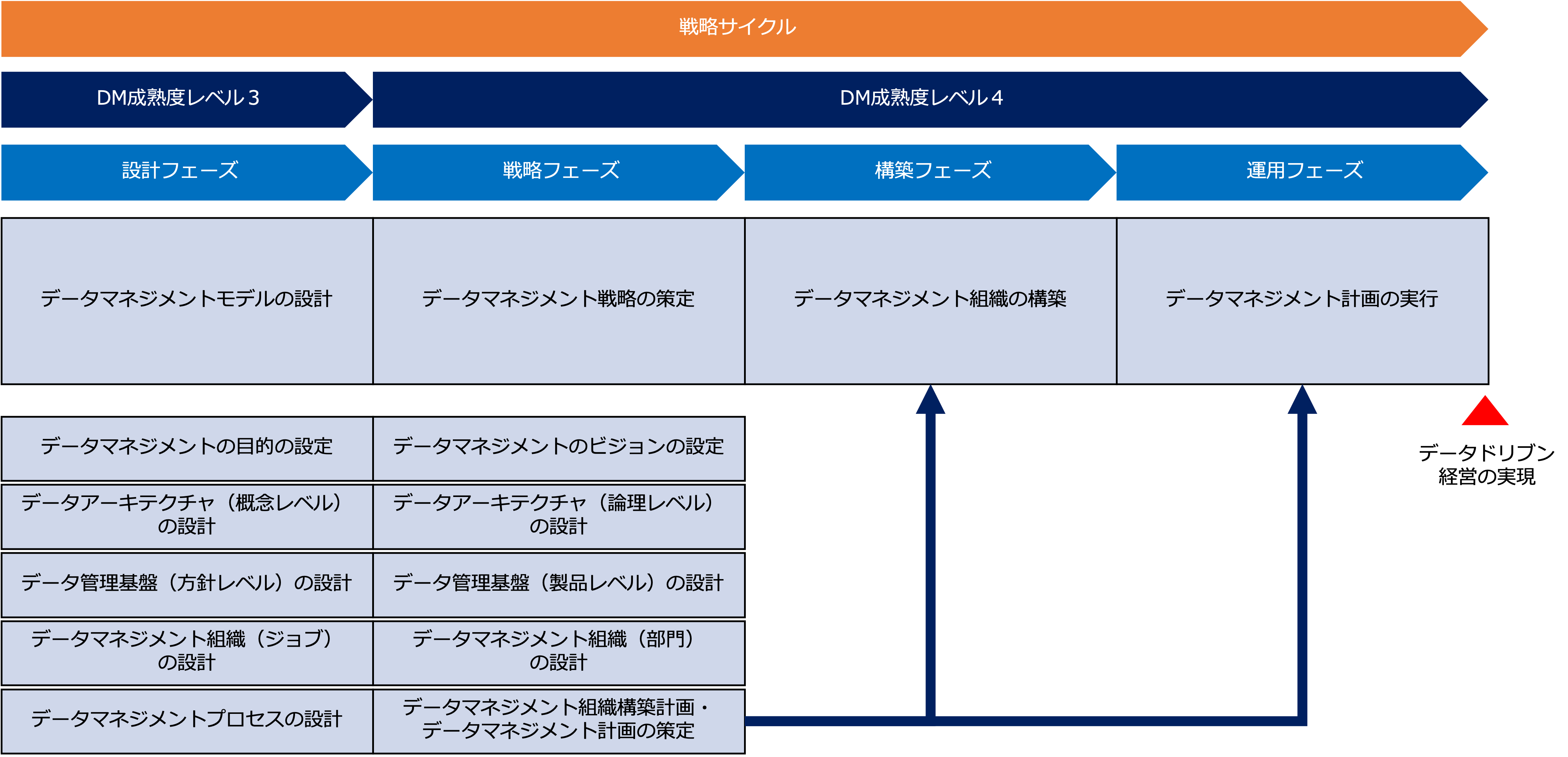
※データマネジメントが導入された後も、新しく戦略サイクルが開始する都度、このデータマネジメントプロセスが実行されます。
DM成熟度でいうと、設計フェーズで、データマネジメントモデルを設計した段階で、レベル3,定義された状態になり、
DM戦略を策定し、それにもとづいてDMシステムを構築し、1回以上運用することでレベル4、管理された状態になります。
そして、この段階で、データドリブン経営が実現された状態になり、データドリブン経営を繰り返すことでレベル5、最適化された状態になります。
データマネジメント導入プロセスの概要は次のようになります。
- データマネジメントモデルの設計
データマネジメントの目的、体制、方法など本質となる型を設計します。
その際、あるべき(To-Be)データアーキテクチャ、データ管理基盤、データマネジメント組織、データマネジメントプロセスを概念レベルで設計します。 - データマネジメント戦略の策定
データマネジメントモデルを具体的にどう実現するのか戦略を策定します。
その際、データマネジメントのビジョン、および、あるべき(To-Be)データアーキテクチャ、データ管理基盤、データマネジメント組織を論理レベルで設計します。
あるべき(To-Be)データアーキテクチャ(論理レベル)は、現行(As-Is)のデータアーキテクチャ(論理レベル)を分析した上で設計します。
その結果を踏まえて、データマネジメントを実現すべくデータマネジメント組織の構築計画と、データマネジメントを実行するデータマネジメント計画を策定します。 - データマネジメント組織の構築
