
変化が激しく、不透明で先行きが予測できない昨今の経営環境を、
Volatility(変動性)
Uncertainty(不確実性)
Complexity(複雑性)
Ambiguity(不透明性)
の頭文字をとってVUCA(ブーカ)という言葉で表すことがあります。
それは、SNSやモバイル技術によって人と人がつながる時間や距離が短くなったことで、個人の欲望や考えが、複雑なネットワークを介してすぐに世界中に広がり、いつどこで、どんな需要が生まれるか読みづらく、欲求の新陳代謝も激しくなっているからではないでしょうか。
このように、先行き不透明で予測困難な時代、経験や勘に頼るのではなく
稼ぐ力を持つ資産としてのデータをどう利活用してくか
ということが会社を発展させていくための重要な課題となっています。
「データは新しい石油(Data is the new oil)」と言われています。
会社に眠っているデータを、人やAIが、いかにうまく利活用して企業価値を生み出すことができるかが重要なのです。
ところで、データにはライフサイクルがあるということはご存知でしょうか。
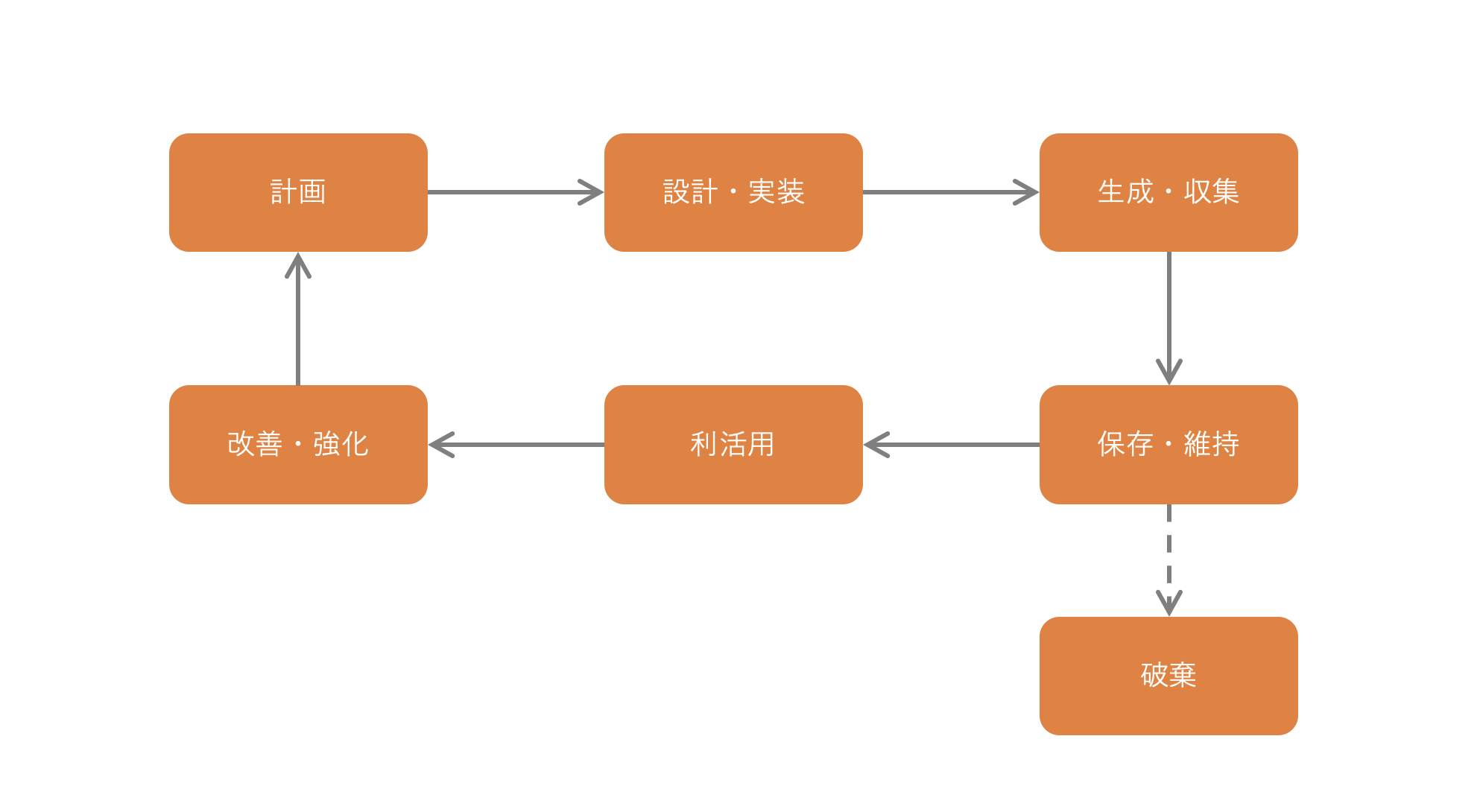
このデータのライフサイクルの中で、データが直接経済価値を生む活動は「データ利活用」です。
しかし、事業戦略を実現するために必要なデータを特定し、それを、どう取得し、どう活用するか考える計画活動がなければ、会社にとって必要なデータを計画的に取得し活用することはできません。
また、会社全体のデータを設計、実装し、生成、収集しなければ、適切な人が、適切なタイミングで、適切なデータを、適切な形式かつ適切な詳細度で活用することはできません。
間違ったデータの活用は、間違った意思決定につながりますし、誰もが機密データにアクセスできるようであればデータの漏洩リスクが高くなります。
さらに、データを適切に保存、維持しなければ、重要なデータが喪失する可能性もあります。
データを利活用するためには、データのライフサイクルを全体を通して、データを適切に管理するデータマネジメントが必要なのです。
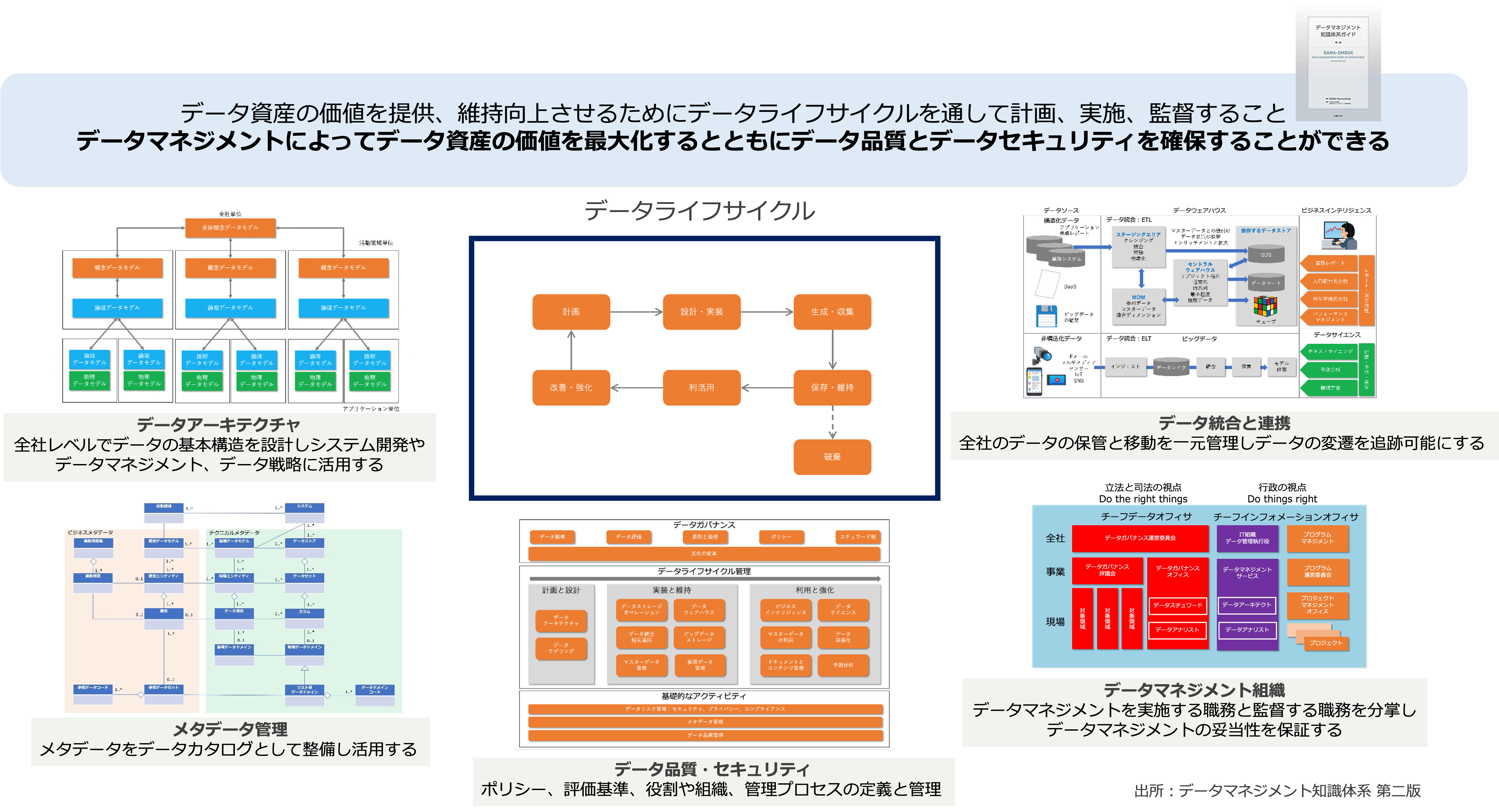
データマネジメントに関する知識を体系立ててまとめた書籍にデータマネジメント知識体系(DMBOK)があります。
DMBOKでは、セキュリティや品質が確保されていないデータがもたらす事象として以下の例をあげています。
- 誤請求
- 顧客サービスコールの増加とそれを解決する能力の低下
- 事業機会の逸失による収益損失
- 合弁・買収の間に発生する業務統合の遅延
- 不正行為発覚の増加
- 不正なデータに起因する業務上の意思決定不備がもたらす損失
- 良好な信用力の欠如による事業の損失
データを保護し、その品質を確保してデータの資産価値を維持向上させるためのデータマネジメントはとても重要なのです。
ここでは、DMBOKをベースに、データマネジメントについて次の観点で解説します。
関連記事
データマネジメントの導入方法
なぜデータマネジメントが必要なのか
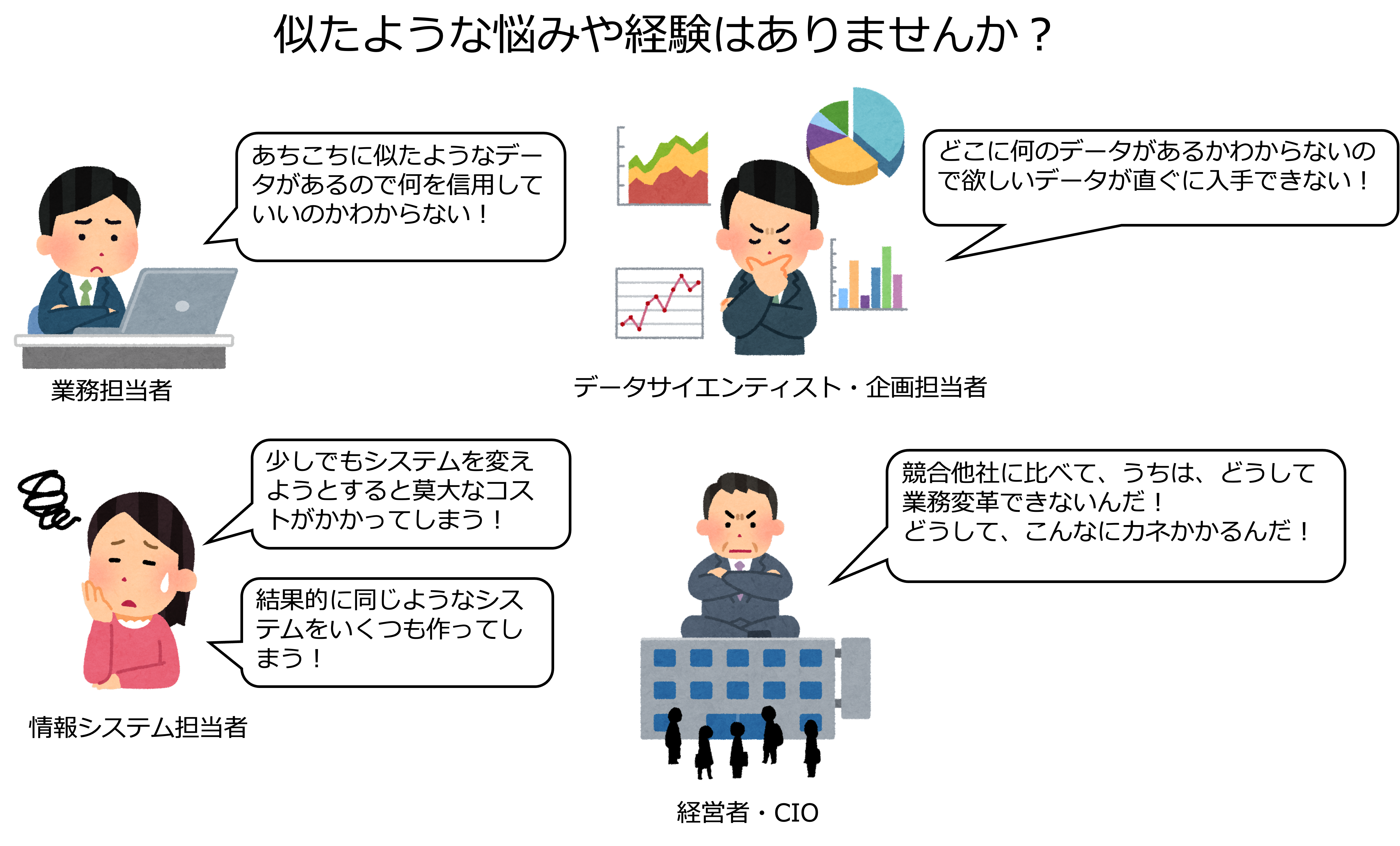
これらの問題は、データマネジメントによって解決することができます。
あちこちに似たようなデータがあるので何を信用していいのかわからない!