戦略フェーズで策定したデータマネジメント組織の構築計画に従ってデータマネジメント組織を構築します。 - データマネジメント計画の実行
設計フェーズで設計したデータマネジメントプロセスに基づいてデータマネジメント計画を遂行します。
次の図は、設計フェーズ、戦略フェーズ、構築_運用フェーズの各フェーズにおけるデータマネジメントの成果物を関係づけることによって、データマネジメントの活動の流れを示したものです。
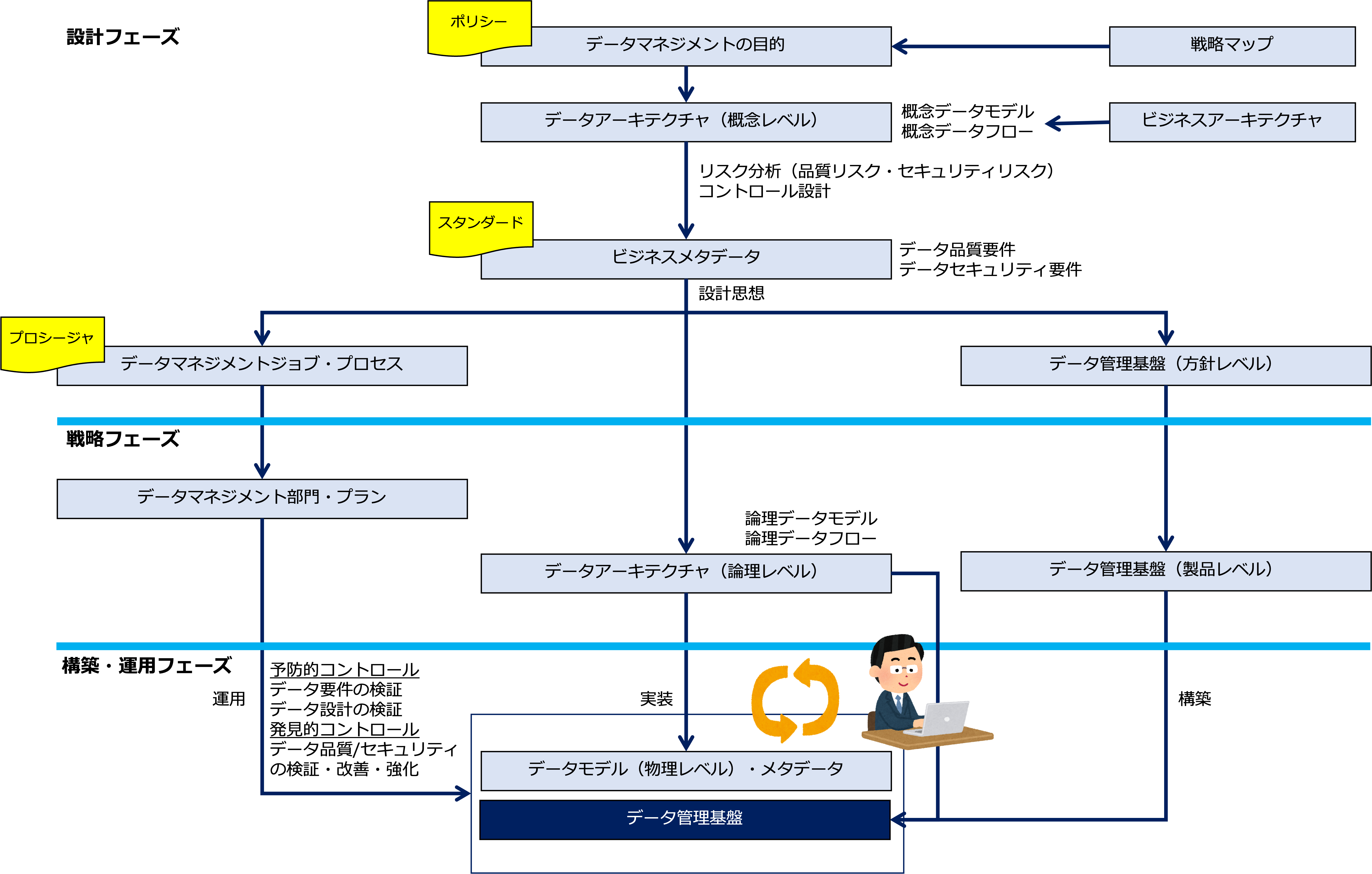
- まず、データマネジメントの目的は、戦略マップで定義した戦略目標を実現するために重要なデータの品質、セキュリティ、経済性を維持、向上させることで、これは、データマネジメントのポリシーになります。
- 次に、戦略目標を実現するために重要なデータ間の構造(静的モデル:概念データモデル)とフロー(動的モデル:概念データフロー)をデータアーキテクチャ(概念レベル)として設計します。
なお、データアーキテクチャ(概念レベル)は、ビジネスアーキテクチャとして設計された資産、組織、業務フローを参照して設計します。 - 続いて、概念データフローと概念データモデルを参照してデータ品質リスクとデータセキュリティリスクを洗い出し、それぞれのコントロールを設計します。
- リスクに対するコントロールは、リスクに対する標準的な対応方法、データマネジメントのスタンダードとしてビジネスメタデータのデータ品質要件やデータセキュリティ要件として定義されます。
- ビジネスメタデータとして定義されたデータ品質要件やデータセキュリティ要件は、データマネジメントジョブ、データマネジメントプロセス、および、データ管理基盤設計方針の設計思想になります。
データマネジメントプロセスを設計することによって、データマネジメントのプロシージャが定義されます。 - 次に、戦略フェーズで、ビジネスメタデータのデータ品質要件やデータセキュリティ要件を実現するデータアーキテクチャ(論理レベル)を設計します。
- 戦略フェーズでは、設計フェーズで設計したデータマネジメントジョブ、データマネジメントプロセスをデータマネジメント部門、データマネジメントプランに展開し、データ管理基盤設計方針を参照してデータ管理基盤の製品を選定します。
- 構築フェーズでは、データ管理基盤の製品を導入し、データ管理基盤を構築するとともに、データアーキテクチャ(論理レベル)をデータモデル(物理レベル)に展開し、テクニカルメタデータ、および、オペレーショナルメタデータを定義します。
- なお、論理レベルのデータフローは、物理レベルのデータパイプラインに展開され実装されます。
- そして、運用フェーズでは、データマネジメントプランに従って、アプリケーション開発の過程で定義されるデータ要件や、データ設計(データモデルとテクニカルメタデータ、および、オペレーショナルメタデータ)を検証するとともに、アプリケーション構築後、データ管理基盤上のデータの品質やセキュリティを検証し、データを改善、強化します。
アプリケーション開発の過程でデータ要件やデータ設計、データ管理基盤の設計を検証する活動は、リスクマネジメントでいうと予防的コントロールになり、アプリケーション構築後、データ管理基盤上のデータの品質やセキュリティを検証し、データを改善、強化する活動は、発見的コントロールになります。