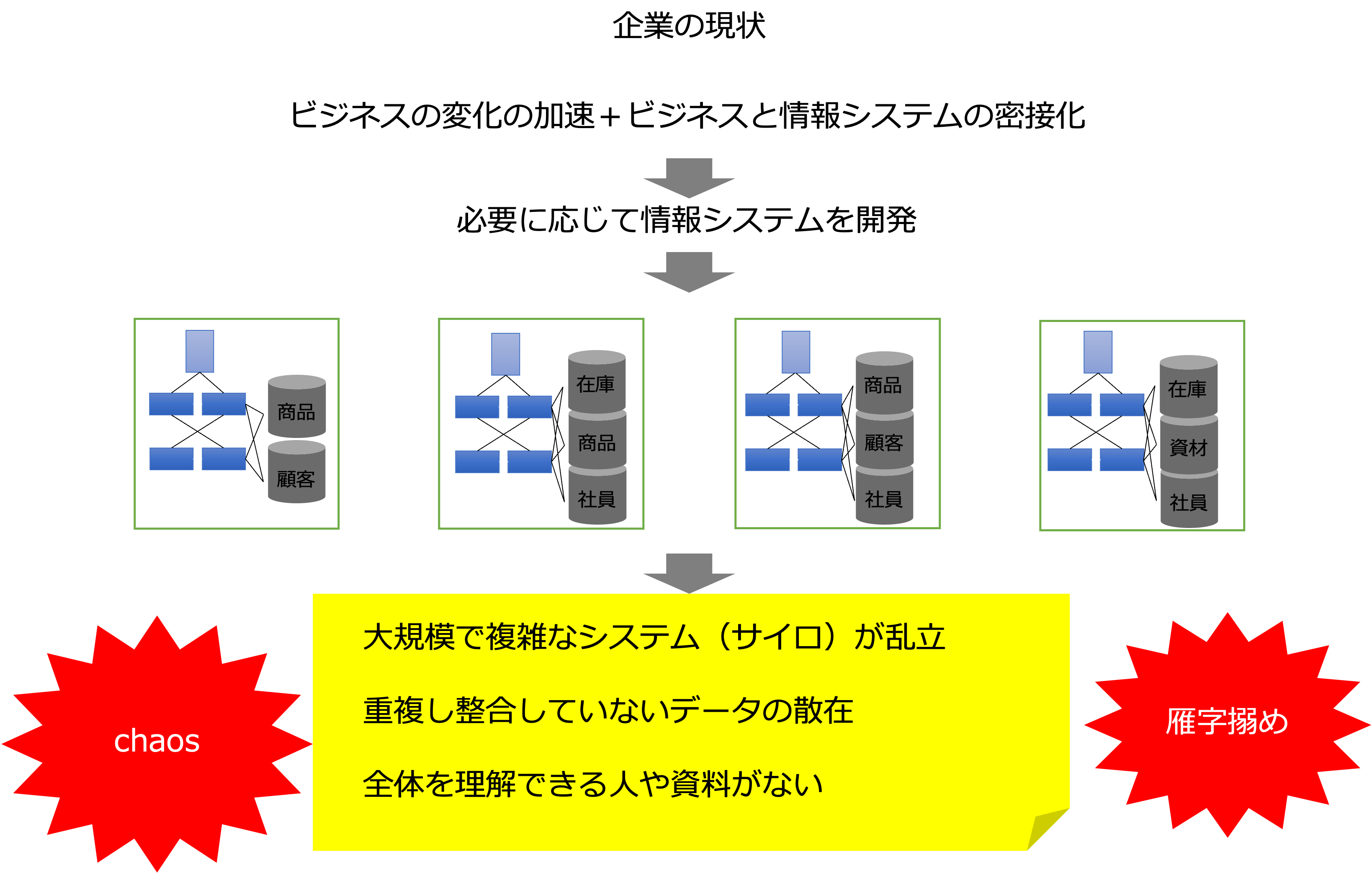
多くの会社が、
ビジネスの変化が加速し、ビジネスとITが密接化する中、全体の設計図もなく、必要に応じてシステムを導入してきた結果、
- 大規模で複雑なシステムがサイロのように乱立している
- 重複して整合していないデータが散在している
- 個別の業務やシステムは詳しいが全体を理解できる人や資料がない
というカオスで雁字搦めな状況に陥っています。
経済産業省が2018年に出したDXレポート ~ITシステム「2025年の崖」の克服とDXの本格的な展開~では、企業がDXに対応できない現状を次のように説明しています。
- 既存システムが、事業部門ごとに構築されて、全社横断的なデータ活用ができなかったり、過剰なカスタマイズがなされているなどにより、複雑化・ブラックボックス化している
- 経営者がDXを望んでも、データ活用のために上記のような既存システムの問題を解決し、そのためには業務自体の見直しも求められる中(=経営改革そのもの)、現場サイドの抵抗も大きく、いかにこれを実行するかが課題となっている
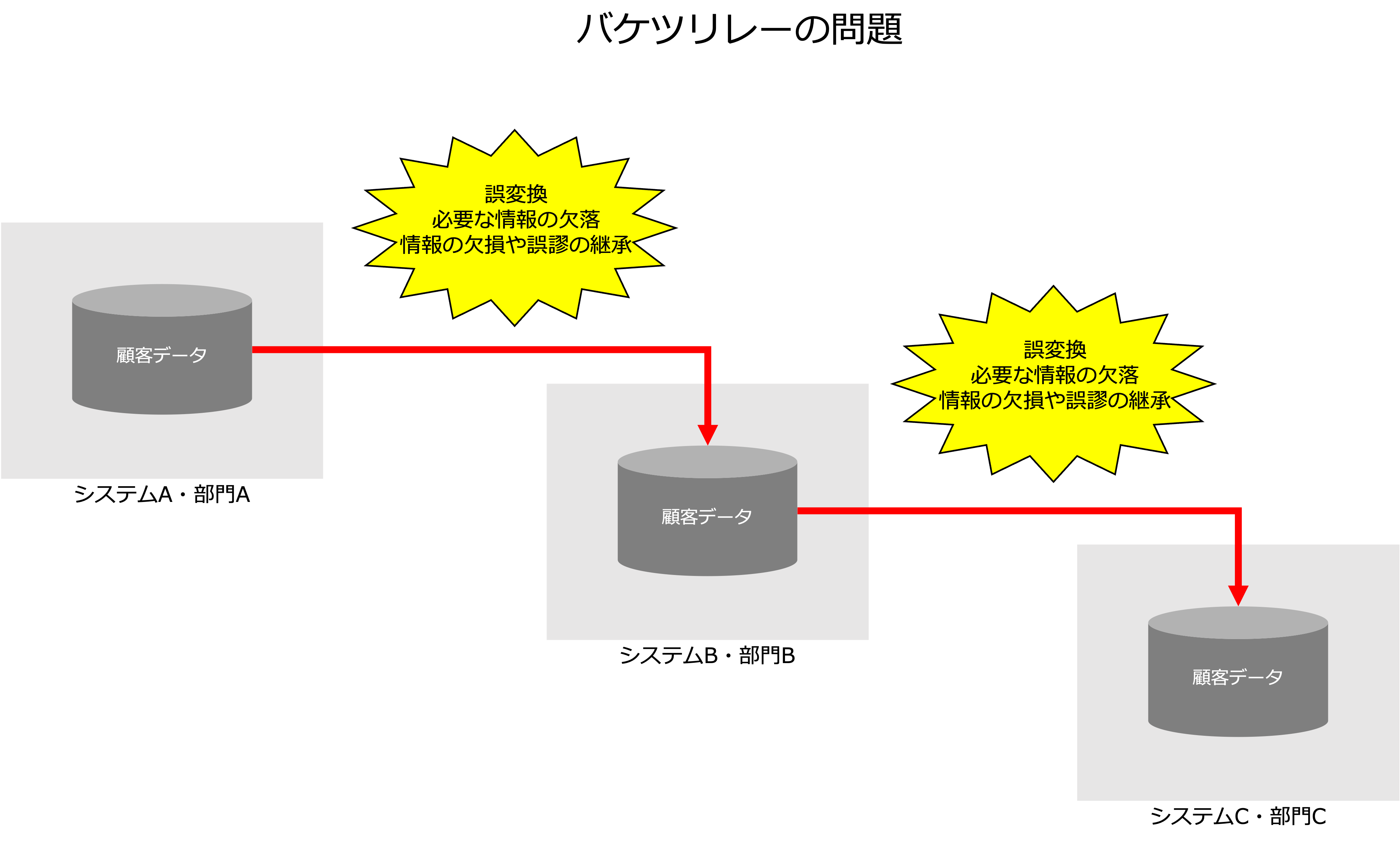
それから、データが散在しているだけでなく、データがバケツリレーのようにコピーされ活用されていると、
- 誤変換
- 必要な情報の欠落
- 情報の欠損や誤謬の継承
という問題も発生します。
データの品質が低いと、誤請求や不正なデータに起因する業務上の意思決定不備がもたらす損失などをもたらす可能性があります。