なお、データの品質を検証することをデータのプロファイリングといい、データを改善する方法の一つにデータのクレンジングがあります。
データマネジメントの活動を、データのライフサイクル(計画→設計・実装→生成・収集→保存・維持・破棄→利活用→改善・強化)に対応付けると、
- データマネジメントのポリシー、スタンダード、プロシージャを定義する設計フェーズの活動がデータの「計画」
- 戦略フェーズで、データアキテクチャ(論理レベル)、データ管理基盤(製品レベル)を設計し、構築フェーズで、それぞれ実装、構築する活動がデータの「設計・実装」
- 運用フェーズで、データ管理基盤上のデータを生成・収集し、保存・維持・破棄するのが、データの「生成・収集」、「保存・維持・破棄」
- データを利活用するのが「利活用」
- データの品質やセキュリティを検証、改善、強化する活動がデータの「改善・強化」
になります。
最後に、データマネジメント導入のアプローチですが、次のようになります。
- 概念レベルのモデルの設計(①)
まず、概念レベルのあるべき将来モデルを設計します。 - 論理レベルのモデルの設計(②)
次に、論理レベルのあるべき将来モデルを設計します。 - 論理レベルのモデルのギャップ分析(③)
次に、論理レベルのあるべき将来モデルと現行のモデルのギャップを分析します。 - システムの構築と運用
論理レベルのモデルのギャップ分析の結果を踏まえて、システムを構築、運用します。
システムを構築する場合、次の2つの方法があります。- 既存のシステムをベースに構築する場合(④-a)と、
- 新規にシステムを構築する場合(④-b)があります。