データマネジメントによって、散在したデータを統合し、会社全体で一元管理することで、データの品質とセキュリティを確保することができます。
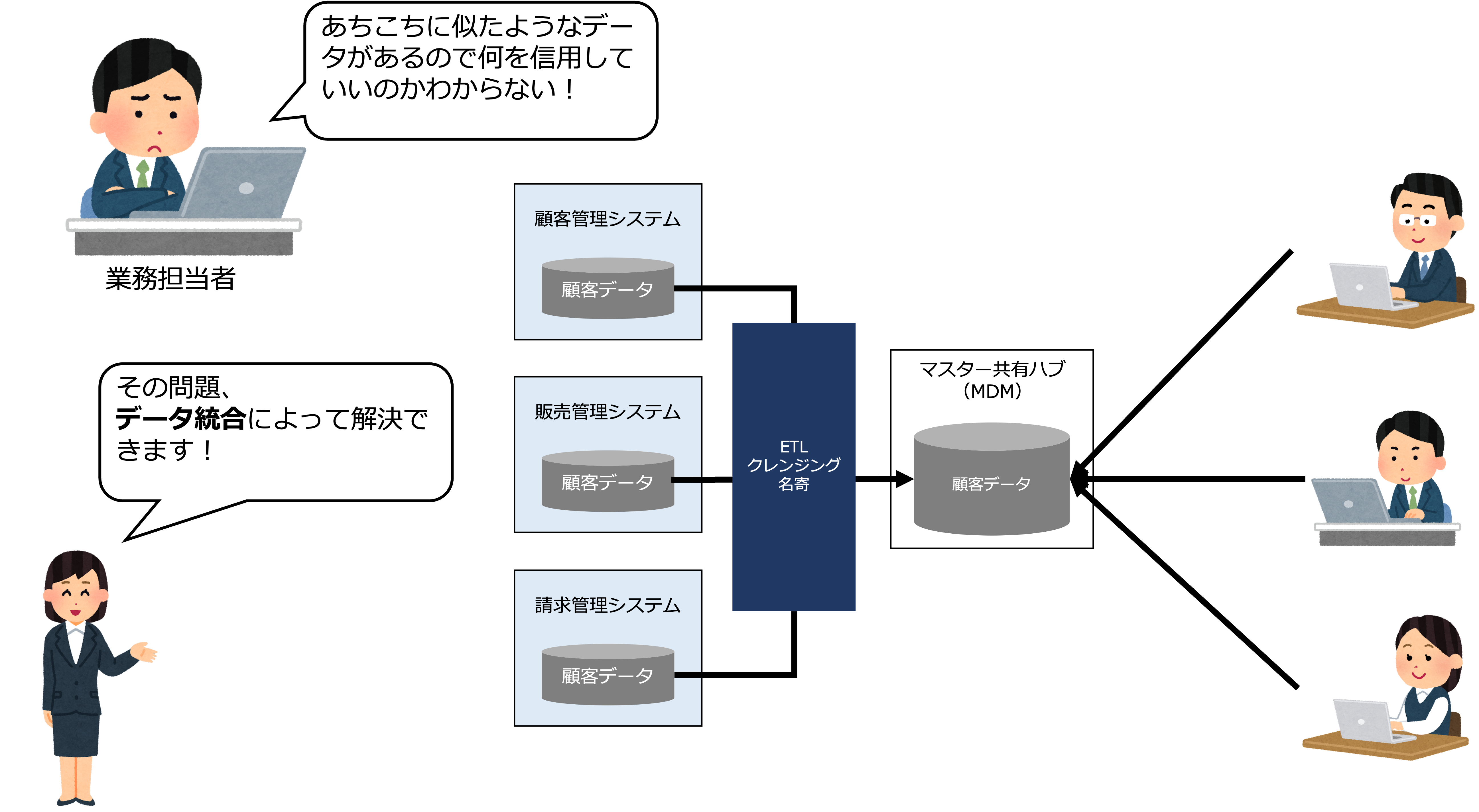
なお、データを統合するときは、名寄(名前や住所などの統合)やデータのクレンジング(破損または不正確なレコードを検出して修正すること)も行います。
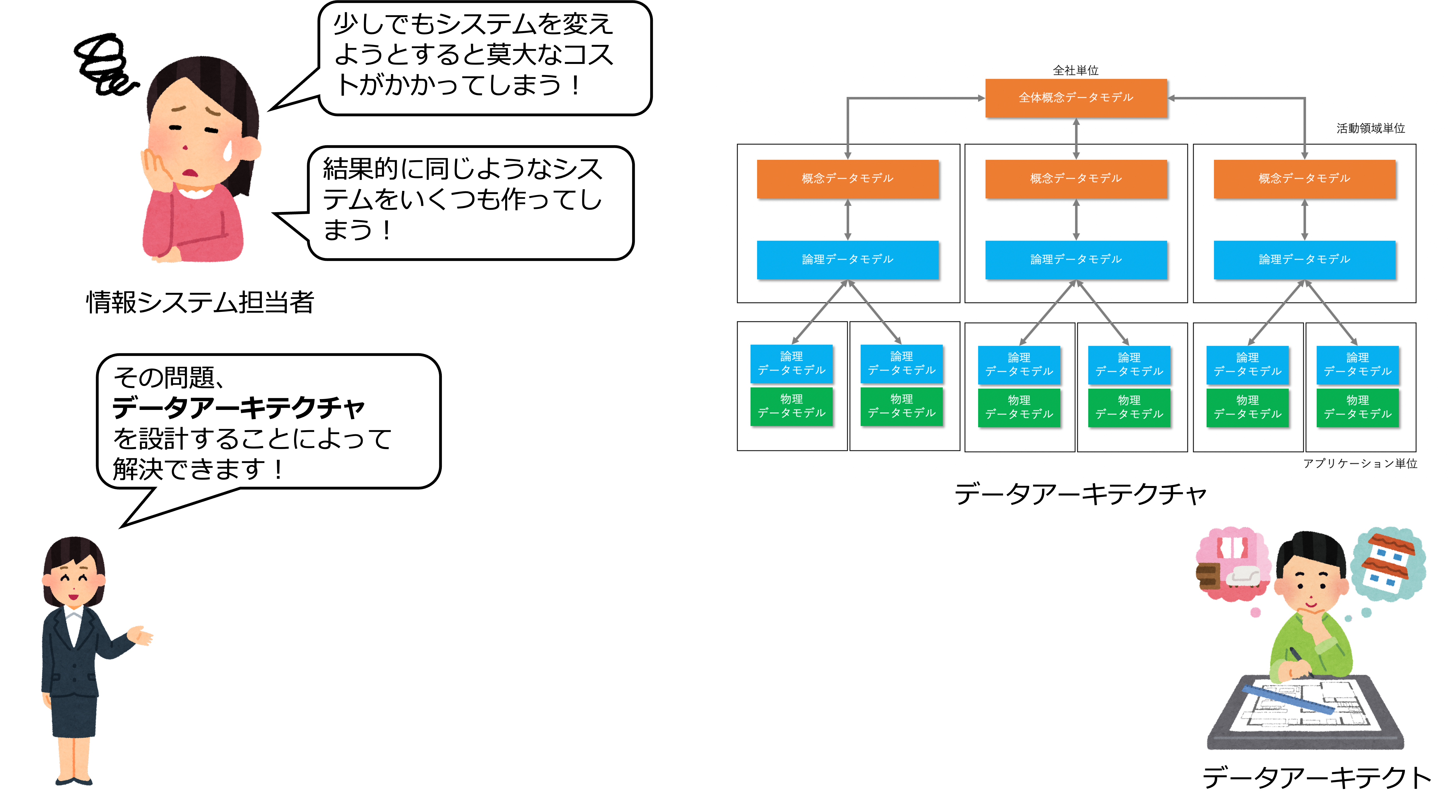
少しでもシステムを変えようとすると莫大なコストがかかってしまう!
多くの会社では、大規模で複雑なシステムがサイロのように乱立しています。
システムは、処理と、処理の対象となるデータによって成り立っています。
システムは、仕様変更を重ねることによって複雑化しています。
なので、処理の仕様とデータの構造が明確に定義されていないと、システム変更に対するリスクが高くなります。
特に、システムのデータ構造は、システムの骨組みになるので、それがわからないと手のつけようがなくなります。
データマネジメントでは、会社全体からシステム単位のデータ構造(データアーキテクチャ)を概念レベル、論理レベル、物理レベルで設計します。
データアーキテクチャを設計することによって、複雑なシステムのデータ構造が見える化され、システム変更のリスクを下げることができます。
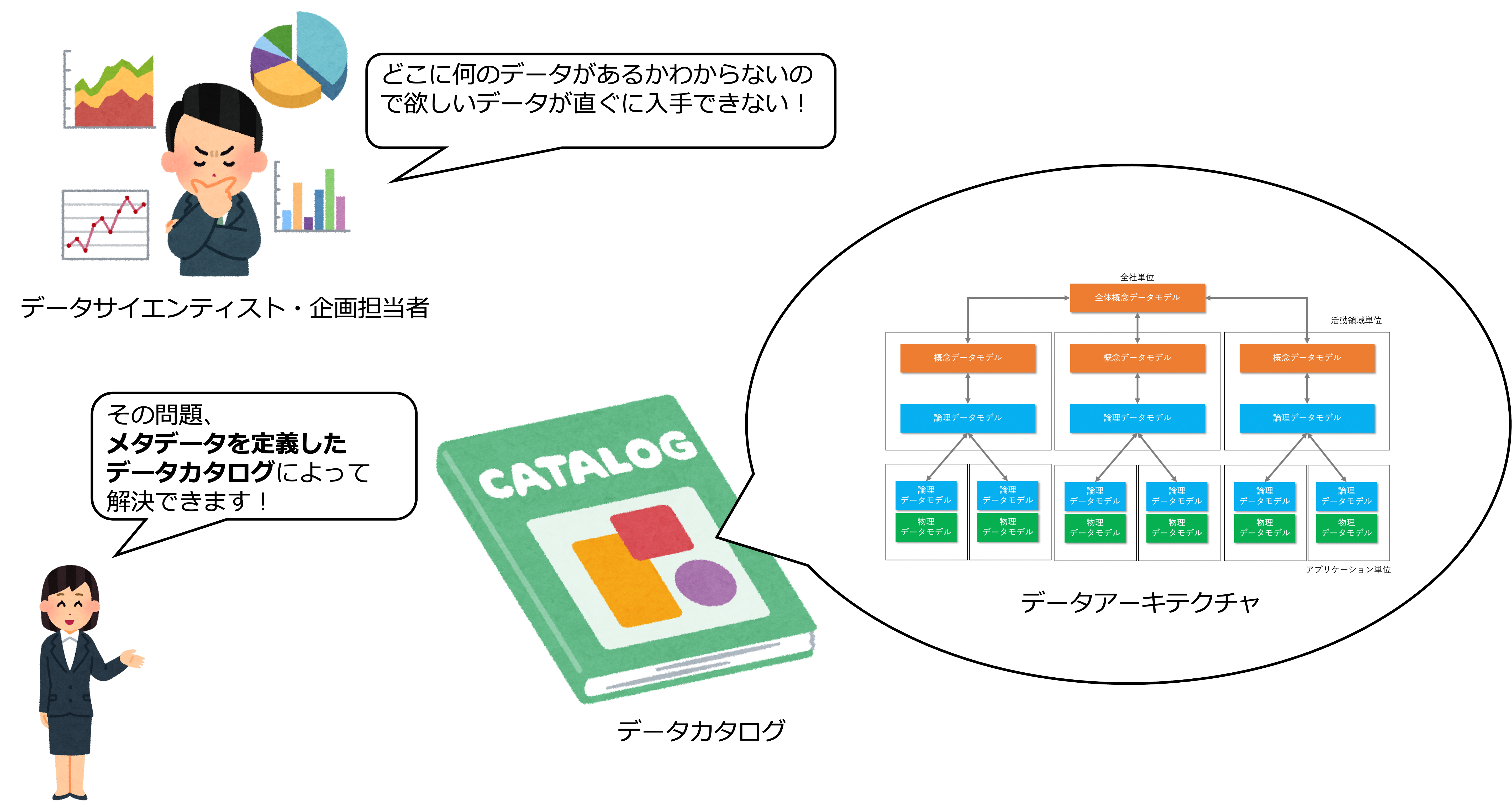
どこに何のデータがあるかわからないので欲しいデータが直ぐに入手できない!
例えば、データ(事実)に基づいて
- 現在起きている現象を説明したいとき
- その原因を探したいとき
- 将来、どうなるか予測したいとき
など、あると思います。
そのようなとき、欲しいデータが直ぐに入手できないと、それに基づく意思決定のスピードが落ちてしまいます。
以下の図は、CRISP-DM(CRoss-Industry Standard Process for Data Mining)という、データサイエンスの一般的なプロセスを表しています。
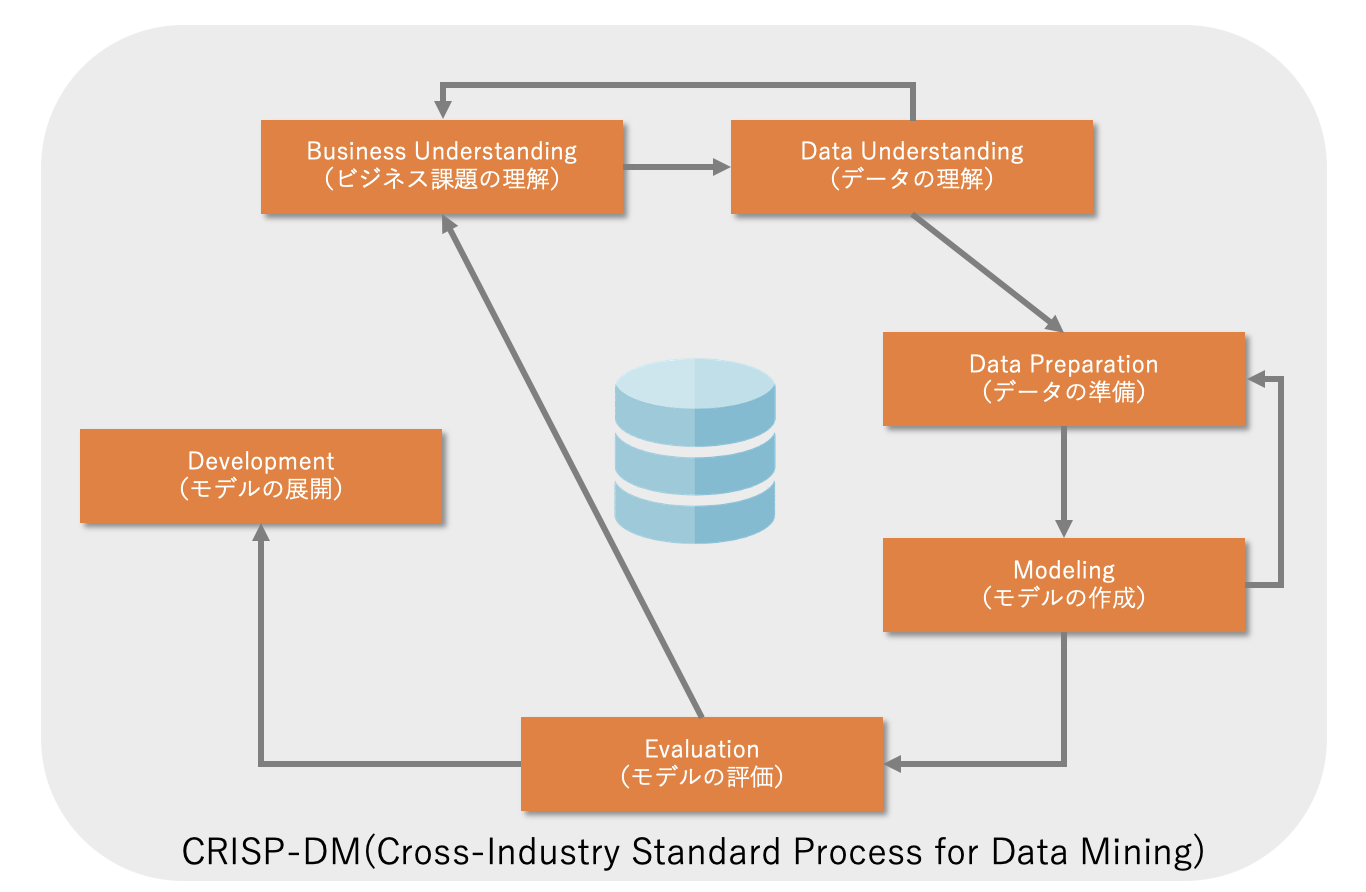
この過程の中で、重要なのはモデルの作成や評価、展開になりますが、実は、現実問題、データの理解や準備に多くの時間が費やされています。
必要なデータがどこにあるかわからない、せっかくデータを入手しても、欠損や誤謬があるので、それを削除、修正する必要がある、などです。
データマネジメントでは、データアーキテクチャで設計されたデータの意味や、所在、使用するときの制約などをメタデータとして定義し、データカタログとして準備します。
データカタログがあることで、データ利用者は、必要なデータを迅速に入手し、理解することができるようになります。
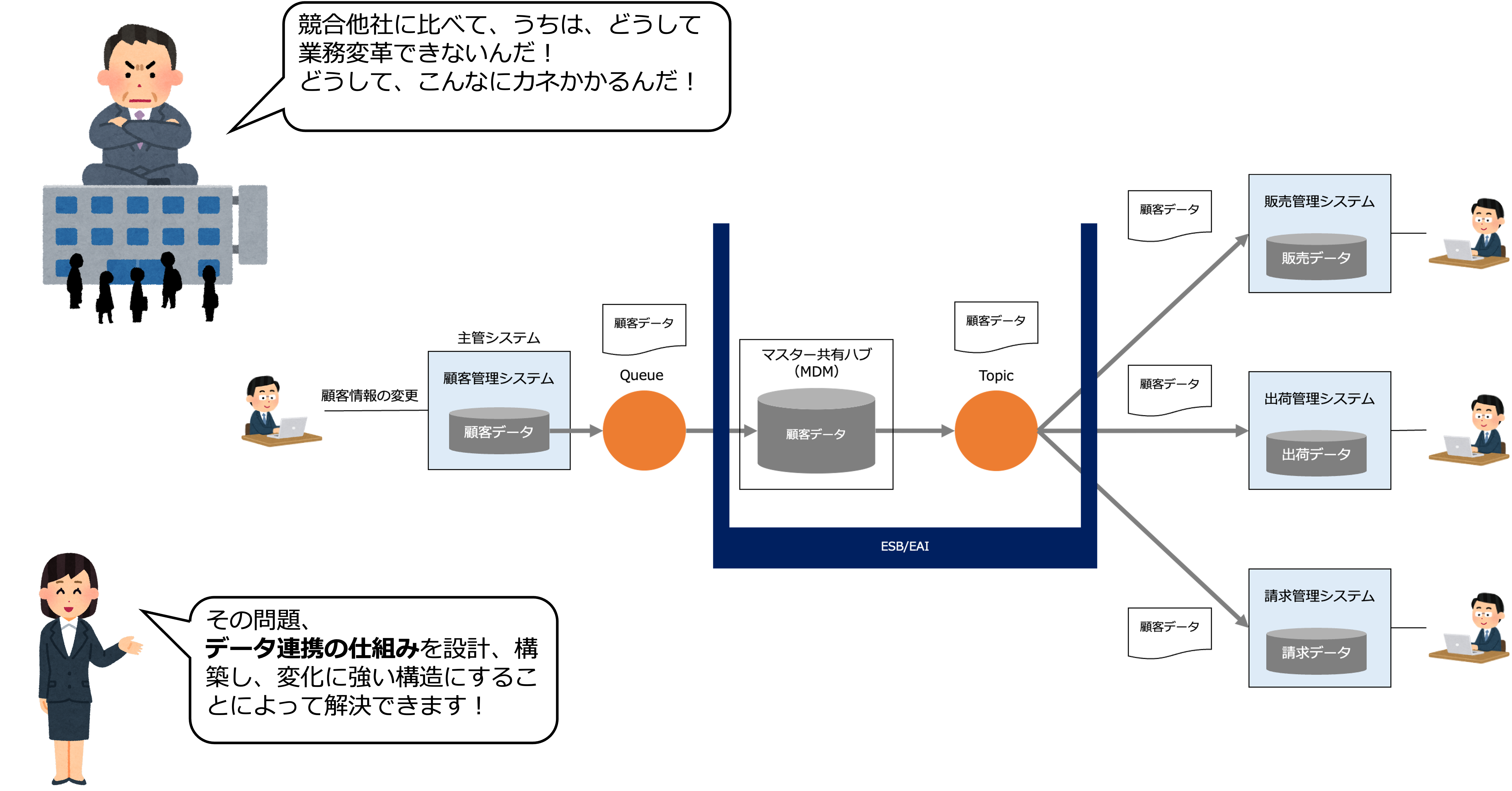
競合他社に比べて、うちは、どうして業務変革できないんだ!