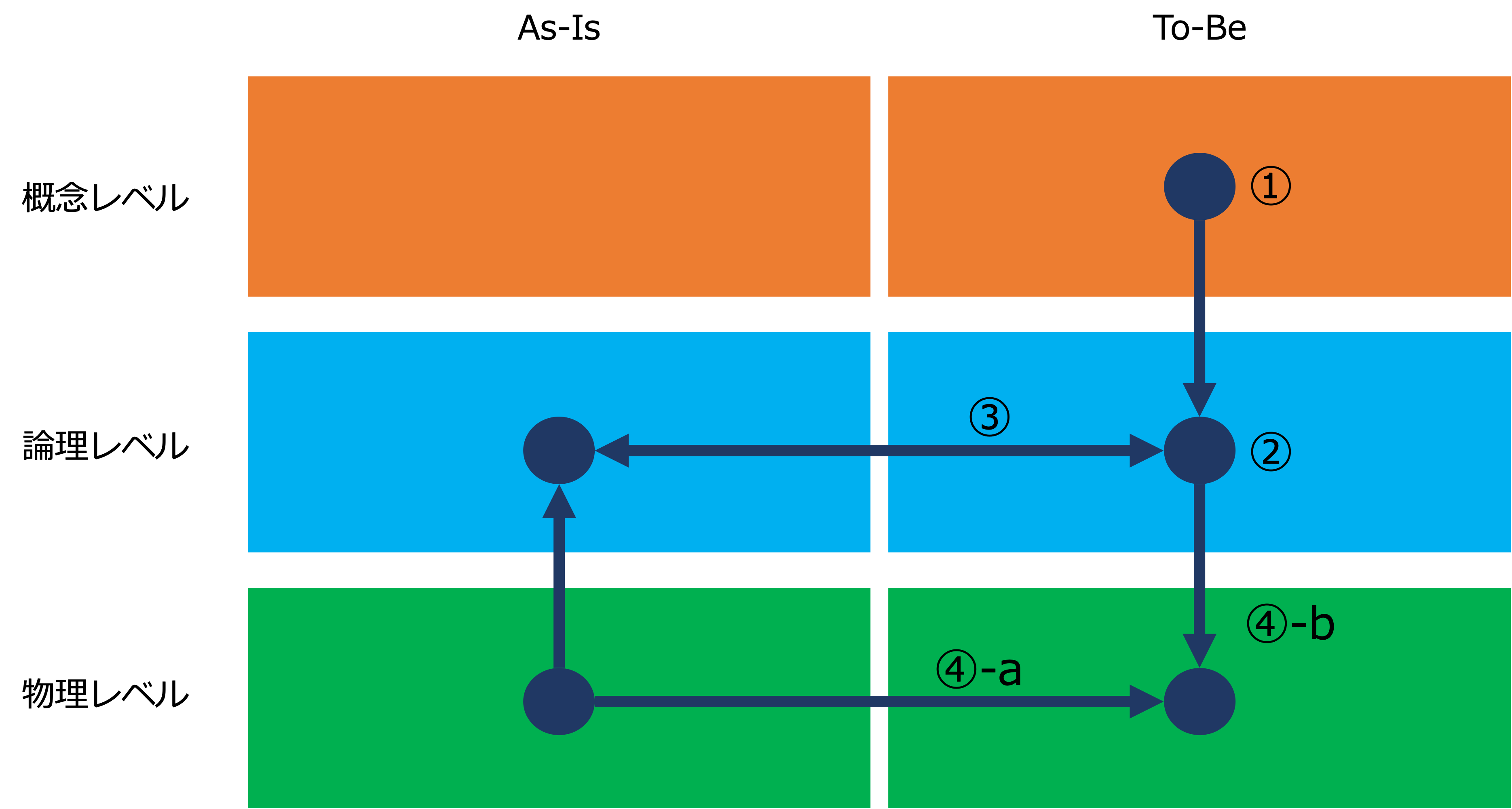
ポイントは、まず、概念レベルのモデルを、全社レベルで広く粗く明確にし、それから粒度を細かくしていくトップダウンアプローチをとることで、漏れなくダブりなく、企業全体で最適なシステムを構築することができるということです。
概念レベルのモデルは、業務の視点のモデルです。
なので、トップダウンアプローチをとることで、対象の業務を漏れなくダブりなく反映したモデルをつくることができます。
反対に、粒度の細かい現行の物理レベルのモデルから現行の論理レベルのモデルを抽出するというボトムアップアプローチをとると、モデル化すべき業務が漏れ、何度もやり直すことになり、経験則上、そこで疲弊してしまい先に進めなくなります。
なので、最初に現行の論理レベルのモデルを網羅するのではなく、論理レベルの将来モデルをベースに、それと比較できる現行モデルの部分だけ可視化するようにします。
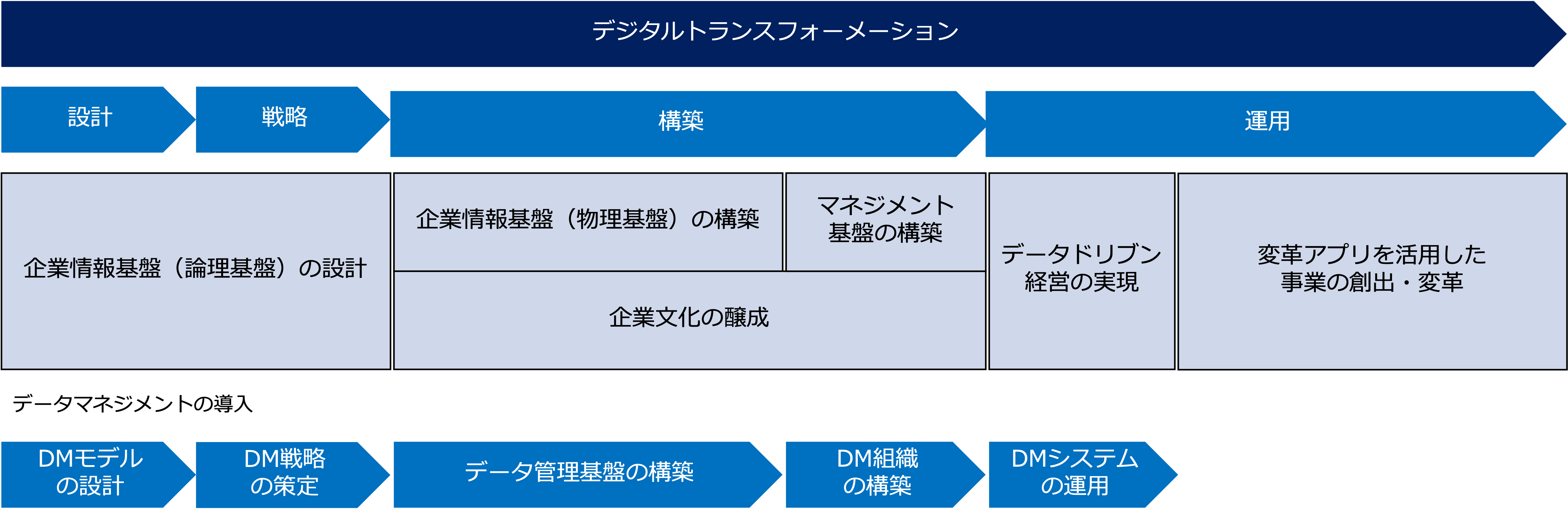
それから、データマネジメントはDXの一環として導入される場合もあり、DXのプロセスの中で考えると次の図のようになります。
データマネジメント支援サービス
弊社では、DXの一環としてデータマネジメントの導入を支援するサービスを実施しています。
本サービスの内容は次のようになります。
- データマネジメント体験ワークショップ
データマネジメント体験ワークショップでは、ワークショップを通して、実際にデータマネジメントの成果物を作成することで、実践的に、貴社のデータ人材を育成します。 - データアーキテクチャ設計代行サービス