先程言及したように、多くの会社では、ビジネスの変化が加速し、ビジネスとITが密接化する中、全体の設計図もなく、必要に応じてシステムを導入してきた結果、業務とシステムがカオスで雁字搦めな状態になっています。
データマネジメントでは、統合されたマスターデータや、各システムのトランザクションデータのデータ連携を設計、構築します。
各システム同士が、APIやQueueを使った同期、非同期通信をすることで、互いに疎結合することができ、システム開発の保守性や生産性を向上することができます。
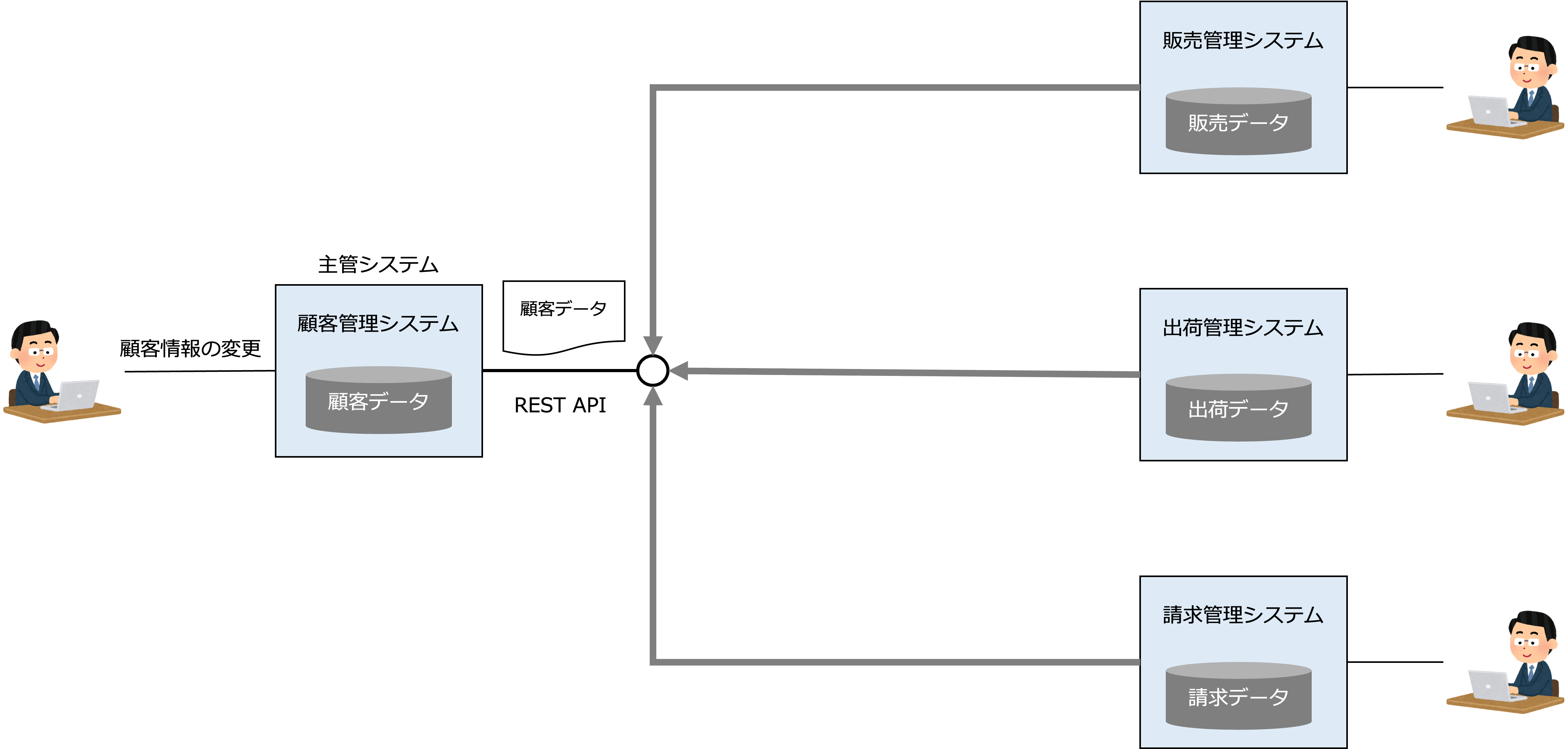
例えば、データ構造が変わった場合、データに関連するシステムは影響を受けますが、そのシステムを利用するシステムは響受けないので、高い保守性を実現することができるとともに、新しいシステムを開発するとき、すでに在るシステムを部品として再利用することができるので、開発の生産性が上がり、企業を変化に強い構造にすることができます。
APIによる同期通信の例
メッセージングによる非同期通信の例
アプリケーションの連携形態でも説明していますが、相手のレスポンスの結果がリアルタイムに必要ではない場合、アプリケーション間の疎結合を実現する非同期通信を選択することをお勧めします。
データマネジメントとは何か
データマネジメント知識体系(DMBOK)では、データマネジメントを、
データという資産の価値を提供し、管理し、守り、高めるために、それらのライフサイクルを通して計画、方針、スケジュール、手順などを開発、実施、監督すること
と定義しています。
また、DMBOKでは、データマネジメントのゴールを次のように設定しています。
- 自社や顧客、従業員、ビジネスパートナーを含むステークホルダーの情報ニーズを理解し、サポートする
- データ資産を取得し、保管し、保護し、健全性を担保する
- データの品質を担保する
- ステークホルダーが保有するデータのプライバシーと機密性を確保する
- 不正または不適切なデータへのアクセス、操作、使用を防止する
- 企業が付加価値を創造するためにデータを効果的に利用できるようにする
なので、データマネジメントとは、データを
- セキュリティ
データの機密性、完全性、可用性が確保できているか - 品質
データの正確性、完全性、一意性、一貫性、適時性など、データがどれだけ信頼できるか - 経済性
データが、どれだけ経済価値を生み出せるか
という観点から評価し、それらを維持向上させる活動ということになります。
そして、データマネジメントが機能するかどうかは、データは価値を生み出す重要な資産であるという価値観が風土として組織にどの程度浸透しているかどうかによって決まるのです。
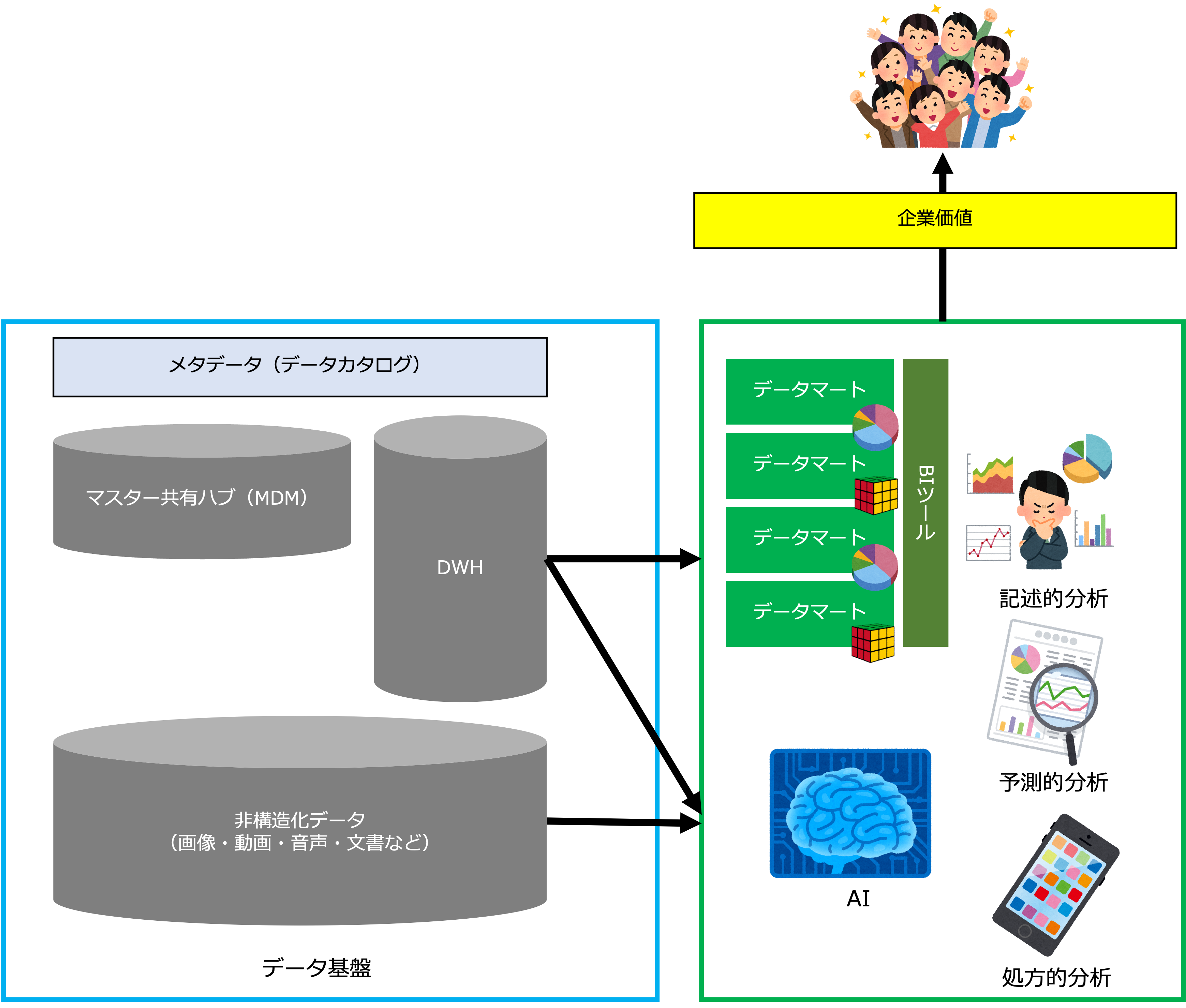
さて、データライフサイクル全体を管理するデータマネジメントのイメージは、次の図のようになります。
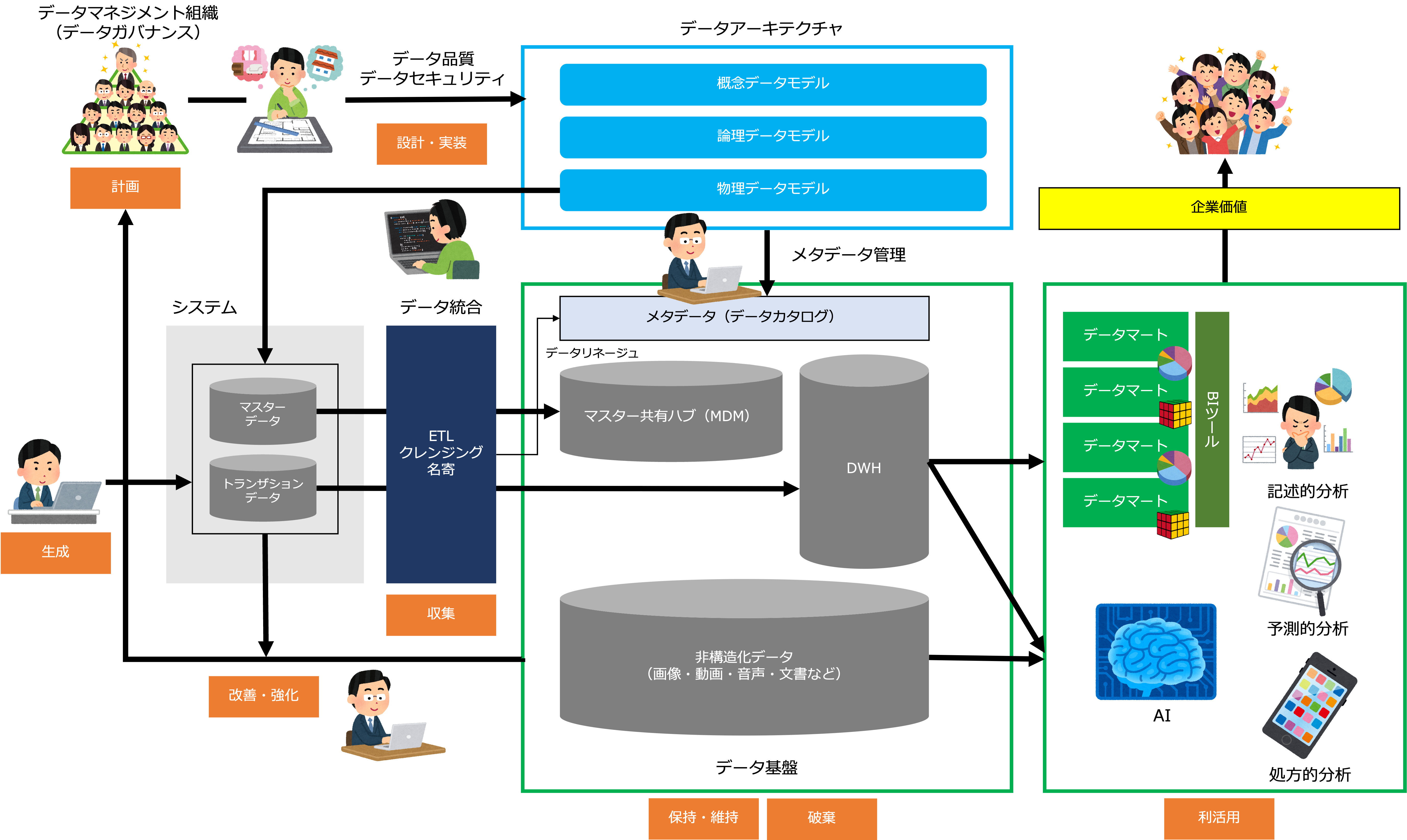
- まず、データ品質、データセキュリティを考慮して会社のデータアーキテクチャを設計し、データ管理基盤を構築します。
- データマネジメント組織は、データアーキテクチャを参照して戦略上重要なデータに関する計画を立案します。
- データ計画に基づいて、データアーキテクチャを更新します。
- データアーキテクチャの内容は、メタデータとして定義されます。
- データアーキテクチャの物理データモデルは、システムのデータベースとして実装されます。
- データベースに生成されたデータは、データ基盤に収集され、保管、維持、必要に応じて破棄されます。
- データ基盤のデータは、人やAIによって利活用され企業価値を生み出すとともに、継続的に改善・強化されます。
データマネジメントは、大きく、物理的基盤であるデータ管理基盤と、論理的基盤であるデータアーキテクチャに分けることができます。
一つ一つ見ていきましょう。
データ管理基盤
データ管理基盤とは、データを管理するための物理的な基盤のことです。
全社データ管理基盤のイメージは次のようになります。

データ管理基盤は、データ基盤、データ分析環境、データ連携基盤から構成されます。
データ基盤
データ基盤は、データ管理基盤の中核になるもので次の要素から構成されます。
- マスター共有ハブ
企業のマスターデータを一元管理する基盤です。
マスター共有ハブは、マスターデータ管理(MDM)のソリューションの一つです。 - 非正規化データ(生データ)
企業の記録システム(SoR)のデータは、正規化されています。
データが正規化されると効率的に更新することができますが、データがばらばらになっているため検索にコストがかかります。
データを分析するときは様々な視点でデータを検索します。
データを非正規化することで、効率的に検索できるようにしたデータを、非正規化データ(生データ)といいます。
非正規化データ(生データ)は、更新されることがなく、データウェアハウス(データの倉庫)に蓄積されていきます。
また、非正規化データ(生データ)は、ブロックチェーンで管理される場合もあります。 - 非構造化データ
画像、動画、音声、文書、AIモデルなど、データの形式や内容に決まりを設けず管理されるデータのことです。 - 半構造化データ
半構造化データとは、表形式で構造化されたリレーショナル・データベースのテーブルのような厳密な構造を持たないが(例えば、データの値の長さや形式がバラバラ)、一定の構造や規則性があるデータの形式を指します。
半構造化データは、通常、NoSQLデータベースで管理されます。 - メタデータ
メタデータとは、データを管理するためのデータのことで、メタデータをデータカタログとして管理することで、必要なデータの有無や所在、使うときの制約を知ることができます。
データ分析環境
データ分析環境は、企業の非正規化データ(生データ)を一元管理するセントラルデータウェアハウスのデータを部門別、目的別に分けたデータマートを構築し、必要な役割の人が必要なデータのみにアクセスすることができるようにした環境のことです。
データ分析環境を構築することで、データの安全性(セキュリティ)を確保することができます。
データ連携基盤の構築
データを連携するEAIやESBなどの基盤のことで、アプリケーション連携基盤と同義です。
データアーキテクチャ
データアーキテクチャは、全社レベルでデータの基本構造であり、データマネジメントに関する意思決定を導く青写真になります。
データアーキテクチャの詳細は、【実践!DX】データアーキテクチャの設計方法を参照してください。
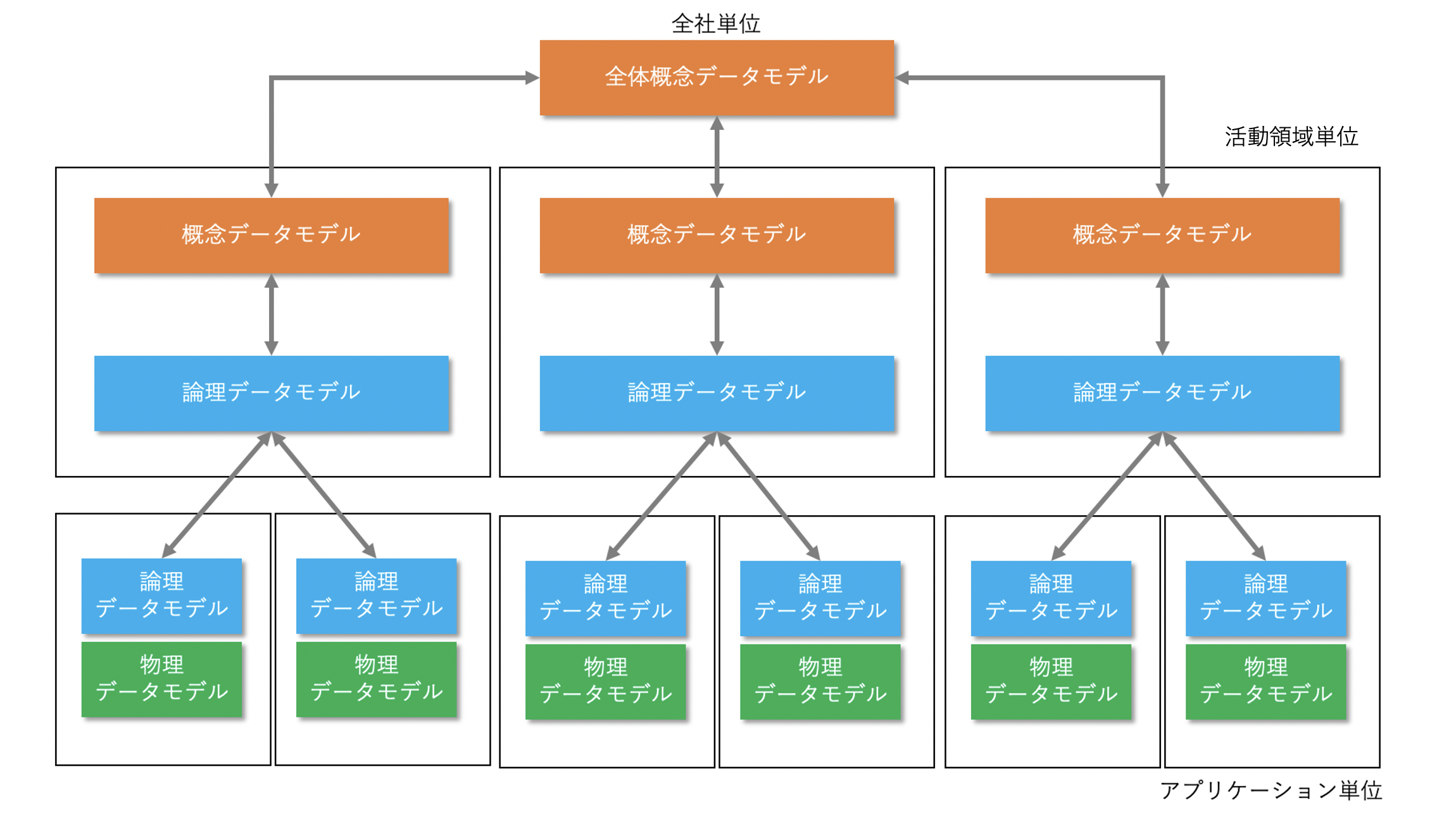
データアーキテクチャは、スコープ(企業全体・業務・システム)×抽象レベル(概念・論理・物理)のデータモデル(データ構造)から構成されます。
データアーキテクチャを構成する概念データモデル、論理データモデル、物理データモデルは、MDAの考え方に基づいています。
データアーキテクチャによって、会社全体のデータ構造を見える化することで、
- どのデータを統合するのか
- どのデータを統制するのか
- どのデータ資産に投資をするか
※データは、システムを構築して社内で生成、収集するだけでなく、外部から購入することもあります。
計画することができるようになります。
さらに、データアーキテクチャをベースにして
- どのようにデータを統合するのか(データ統合)
- どのようにデータを統制するのか(データ品質とセキュリティ)
- 誰がデータを統制するのか(データマネジメント組織)
- どのようにデータ資産を利活用するのか(データ管理基盤)
を考えることができます。
そして、これらの情報は、メタデータとして定義され管理されます。
それぞれ、見ていきましょう。
データ統合と連携
データ統合と連携は、全社のデータの保管と移動を一元管理し、データの変遷を追跡可能にします。
データの変遷は、データリネージュ(データの来歴)としてメタデータに記録されます。
データ統合の設計
データ統合する場合、まず、どのようにデータを統合するか設計する必要があります。
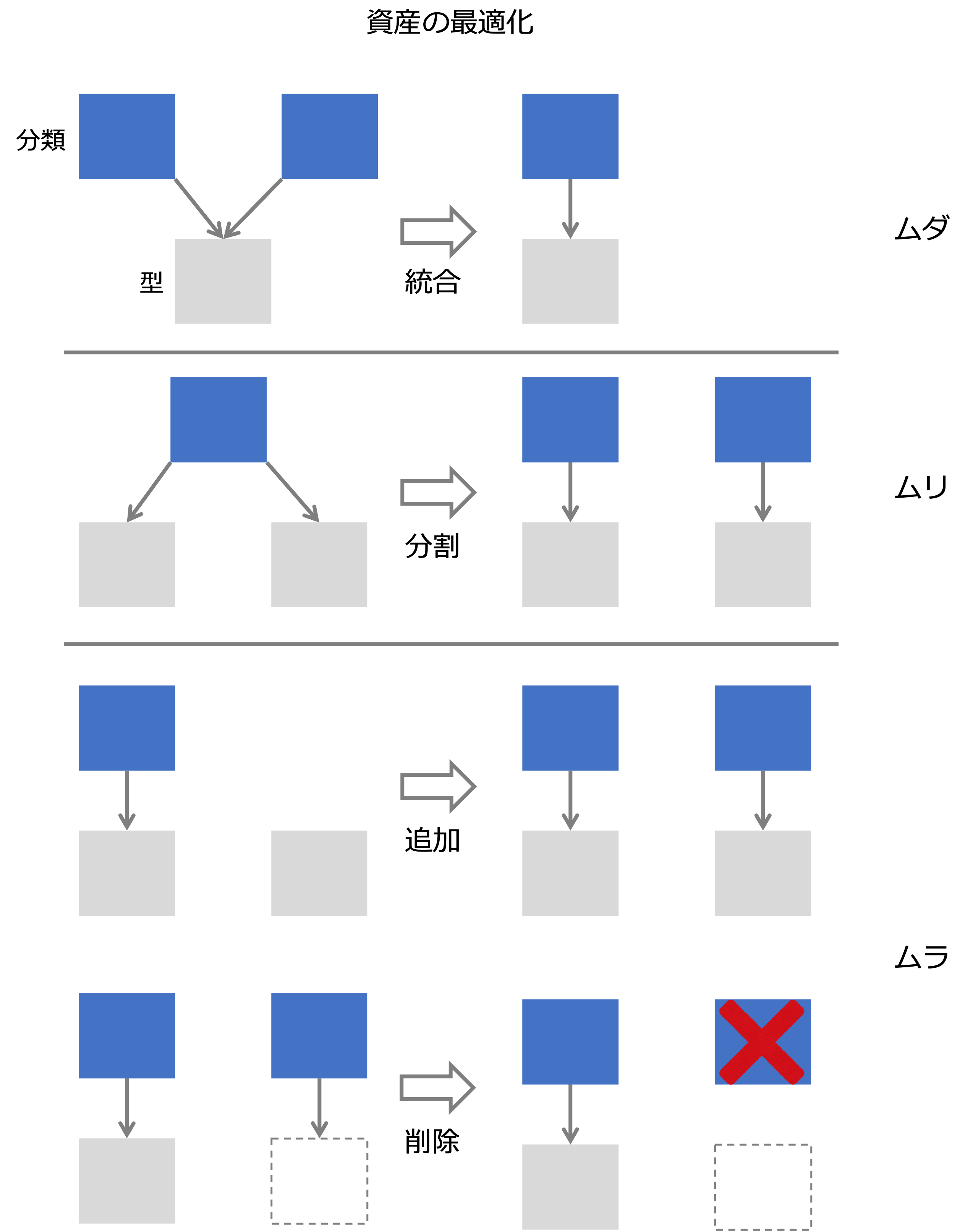
データ統合では、データアーキテクチャに従って、既存のデータを統合、分割、追加、削除することで最適化します。
まず、会社内で☓☓データと呼ばれているデータカテゴリ(データタイプの分類)として洗い出します。
次に、データカテゴリを、データアーキテクチャの構成要素であるデータタイプにマッピングします。
最後に、次の観点でデータカテゴリを最適化します。
- 複数のデータカテゴリが一つデータタイプにマッピングされる場合、ムダが生じているのでデータカテゴリを統合する
統合するときは、データカテゴリのデータ項目が、データタイプのデータ項目に整合しているか確認します。 - 一つのデータカテゴリが複数のデータタイプにマッピングされる場合、ムリが生じているのでデータカテゴリを分割する
分割するときは、データカテゴリのデータ項目とデータタイプのデータ項目を対応させます。 - 必要なデータタイプに対するデータカテゴリがない場合、データカテゴリを追加する
データタイプのデータ項目から追加するデータカテゴリのデータ項目を導きます。 - どのデータタイプにもマッピングされないデータカテゴリがある場合、データカテゴリの削除(廃止)を検討する
データフローの設計
また、データ統合の一環として、どのタイミングで、どのシステムの何のデータがどのように移動するのか、データフローを設計する必要があります。