弊社で貴社のデータアーキテクチャ設計を代行いたします。 - データカタログ作成代行サービス
弊社で貴社のデータカタログ作成を代行いたします。 - データマネジメント代行サービス
年間のデータマネジメントのデータマネジメントシステム運用計画に従って、次の運用タスクを代行いたします。
企業の担当者の方へ
一度、詳細をご説明いたします。
お問い合わせは以下のメールアドレスにお願いいたします。
culnou_dm@culnou.com


[…] 記事データマネジメントのデータマネジメントの導入アプローチでは& […]
[…] ;ュリティを管理するのがデータマネジメントです。 さらに、内部の視 […]
[…] ;タアーキテクチャがなくデータマネジメントを進めるというのは、地& […]
[…] データは、個別のシステムで生成され管理されますが、企業全体でデータを一元管理したい場合、データを一箇所に集約して分析しやすい形に変換して利活用します。 この、企業全体でデータを一元管理するための基盤をデータ管理基盤といいます。 また、個別のシステムのデータベースも含めた範囲を広義のデータ管理基盤といいます。 データアーキテクチャで設計されたデータモデルは、データ管理基盤上に実装されます。 なので、データマネジメントの管理対象には、論理的基盤であるデータアーキテクチャと、それを実装し管理する物理的基盤であるデータ管理基盤があるのです。 それでは、データ管理基盤を構成する要素を一つひとつ見ていきましょう。 […]
[…] ;をどうしたいのか(データマネジメントの成熟度)、データマネジメ& […]
[…] ;ッグデータの文脈でデータマネジメントの重要性がさけばれて久しい& […]