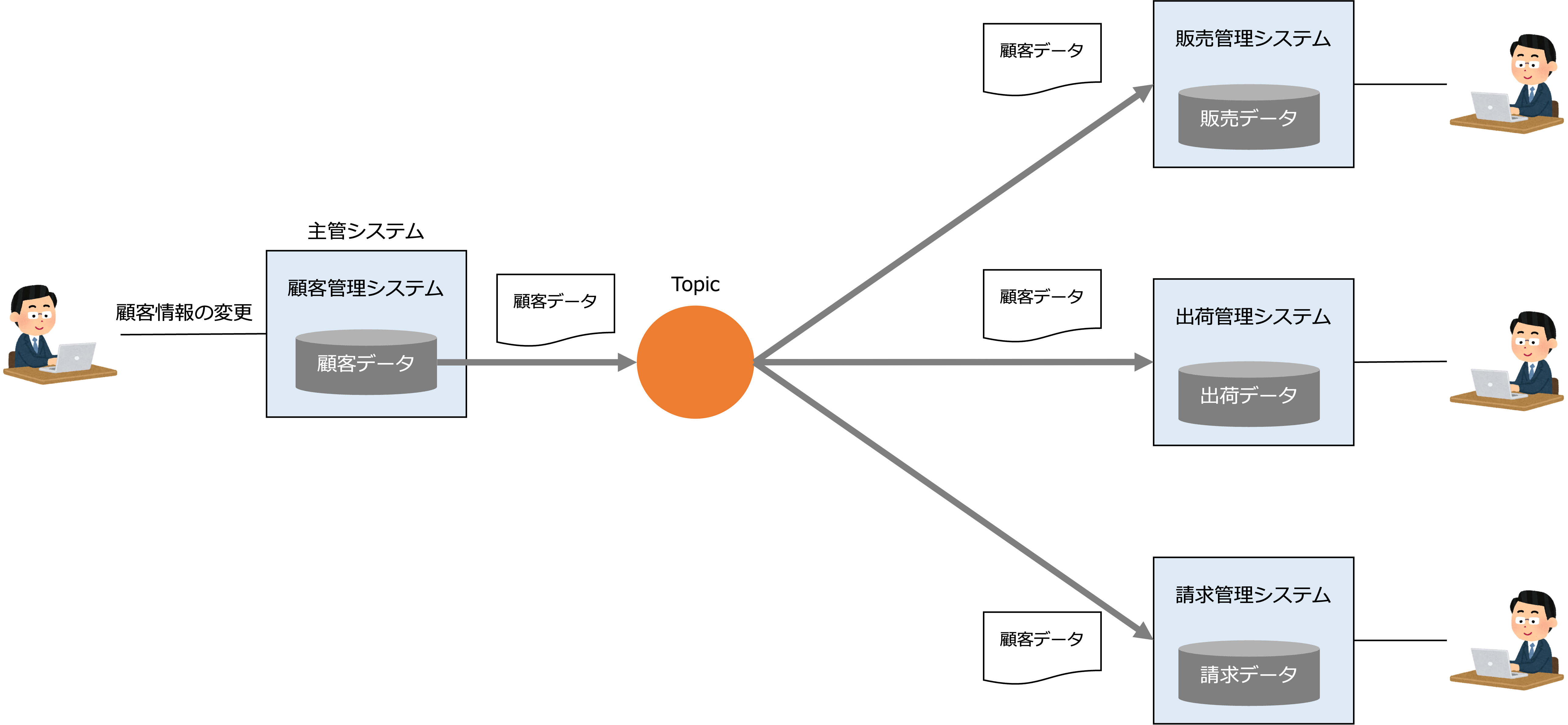
次の図は、顧客情報が更新されるタイミングで、顧客データの主管システムである顧客管理システムから、顧客データが、マスター共有ハブを経由して販売管理システム、出荷管理システム、請求管理システムに移動する例です。
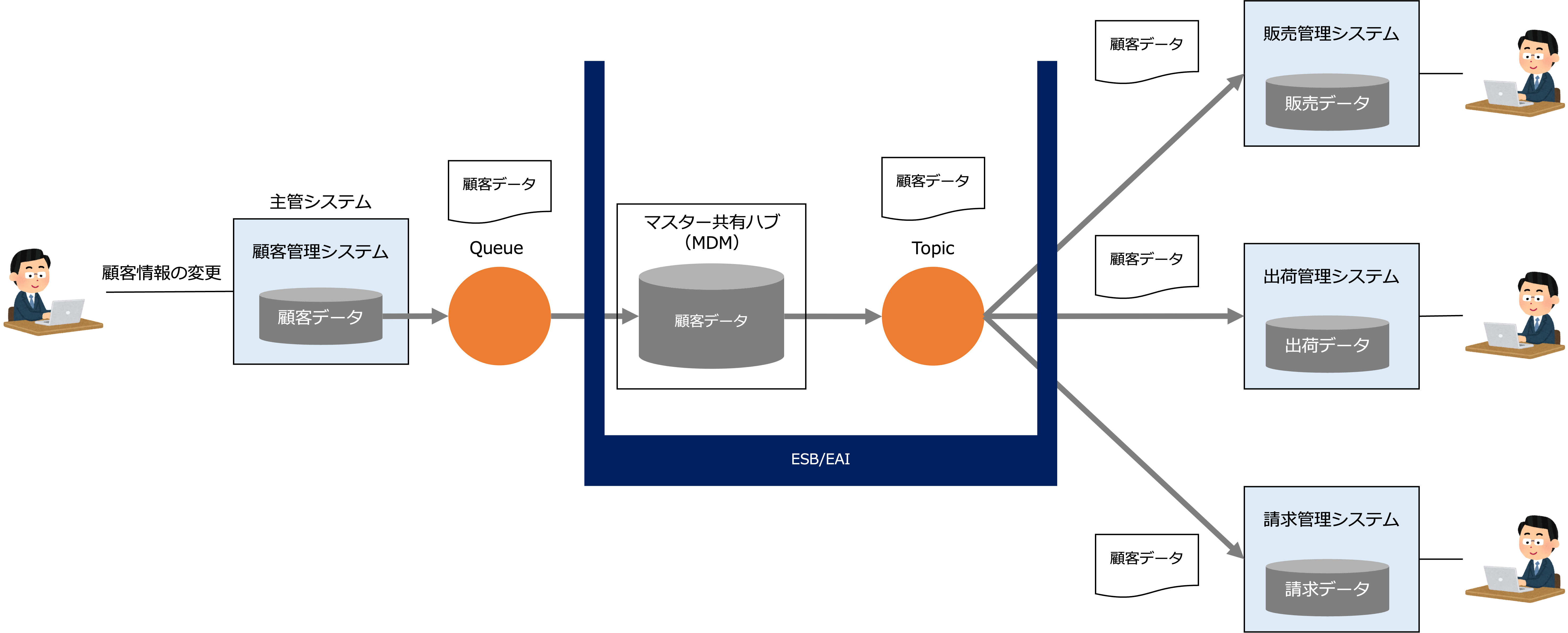
データ連携基盤(アプリケーション基盤)として、ESB/EAIを導入する場合は、データフローに基づいてデータの連携を検討します。
次の図は、受注が登録されるタイミングで、受注データの主管システムである販売管理システムからQueueを経由して、受注データが、出荷管理システムに移動し、出荷の登録のタイミングで、出荷データの主管システムである出荷管理システムからTopicを経由して、出荷データが、請求管理システムと販売管理システムに移動する例です。
販売管理システムでは、出荷データを受けて、受注データのステータスが出荷済に変更されます。
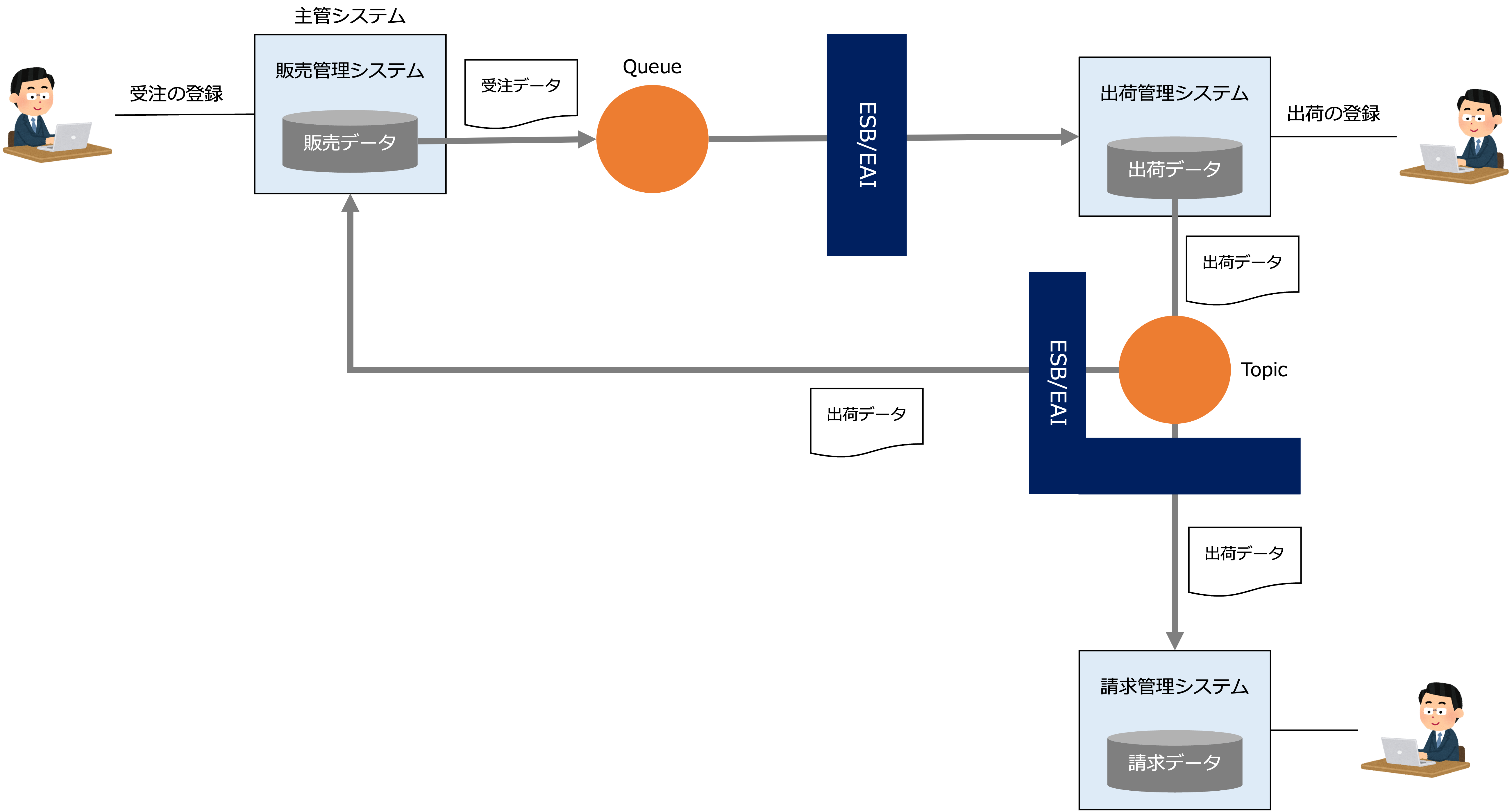
データを連携する場合、即時性が求められない限り、QueueやTopicを介した非同期メッセージングによって、アプリケーション間の依存度を下げて疎結合になるようにします。
データ連携についての詳細は、「アプリケーション統合方式の設計」を参照してください。
データ統合と連携の手順
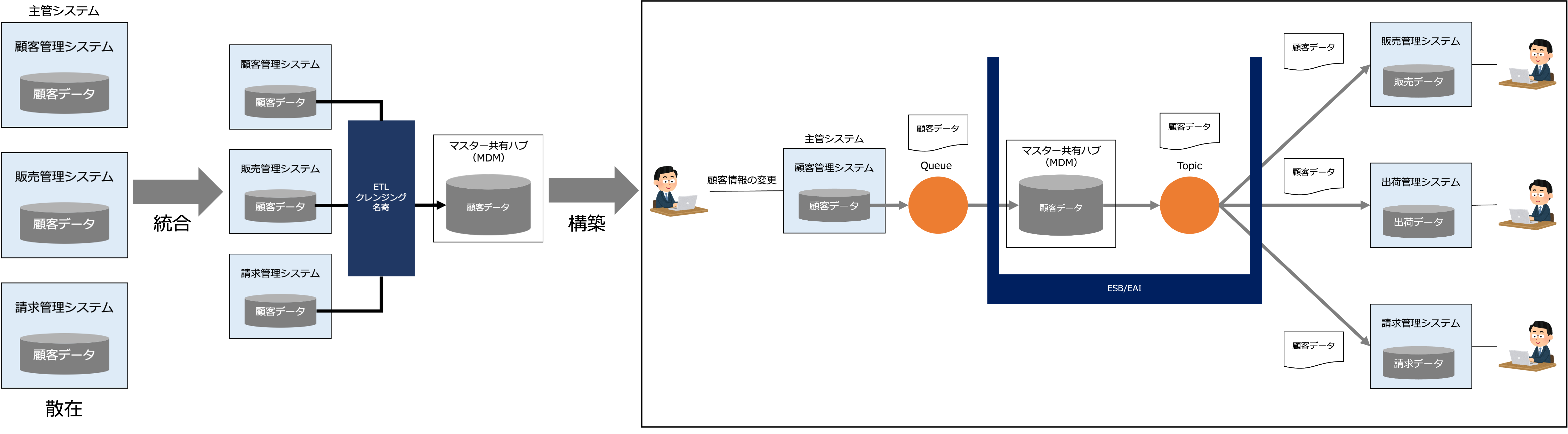
データ統合は、次の図のように、まず、上記データ統合の設計によって明らかになった、散在しているデータをETLによってマスター共有ハブに統合し、その上で、上記データフローの設計で設計したデータフローを構築します。
なお、データを統合するときは、名寄(名前や住所などの統合)やデータのクレンジング(破損または不正確なレコードを検出して修正すること)も行います。
データ品質
データ品質に関するポリシー、役割や組織、管理プロセスを定義し管理します。
データ品質の詳細は、【DMBOKで学ぶ】データ品質を参照してください。
データセキュリティ
データセキュリティに関するポリシー、役割や組織、管理プロセスを定義し管理します。
データセキュリティの詳細は、【DMBOKで学ぶ】データセキュリティを参照してください。
データマネジメント組織
データマネジメント組織は、データマネジメントを実施する職務と監督する職務を分掌し、データマネジメントの妥当性を保証します。
データマネジメント組織は、データマネジメントのビジョンをどう実現するか考えた上で、ジョブに部門を割り当てて設計します。
部門は経営環境の変化に応じて変わりますが、ジョブは不変です。
DMBOKでは、データマネジメント組織を次のように表しています。

- 立法機能
ポリシー、規定、エンタープライズデータアーキテクチャを定義する。 - 司法機能
課題管理と報告。 - 行政機能
データの保護とサービス、行政責任。
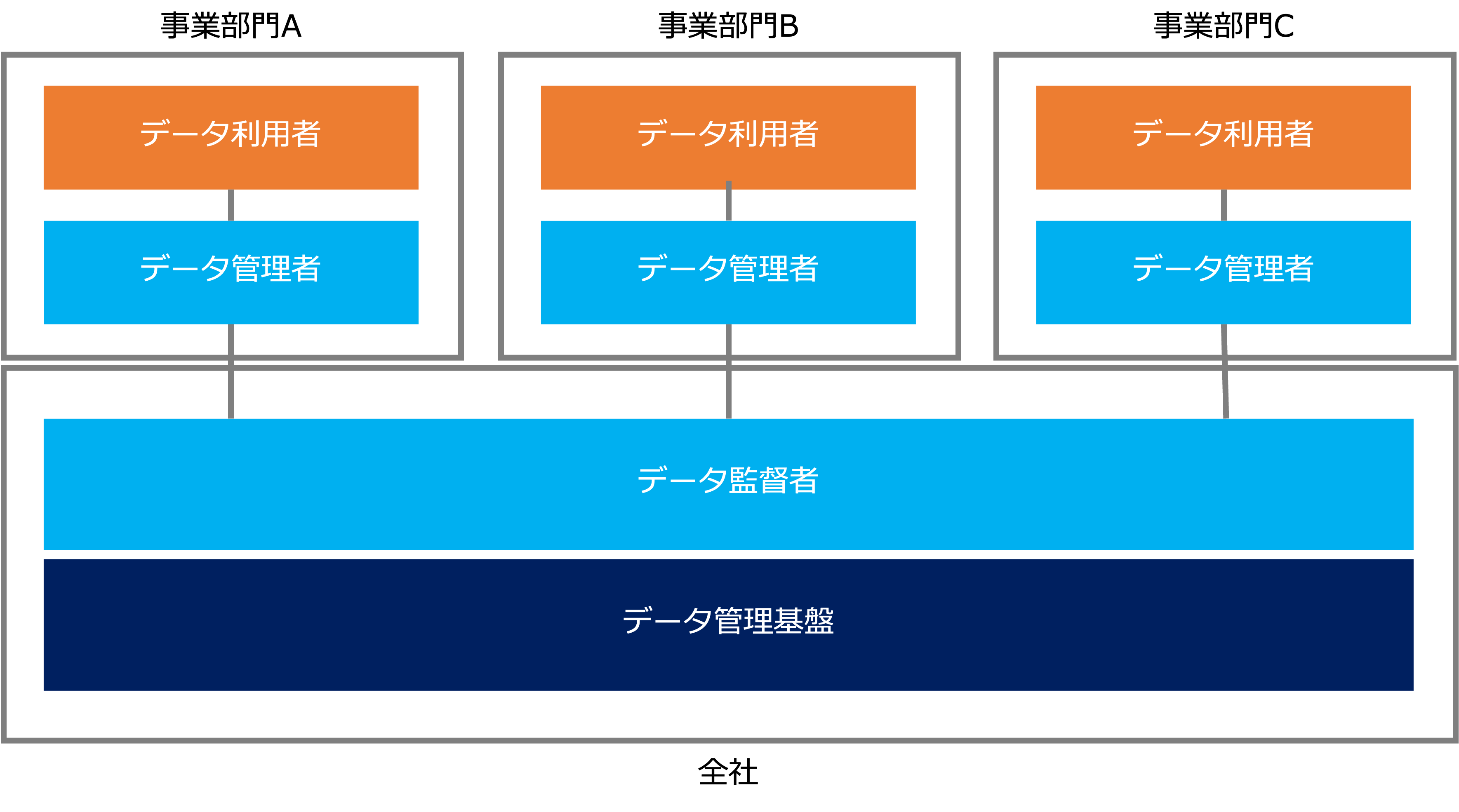
さて、データマネジメントを行う重要なジョブはデータスチュワード、データアーキテクト、データアナリスト(データサイエンティスト)の3つです。
この3つのジョブを総称してデータ管理者と呼びます。
また、データ管理者のタスク実行を監督するジョブをデータ監督者と呼びます。
- データスチュワード
データの生成から強化までのライフサイクルを通して、データの品質、セキュリティ、有効性(経済価値)という観点からデータの資産価値を維持、向上させる役割。
DMBOKでは、データスチュワードのタスクを次のように定義しています。- コアとなるメタデータの作成と管理
- データに関するルールの文書化
- データ品質の問題管理
- データガバナンス運営
- データアーキテクト
データの計画段階で、データアーキテクチャを設計し、アプリケーションのデータ設計・実装結果を検証する役割。 - データアナリスト
データ資産を有効活用して事業の経済価値を上げる役割。
データサイエンティストともいいます。
データアナリストが行うデータ分析には次の3種類があります。- 記述的分析(Descriptive Analytics)
過去に何が起こったかをデータから読み取り説明するための分析。
BI(ビジネスインテリジェンス)は主に記述的分析に適しており、データの収集、整理、ダッシュボードの作成、レポートの生成などによって過去の業績を説明し、トレンドやパターンを可視化します。 - 予測的分析(Predictive Analytics)
将来何が起こるかデータから読み取り予測するための分析。
AI、および、データサイエンスは、予測的分析に適しており、機械学習モデルを使用して未来の出来事を予測し、顧客行動の予測、在庫の需要予測、リスク評価などに活用します。 - 処方的分析(Prescriptive Analytics)
データを分析してビジネス課題を解決する最適な処方を提示するための分析。
AI、および、データサイエンスは、処方的分析にも適しており、最適化アルゴリズムやシミュレーションモデルを使用して、問題に対する最適な対処法を示します。
- 記述的分析(Descriptive Analytics)
ここでは、DMBOKの組織を簡略化してデータマネジメント組織(ジョブの構成)を次のように表します。
メタデータ管理
メタデータをデータカタログとして整備して活用することで、次の点を明確にすることができます。
組織には、
- どのようなデータが存在し
- それが何を表し、どう分類され(データアーキテクチャ)
- どこから来て、組織内をどう移動し活用されるか、またそれに伴いどう成長するか(データリネージュ)
- 誰が使えて、誰が使えないか(データセキュリティ)
- どの程度の品質か(データ品質)
メタデータとして何を定義するかについては、「メタデータの詳細」を参照してください。
メタデータ管理の詳細は、【DMBOKで学ぶ】メタデータ管理を参照してください。
データマネジメントの導入方法
データマネジメント導入サービスを参照してください。
【関連動画】


[…] 前回、データマネジメントについて解説しましたが、データマネジメントを進める上で欠かせないのがデータアーキテクチャです。 今回は、データアーキテクチャについて次の観点で […]
[…] ここでは、データマネジメントプロセスの一環として、データ品質を管理するプロセスを次の順で解説します。 […]
[…] データマネジメントプロセスの「データマネジメント計画の策定」の一環として設計されます。 […]
[…] データマネジメント […]
[…] データマネジメントの実現 […]
[…] 一般的に、データドリブン経営とは、経営判断やビジネス戦略の決定に、データや分析結果を活用することを指しますが、ここでは、企業を 社員一人ひとりがデータを活用して自律的に業務課題を解決することができる状態 に変革することを目指します。 データドリブン経営を実現するためには、IT基盤とコミュニケーション基盤を運営して実現するITマネジメント、アプリケーション基盤を運用して実現するアプリケーションマネジメント、データ基盤を運用して実現するデータマネジメント、BPM基盤を運用して実現するビジネスプロセスマネジメントが必要です。 ビジネスプロセスマネジメントは、継続的に業務改善をするための体系的な手法です。 アプリケーションマネジメントは、DevOpsやマイクロサービスアーキテクチャによって、アプリケーション開発の生産性や保守性を改善します。 なので、業務改善の一環としてアプリケーションの開発や改良が必要な場合、それを速やかに実現します。 なお、COBITやITILは、アプリケーションマネジメントとITマネジメントを合わせたスコープになります。 データドリブン経営は、企業に蓄積されたデータを活用しますが、そのデータの品質が悪いと間違った意思決定をする可能性があります。 企業のデータの品質やセキュリティを継続的に管理する方法がデータマネジメントです。 さて、データドリブン経営を加味した戦略マップの雛形は次のようになります。 さらに、 […]
[…] なお、企業全体のデータは、データ基盤によって管理されます。 また […]
[…] 5;スを特定します。これは、データマネジメントとして管理されます。 […]
[…] 2371;とができますが、多次元分析は、記述的分析(Descriptive Analytics)になります。 […]
[…] ;セキュリティを管理するデータマネジメントの導入は重要です。 特に […]
[…] アプリケーション基盤 […]
[…] データマネジメント ITサービスマネジメント […]
[…] データライフサイクルの計画フェーズでは、まず、各企業において、企業価値最大化に寄与する(経済性の高い)データは具体的に何か明確にし、何のためにデータマネジメントを行うのか、データマネジメントの目的を明確にする必要があります。 次に、いつまでに、データマネジメントの成熟度レベルをどの段階にしたいのか、データマネジメントのビジョンを設定します。 その上で、データマネジメントシステム構築計画、データマネジメントシステム運用計画を策定します。 データマネジメントの計画は、データマネジメント組織がデータマネジメントプロセスに従って実行します。 […]
[…] データマネジメントプロセスの「データ設計の検証」活動で、データ管理実行者は、定義されたエンティティとデータ項目をビジネスメタデータとして登録します。 ここで、データ品質 […]